数据结构(三):栈、队列和数组
文章目录
- 第三章 栈、队列和数组
- 一、栈(Stack)
-
- (一)栈的定义
- (二)栈的基本操作
- (三)栈的常考题型
-
-
- ※卡特兰数
-
- 二、顺序栈
-
- (一)顺序栈的定义
- (二)初始化操作
- (三)进栈操作
- (四)出栈操作
- (五)读栈顶元素操作
- (六)另一种操作方式
- (七)共享栈
- (八)销毁操作
- 三、链栈
-
- (一)链栈的定义
- (二)链栈的实现
- ※※※自己动手写一遍
- 四、队列(Queue)
-
- (一)队列的定义
- (二)队列的基本操作
- 五、队列——顺序实现
-
- (一)定义
- (二)初始化
- (三)入队操作
- (四)出队操作
- (五)判断队列已满/已空
- (六)队尾指针指向队尾元素
- 六、队列——链式实现(链队列)
-
- (一)定义
- (二)初始化
-
- 1.带头结点
- 2.不带头结点
- (三)入队
-
- 1.带头结点
- 2.不带头结点
- (四)出队
-
- 1.带头结点
- 2.不带头结点
- (五)队列满的条件(不会满)
- (六)队列的长度
- 七、双端队列
-
- (一)双端队列的定义
- (二)考点
- 八、栈和队列的应用
-
- (一)栈的应用——括号匹配问题
-
- 1.问题分析
- 2.算法实现
- (二)栈的应用——表达式求值
-
- 1.概述
- 2.大家熟悉的算术表达式
- 3.中缀、后缀、前缀表达式
- 4.中缀表达式转后缀表达式(手算)
- 5.后缀表达式的计算(手算)
- 6.后缀表达式的计算(机算)
- 7.中缀表达式转前缀表达式(手算)
- 8.前缀表达式的计算
- 9.※中缀表达式转后缀表达式(机算)
- 10.中缀表达式的计算(用栈实现)
- (三)栈的应用——递归
-
- 1.普通函数调用背后的过程
- 2.栈在递归中的应用
- (四)队列应用——树的层次遍历
- (五)队列应用——图的广度优先遍历
- (六)队列在操作系统中的应用
- 九、矩阵的压缩存储
-
- (一)一维数组
- (二)二维数组
- (三)普通矩阵的存储
- (四)对称矩阵的压缩存储
- (五)三角矩阵的压缩存储
- (六)三对角矩阵的压缩存储
- (七)稀疏矩阵的压缩存储
第三章 栈、队列和数组
一、栈(Stack)
(一)栈的定义
栈也是一种线性表,只不过对于普通的线性表来说,当我们插入或删除某结点时,可以对任意结点进行插入或删除。但是对于栈这种数据结构来说,我们会限制它的插入和删除操作,插入和删除操作只能在线性表的一端进行。例如我们进行插入操作,只能在表尾的位置进行,而不能在其他的位置进行插入。同样地,如果要删除某数据元素,也只能从表尾进行依次的删除。
就像烤串,往上串的时候,和往下吃的时候的操作。就是栈的插入、删除操作。
重要术语:栈顶、栈底、空栈。
- 空栈:栈里没有存任何数据元素,相当于线性表的空表。
- 栈顶:允许插入和删除的一端。
- 栈底:不允许插入和删除的一端。
特点:后进先出。(Last In First Out,LIFO)
(二)栈的基本操作
创、销:
InitStack(&S):初始化栈。构造一个空栈S,分配内存空间。
DestroyStack(&S):销毁栈。销毁并释放栈S所占用的内存空间。
增、删:
Push(&S, x):进栈,若栈S未满,则将x加入使之成为新栈顶。
Pop(&S, &x):出栈,若栈S非空,则弹出栈顶元素,并用x返回。
查(栈的使用场景中大多只访问栈顶元素):
GetTop(S, &x):读栈顶元素。若栈S非空,则用x返回栈顶元素。
其他常用操作:
StackEmpty(S):判断一个栈S是否为空。若为空则返回true,否则返回false。
(三)栈的常考题型
给出进栈顺序,如a->b->c->d->e。
问:有哪些合法的出栈顺序?
如果已经进栈完毕,则出栈顺序只能为e、d、c、b、a。
但是,如果出栈操作和进栈操作穿插着进行的话,那么会有很多不同种合法的出栈顺序。比如a进栈后,a出栈;接着,b、c、d依次进栈,d、c出栈;然后e进栈,e、b出栈。
※卡特兰数
对于此类题,有一个一般结论:
n 个 不 同 元 素 进 栈 , 出 栈 元 素 不 同 排 列 的 个 数 为 1 n + 1 C 2 n n 。 n个不同元素进栈,出栈元素不同排列的个数为\frac {1}{n+1} C^n_{2n}。 n个不同元素进栈,出栈元素不同排列的个数为n+11C2nn。
上述公式称为卡特兰数,可以使用数学证明。所以,如果像上面那样有五个元素进栈,那么所有合法的出栈顺序有
1 5 + 1 C 10 5 = 1 6 ∗ 10 ∗ 9 ∗ 8 ∗ 7 ∗ 6 5 ∗ 4 ∗ 3 ∗ 2 ∗ 1 = 42 \frac {1}{5+1}C^5_{10} = \frac{1}{6} * \frac {10*9*8*7*6}{5*4*3*2*1} = 42 5+11C105=61∗5∗4∗3∗2∗110∗9∗8∗7∗6=42
可见,即使只有5个元素进栈,合法的出栈顺序就有42种,就很多了。所以考试题基本不会让你全部写出所有的,而是以选择题的形式让你选出一个合法的出栈顺序。
二、顺序栈
用顺序存储方式实现的栈。(和顺序表是很类似的)
基本操作:创、销、增、删、改、查。
- 创(初始化)
- 增(进栈)
- 删(出栈)
- 查(获取栈顶元素)
- 判空、判满
(一)顺序栈的定义
#define MaxSize 10 //定义栈中元素的最大个数
typedef struct {
ElemType data[MaxSize]; //静态数组存放栈中元素
int top; //栈顶指针,记录的是数组的下标
}SqStack;
void testStack(){
SqStack S; //声明一个顺序栈
//......
}
(二)初始化操作
//初始化栈
void InitStack(SqStack &S) {
S.top = -1; //初始化栈顶指针
}
由于栈空的时候,数组中是没有任何元素的。如果要让栈顶指针指向0,显然是不合适的。所以空栈让栈顶指针的值为-1。
因此,判断是否栈空时,只需要判断它的栈顶指针top是否等于-1就可以,如下。
//判断栈空
bool StackEmpty(SqStack S) {
if(S.top == -1) return true; //栈空
else return false; //非空
}
(三)进栈操作
//新元素入栈
bool Push(SqStack &S, ElemType x) {
if(S.top == MaxSize-1) return false; //栈满,报错
S.top = S.top + 1; //指针先加1
S.data[S.top] = x; //新元素入栈
return true;
}
或者写的更简洁一点,如下。
//新元素入栈
bool Push(SqStack &S, ElemType x) {
if(S.top == MaxSize-1) return false; //栈满,报错
S.data[++S.top] = x; //合并两句
return true;
}
(四)出栈操作
//出栈操作
bool Pop(SqStack &S, ElemType &x) {
if(S.top == -1) return false; //栈空,报错
x = S.data[S.top]; //栈顶元素先出栈
S.top = S.top - 1; //指针再减1
return true;
}
同上文,此处也可以将其中两句合并成一句更简洁的写法,如下。
//出栈操作
bool Pop(SqStack &S, ElemType &x) {
if(S.top == -1) return false; //栈空,报错
x = S.data[S.top--]; //合并两句
return true;
}
(五)读栈顶元素操作
//读栈顶元素
bool GetTop(SqStack S, ElemType &x) {
if(S.top == -1) return false; //栈空,报错
x = S.data[S.top]; //x记录栈顶元素
return true;
}
(六)另一种操作方式
初始化时,令栈顶指针指向0,而不是-1。
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int top;
}SqStack;
//初始化栈
void InitStack(SqStack &S) {
S.top = 0; //初始指向0
}
//判断栈空
bool StackEmpty(SqStack S) {
if(S.top == 0) return true;
else return false;
}
进栈、出栈时。
//新元素入栈
bool Push(SqStack &S, ElemType x) {
if(S.top == MaxSize) return false; //判断栈满的条件不同
S.data[S.top++] = x; //赋值操作与指针移动操作顺序不同
return true;
}
//出栈操作
bool Pop(SqStack &S, ElemType &x) {
if(S.top == 0) return false;
x = S.data[--S.top];
return true;
}
(七)共享栈
顺序栈的缺点:栈的大小不可变。
- 可以用链式存储的方式进行存储。
- 也可以在初始化的时候就声明一个较大的存储空间。
但我们知道,若一开始就申请较大空间的话,会造成空间的浪费。但是,我们可以通过共享栈的方式,来提高这一大片内存空间的利用率。
共享栈的意思就是,两个栈共享同一片空间。
我们可以设置两个栈顶指针。
#define MaxSize 10 //定义栈中元素的最大个数
typedef struct {
ElemType data[MaxSize]; //静态数组存放栈中元素
int top0; //0号栈栈顶指针
int top1; //1号栈栈顶指针
}ShStack;
//初始化栈
void InitStack(ShStack &S) {
S.top0 = -1;
S.top1 = MaxSize;
}
如果要往0号栈存放数据元素的话,是由下到上依次递增的;
如果要往1号栈存放数据元素的话,是由上到下依次递减的。
这两个栈,从逻辑上来说是两个不同的栈,但是在物理上,它们又共享同一片存储空间。这样就提高了空间利用率。
共享栈也是会满的。判断共享栈是否满了的条件,就是看top0 + 1 == top1。
(八)销毁操作
销毁——清空、回收。
对于本节的顺序栈,它是使用静态数组存放数据元素。我们要清空它,只需要将S.top置于-1即可。因为并没有使用malloc申请动态存储空间。只是以变量声明的方式,那么它会在函数运行结束之后被系统自动回收。
三、链栈
用链式存储方式实现的栈。
基本操作:
- 创(初始化)
- 增(进栈)
- 删(出栈)
- 查(获取栈顶元素)
- 判空、判满
回顾:头插法建立单链表。
本质:对单链表的头结点进行后插操作。
那么这实际上就等同于链栈的进栈操作。
同样,对头结点进行后删操作。
那这种有限制的删除操作,也就是链栈的出栈操作了。
我们只要将头结点的那端看作链栈的栈顶的一端即可。
(一)链栈的定义
和单链表的定义几乎没有什么区别。
typedef struct Linknode {
ElemType data; //数据域
struct Linknode *next; //指针域
}*LiStack;
进栈和出栈操作就对应于单链表的插入和删除操作(只在头结点那一端进行)。
那么对于单链表在头结点处的插入删除,我们在第二章已经讲的很详细了,这里就不再赘述。
和单链表类似。对于链栈,我们也可以实现带头结点的版本,和不带头结点的版本,道理同单链表是一样的。
(二)链栈的实现
两种实现方式:
- 带头结点
- 不带头结点(推荐)
重要基本操作:
- 创(初始化)
- 增(进栈)
- 删(出栈)
- 查(获取栈顶元素)
- 判空、判满。
※※※自己动手写一遍
四、队列(Queue)
(一)队列的定义
队列也是一种操作受限的线性表。
- 栈(Stack)是只允许**在一端进行插入(入栈)或删除(出栈)**操作的线性表。
- 队列(Queue)是只允许**在一端进行插入(入队),在另一端删除(出队)**的线性表。
队列,和它的名字一样,像是一条排队的队列一样。若添加,则插入队尾;若删除,则由队头离开。
特点:先进先出(First In First Out,FIFO)。
重要术语:队头、队尾、空队列
- 空队列:略。
- 队尾:允许插入的一端。此时,队列中最靠近队尾的一个元素叫作队尾元素。
- 队头:允许删除的一端。相应的,最靠近队头的一个元素叫作队头元素。
(二)队列的基本操作
创、销:
InitQueue(&Q):初始化队列,构造一个空队列Q。
DestroyQueue(&Q):销毁队列。销毁并释放队列Q所占用的内存空间。
增、删:
EnQueue(&Q, x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&Q, &x):出队,若队列Q非空,删除队头元素,并用x返回。
查(队列的使用场景中,大多只访问队头元素):
GetHead(Q, &x):读队头元素,若队列Q非空,则将对头元素赋值给x。
其他常用操作:
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
五、队列——顺序实现
用顺序存储实现队列。
基本操作:
- 创(初始化)
- 增(入队)
- 删(出队)
- 查(获取队头元素)
- 判空、判满(进行增/删/查操作前的必要判断)
(一)定义
队列本质上也只是一个操作受限的线性表,所以其定义和栈是类似的,只是多了一个指针。
#define MaxSize 10
typedef struct {
ElemType data[MaxSize]; //用静态数组存放队列元素
int front,rear; //队头指针和队尾指针
}SqQueue;
void testQueue(){
SqQueue Q; //声明一个队列(顺序存储)
//......
}
(二)初始化
我们可以规定,让队头指针指向对头元素;让队尾指针指向队尾元素的后一个位置(接下来应该插入数据元素的位置)。
那么在初始化的时候,我们可以令队头、队尾指针均指向0。
//初始化队列
void InitQueue(SqQueue &Q) {
//初始时,队头、队尾指针指向0
Q.rear = 0;
Q.front = 0;
}
void testQueue(){
//声明一个队列(顺序存储)
SqQueue Q;
InitQueue(Q);
//......
}
那么,在判断队列是否为空的时候,只需判断队头和队尾指针指向是否相等即可。
//判断队列是否为空
bool QueueEmpty(SqQueue Q) {
if(Q.rear == Q.front) return true;
else return false;
}
(三)入队操作
把这一次要插入的数据元素,把它放到队尾指针所指向的位置。
把队尾指针加1。
//入队
bool EnQueue(SqQueue &Q, ElemType x) {
if(队列已满) return false; //队满则报错
Q.data[Q.rear] = x; //将x插入队尾
Q.rear = Q.rear + 1; //队尾指针后移
return true;
}
那么我们是否可以认为,队列已满的条件,就是rear == MaxSize呢?
并不是这样。
因为,在rear == MaxSize的情况下,若队头出队了一些元素,则队列显然不满。但rear仍然是等于MaxSize的。
同时,接下来的新元素,是要插入到队头元素之前的空位当中的。
那么怎样让队尾指针指向接下来要插入的队头元素前的空位处呢?
只需进行一个取余操作即可,如下。
//入队
bool EnQueue(SqQueue &Q, ElemType x) {
if(队列已满) return false; //队满则报错
Q.data[Q.rear] = x; //将x插入队尾
Q.rear = (Q.rear + 1) % MaxSize; //队尾指针加1取模
return true;
}
例如,MaxSize = 10时,即数组下标为0-9。
此时,若data[9]处入队一元素,其入队后,该队列队尾指针rear = rear + 1变为10,之后进行取余,即10 % 10 = 0,则rear = 0。
例如a % b,也可以表示为a MOD b。
其取余运算的结果只可能是{0, 1, 2, …, b-1}。
模运算实际上是将无限的整数域映射到了有限的整数集合{0, 1, 2, … ,b-1}上。
这样一来,就把我们的一个线状的存储空间,在逻辑上变成了一个环状的存储空间。所以用这种方式实现的队列称为循环队列。
那么此时就可以知道,队列已满的条件为:
队尾指针的下一个位置是队头,即(Q.rear + 1) % MaxSize == Q.front。
此处,有些人会认为。队尾指针指向的就是“接下来应该插入元素的位置”,也就是队尾指针指向的位置是一个空闲空间。那么为什么队尾指针所指向的位置的下一个是队头时,就判满了呢?不是还有一个空间空间吗?如果“真正满了”的话,应该是队尾指针指向队头指针呀。
要知道,队尾指针和队头指针相等,那是我们在初始化队列的时候,让队头指针和队尾指针指向同一个位置的。此外,我们也根据队尾指针与队头指针是否指向同一个位置,来判断队列是否为空。
这样就没办法。所以我们必须牺牲一个存储单元。来将判满与判空区分开来。
(四)出队操作
//出队(删除一个队头元素,并用x返回)
bool DeQueue(SqQueue &Q, ElemType &x) {
if(Q.rear == Q.front) return false; //队空则报错
x = Q.data[Q.front];
Q.front = (Q.front + 1) % MaxSize;
return true;
}
//获得队头元素的值,用x返回
bool GetHead(SqQueue Q, ElemType &x) {
if(Q.rear == Q.front) return false;
x = Q.data[Q.front];
return true;
}
(五)判断队列已满/已空
方案一:按照上述介绍的方案,即“牺牲一个存储空间以区分队满、队空”:
- 队列已满的条件:队尾指针的再下一个位置是队头,即
(Q.rear + 1) % MaxSize == Q.front - 队空条件:
Q.rear == Q.front - 队列元素的个数:
(rear + MaxSize - front) % MaxSize
方案二:但有时在题目中,不允许牺牲那一个存储空间,因此我们要另想一种方案
在队列的结构体类型中,额外定义一个属性
int size;,用来表示队列当前长度。#define MaxSize 10 typedef struct { ElemType data[MaxSize]; int front, rear; int size; //队列当前长度 }SqQueue;刚开始我们将size设为0,之后每次插入一个元素,就size++,每删除一个元素,就size–。
- 队满条件:
size == MaxSize - 队空条件:
size == 0
方案三:
在队列的结构类型中,定义一个
int tag;,当tag为0的时候,表示最近一次执行的操作是删除操作;当tag为1的时候,表示最近一次执行的操作是插入操作。#define MaxSize 10 typedef struct { ElemType data[MaxSize]; int front, rear; int tag; //最近一次进行的是删除还是插入。初始化时令tag=0 }SqQueue;那么,也就是每次删除操作后,都将tag置为0;每次插入操作后,都将tag置为1。
- 只有删除操作,才可能导致队空。
- 只有插入操作,才可能导致队满。
因此,当我们将最后一个空位插入元素后,并置tag为1了。这样一来,rear虽然和front相等了,但是也能够和队空的状态区分开来。
- 队满条件:
front == rear && tag == 1 - 队空条件:
front == rear && tag == 0
(六)队尾指针指向队尾元素
以上所有内容,均为:队头指针指向队头元素,队尾指针指向队尾元素的后一个位置(下一个应该插入的位置)。
那么,有些情况下,是队尾指针指向队尾元素。那么这种情况,在入队操作、出队操作方面会与我们上述介绍的内容有所区别。
区别如下:
若队尾指针指向队尾元素,而不是队尾元素的后一个位置,那么其入队、出队操作如下。
{
Q.rear = (Q.rear + 1) % MaxSize;
Q.data[Q.rear] = x;
}
即,入队时应该先移动队尾指针,再插入数据元素。
出队操作,由于队头指针指向的也是队头元素,所以出队操作没有变化。
此外,在初始化的时候,我们就不应该让rear = front = 0了。而是应该让front = 0,而rear指向front的前一个位置,即第n-1号位置(假设队列长度为n)。
同时,其判空操作如下。
{
(Q.rear + 1) % MaxSize == Q.front;
}
同时,其判满操作,也会由于之前同样的原因而导致与判空混淆。处理方案和之前的处理方案是一个思路。
- 方案一:牺牲一个存储单元。
- 方案二:增加辅助变量(size/tag)。
※此处可以自己动手写一下。
六、队列——链式实现(链队列)
用链式存储实现队列:
- 带头结点
- 不带头结点
基本操作:
- 创(初始化)
- 增(入队)
- 删(出队)
- 查(获取队头元素)
- 判空、判满(进行增/删/查操作前的必要判断)
其实就是单链表的一个阉割版。
(一)定义
typedef struct LinkNode { //链式队列结点
ElemType data;
struct LinkNode *next;
}LinkNode;
typedef struct { //链式队列
LinkNode *front, *rear; //队列的队头和队尾指针
}LinkQueue;
我们在学习单链表的时候,我们要标记一个单链表,其实只需要保存一个头指针L就可以了,因为后续的所有结点都能够由这个头指针往后依次地找到。
但是如果我们只标记一个头结点指针的话,当我们想要在单链表尾部进行插入操作的时候,我们只能从头结点开始依次往后直到找到最后一个结点,然后才能进行插入操作。这样的时间复杂度就有点大了。而对于队列来说,由于我们每次插入元素都只能在表尾的地方进行插入,因此我们可以用一个专门的尾指针指向最后一个结点,这样就不必每次从头结点开始寻找。
因此我们定义一个链式队列的时候,既需要保存它队头的指针,也需要保存它队尾的指针。
分为带头结点和不带头结点两种。
(二)初始化
1.带头结点
//初始化队列(带头结点)
void InitQueue(LinkQueue &Q) {
//初始时 front、rear 都指向头结点
Q.front = Q.rear = (LinkNode *)malloc(sizeof(LinkNode));
Q.front->next = NULL;
}
void testLinkQueue(){
LinkQueue Q; //声明一个队列
InitQueue(Q); //初始化队列
//......
}
//判断队列是否为空
bool IsEmpty(LinkQueue Q){
if(Q.front == Q.rear) return true;
else return false;
}
2.不带头结点
//初始化队列(不带头结点)
void InitQueue(LinkQueue &Q) {
//初始时front、rear都指向NULL
Q.front = NULL;
Q.rear = NULL;
}
//判断队列是否为空(不带头结点)
bool IsEmpty(LinkQueue Q) {
if(Q.front == NULL) return true;
else return false;
}
(三)入队
1.带头结点
//新元素入队(带头结点)
void EnQueue(LinkQueue &Q, ElemType x) {
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
Q.rear->next = s; //新结点插入到rear之后
Q.rear = s; //修改队尾指针
}
一个新的数据元素想要入队,首先这个数据元素要包含在一个结点当中。因此要申请一个新结点s。接下来,向队尾进行后插即可。
2.不带头结点
//新元素入队(不带头结点)
void EnQueue(LinkQueue &Q, ElemType x) {
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
if(Q.front == NULL){ //在空队列中插入第一个元素
Q.front = s; //修改队头队尾指针
Q.rear = s;
} else{
Q.rear->next = s; //新结点插入到rear结点之后
Q.rear = s; //修改rear指针
}
}
注意第一个元素入队时的特殊情况。
(四)出队
1.带头结点
//队头元素出队(带头结点)
bool DeQueue(LinkQueue &Q, ElemType &x){
if(Q.front == Q.rear) return false; //空队列无法出队
LinkNode *p = Q.front->next;
x = p->data; //用变量x返回队头元素
Q.front->next = p->next; //修改头结点的next指针
if(Q.rear == p) { //此次是最后一个结点出队
Q.rear = Q.front; //修改rear指针
}
free(p); //释放结点空间
return true;
}
需要注意的是,如果出队的结点是最后一个结点,也就是队尾指针rear指向的结点。那么就不能直接将其释放了。而要先修改rear指针,使其指向队头指针front(同时rear == front自然也是空队了),然后再释放结点。否则直接将rear指针指向的内存空间释放掉,就会出现问题。
2.不带头结点
//队头元素出队(不带头结点)
bool DeQueue(LinkQueue &Q, ElemType &x){
if(Q.front == NULL) return false; //空队
LinkNode *p = Q.front; //p指向此次出队的结点
x = p->data; //用变量x返回队头元素
Q.front = p->next; //修改front指针
if(Q.rear == p) { //此次是最后一个结点出队
Q.front = NULL; //front指向NULL
Q.rear = NULL; //rear指向NULL
}
free(p); //释放结点空间
return true;
}
同样地,若出队的是最后一个结点,也要将front和rear均指向NULL,恢复成空队的状态。
注意最后一个元素出队时的情况。
(五)队列满的条件(不会满)
之前顺序存储实现的队列,由于是用静态数组分配的,其空间是有限的、不可拓展的,所以其最大空间被耗尽时队满。
而此处用链式存储实现的队列,它的容量是可以扩展的,一般不会队满,除非内存不足。
因此,在顺序存储的队列当中,我们花了很多办法去判断队列是否已满;而在链式存储实现的队列当中,我们一般不用关心已满的问题。
(六)队列的长度
只能从队头结点开始依次往后遍历,统计出来到底有多少个结点。
那么,如果你的队列长度这个信息,是你需要经常的、频繁的访问到的话,其实你可以在队列的结构类型中增加一个int length;的额外变量,用来专门记录当前队列到底有多少个元素。
数据结构不是一些教条化的规定。而是寻求解决问题的手段,你的实际问题需要处理哪些数据,就因地制宜的、灵活的添加一些你需要的东西。
课程中按照某些方法来讲,是因为那些方法是较核心的,不代表就要局限于那些讲述的方法。
七、双端队列
(一)双端队列的定义
双端队列也是一种操作受限的线性表。
- 栈:只允许从一端插入和删除的线性表
- 队列:只允许从一端插入、另一端删除的线性表
- 双端队列:只允许从两端插入、两端删除的线性表
若对于一个双端队列,我只使用其中一端的插入、删除操作,那么我的使用效果就等同于使用一个栈。
也就是说,栈能够实现的功能,双端队列一定能实现。
队列同理。
介于队列和双端队列之间,或者说是由双端队列引申出的两种特殊的双端队列:
- 输入受限的双端队列:只允许从一端插入、两端删除的线性表
- 输出受限的双端队列:只允许从两端插入、一端删除的线性表
双端队列也可以说是队列的一个变种。类似于栈的变种——共享栈。
(二)考点
此处双端队列比较喜欢考察的考点,就是判断输出序列的合法性。(类似于栈那里的考点)
例如:
若数据元素输入序列为1, 2, 3, 4,则哪些输出序列是合法的,哪些是非法的?
首先,对于1,2,3,4这四个数字,其全部不同的排列组合
A 4 4 = 4 ! = 24 A^4_4 = 4! = 24 A44=4!=24
共有24种。逐个分析。(一般也是选择题了)由于栈能实现的功能,双端队列一定能够实现。因此,栈能够实现的合法序列,也一定是双端队列能实现的合法序列。
根据可特兰数公式可知,栈的合法序列
1 n + 1 C 2 n n = 1 4 + 1 C 8 4 = 14 \frac {1}{n+1}C^n_{2n} = \frac{1}{4+1}C^4_8 = 14 n+11C2nn=4+11C84=14
共有14种。输入受限的双端队列的合法序列?
输出受限的双端队列的合法序列?
关键思路:
拿着选项给你的序列,认真分析其顺序的合法性,是没问题的。
但是可以有更快的思路。某一个元素若要出栈,则说明入栈顺序在其之前的元素已经入栈过了,那么就可以根据这一点进行一些排除。
例如,入栈顺序为1,2,3,4。
对于出栈顺序为3,x, x, x的序列来说,除了认真的分析以外。
还可以直接这样判断:由于3是第一个出栈的,则说明1、2已经按照1在前、2在后的顺序进栈过了。则1和2若要出栈,从出栈顺序来说,2必然在1之前。
那么,出栈序列像:3,1,4,2或3,1,2,4这种的,可直接排除掉。
八、栈和队列的应用
(一)栈的应用——括号匹配问题
1.问题分析
在我们写代码的过程中,不论是大括号、小括号,还是中括号,它们总是成双成对的出现的。
我们如果只写了左括号,而没有写与它对应的右括号,那么编辑器就会检测出来错误。
此外,左括号、右括号除了在数量上要匹配以外,在形状上也要匹配。
例如:
( ( ( ( ) ) ) ) (((()))) (((())))① ② ③ ④ ④ ③ ② ① ①②③④④③②① ①②③④④③②①
从我们人脑的角度来看,一眼就会看出,中间有个对称轴,两边依次是一组组匹配的括号。
但是从计算机的角度来思考,它应该是从左往右依次遍历,进行处理的。因此,最后出现的左括号(即④号),是将会最先被左括号所匹配的。
因此,不难想到,我们用栈来实现它,是比较契合的。因为栈具有后进先出(LIFO)的特性。
再例如:
( ( ( ) ) ( ) ) ((())()) ((())())① ② ③ ③ ② ④ ④ ① 总 之 , 每 出 现 一 个 右 括 号 , 就 “ ” ①②③③②④④①总之,每出现一个右括号,就“” ①②③③②④④①总之,每出现一个右括号,就“”
总之,每出现一个右括号,就“消耗”(出栈)一个左括号。
即,遇到左括号就入栈,而遇到一个右括号的时候,就将栈顶的一个左括号出栈,并在出栈后检验其形状是否匹配。
一些不匹配的情形:
- 若左括号出栈后,与当前遍历到的右括号形状不匹配,则说明这一串括号是非法的,再之后的也不用继续检验了。(左右括号不匹配)
- 若遇到右括号时,将要把栈顶左括号出栈,但是栈为空,则也说明这一串括号是非法的。(右括号单身)
- 若所有右括号全部遍历完毕且形状能够匹配,而栈中还有剩余的左括号,则也说明这一串括号是非法的。(左括号单身)
2.算法实现
#define MaxSize 10 //定义栈中元素的最大个数
typedef struct {
char data[MaxSize]; //静态数组存放栈中元素
int top; //栈顶指针
}SqStack;
//初始化栈
void InitStack(SqStack &S);
//判断栈是否为空
bool StackEmpty(SqStack S);
//新元素入栈
bool Push(SqStack &S, char x);
//栈顶元素出栈,用x返回
bool Pop(SqStack &S, char &x);
bool bracketCheck(char str[], int length) {
SqStack S;
InitStack(S); //初始化一个栈
for(int i=0;i<length;i++) {
if(str[i] == '(' || str[i] == '[' || str[i] == '{'){
Push(S, str[i]); //扫描到左括号,入栈
} else{
if(StackEmpty(S)){
return false; //若扫描到右括号,但栈空,则失败
}
char topElem;
Pop(S, topElem); //栈顶元素出栈
if(str[i] == ')' && topElem != '(') return false;
if(str[i] == ']' && topElem != '[') return false;
if(str[i] == '}' && topElem != '{') return false;
}
}
return StackEmpty(S); //若所有括号匹配完毕且合法后,栈空,则说明全部成功匹配完毕
}
注意一个小问题:
由于我们要写的是括号匹配的算法实现,使用栈这种数据结构。
关键是要说明其中通过栈进行括号匹配的算法逻辑。
那么其中,栈的初始化、判空、入栈、出栈等操作,就可以不写详细细节,而直接使用。但是还是要简要声明操作函数的接口。用注释讲明其大概作用。
这种方法是用顺序存储的方式,有可能存满。其实实际开发的时候还是使用链栈为好。但是在考试的时候,使用顺序栈去写会更简单,也没什么问题。
(二)栈的应用——表达式求值
1.概述
(1)三种算术表达式
- 中缀表达式
- 后缀表达式
- 前缀表达式
(2)后缀表达式相关考点
- 中缀表达式转后缀表达式
- 后缀表达式求值
(3)前缀表达式相关考点
- 中缀表达式转前缀表达式
- 前缀表达式求值
2.大家熟悉的算术表达式
( ( 15 ÷ ( 7 − ( 1 + 1 ) ) ) × 3 ) − ( 2 + ( 1 + 1 ) ) ((15÷(7-(1+1)))×3)-(2+(1+1)) ((15÷(7−(1+1)))×3)−(2+(1+1))
它实际上是中缀表达式。
由三个部分组成:
- 操作数:就是这些数字
- 运算符:就是加减乘除
- 界限符:就是这些括号
其关键在于,要知道这当中的运算符的执行顺序。
( ( 15 ÷ ( 7 − ( 1 + 1 ) ) ) × 3 ) − ( 2 + ( 1 + 1 ) ) ((15÷(7-(1+1)))×3)-(2+(1+1)) ((15÷(7−(1+1)))×3)−(2+(1+1))
− − ③ − ② − ① − − − − ④ − − ⑦ − − ⑥ − − ⑤ --③-②-①----④--⑦--⑥--⑤ −−③−②−①−−−−④−−⑦−−⑥−−⑤
如果把括号全部去掉,那么运算符的执行顺序当然会发生改变。
15 ÷ 7 − 1 + 1 × 3 − 2 + 1 + 1 15÷7-1+1×3-2+1+1 15÷7−1+1×3−2+1+1
− − ① − ② − ④ − ③ − ⑤ − ⑥ − ⑦ --①-②-④-③-⑤-⑥-⑦ −−①−②−④−③−⑤−⑥−⑦
不难看出,对于中缀表达式,界限符的存在是必须、必要的,若去掉这些界限符,我们就不能正确的表示出各个运算符生效的次序。
有一个波兰的数学家就想:能不能不用界限符也能无歧义地表达运算顺序呢?
- Reverse Polish notation(逆波兰表达式 = 后缀表达式)
- Polish notation(波兰表达式 = 前缀表达式)
3.中缀、后缀、前缀表达式
- 中缀表达式
中缀表达式,它的运算符是在两个操作数中间。
例1:a+b。
例2:a+b-c
例3:a+b-c*d
- 后缀表达式
后缀表达式,它的运算符是在两个操作数后面。
注意:这两个操作数的顺序,是不能随意颠倒的。如果是加法、乘法还好,但是减法、除法运算,就不行了。例如ab/就不能是ba/
例1:ab+
例2:ab+c- 或 abc-+ (可以看出,同一个中缀表达式,可以转换为多种不同的后缀表达式)
例3:ab+cd*-
- 前缀表达式
前缀表达式,它的运算符是在两个操作数前面。
例1:+ab
例2:-+abc(前缀表达式同理,也可转为多种不一样的形式,此处不再赘述)
例3:-+ab*cd
4.中缀表达式转后缀表达式(手算)
中缀转后缀的手算方法:
①确定中缀表达式中各个运算符的运算顺序。
②选择下一个运算符,按照「左操作数 右操作数 运算符」的方式组合成一个新的操作数。
③如果还有运算符没被处理,就继续②。
如:
( ( 15 ÷ ( 7 − ( 1 + 1 ) ) ) × 3 ) − ( 2 + ( 1 + 1 ) ) ((15÷(7-(1+1)))×3)-(2+(1+1)) ((15÷(7−(1+1)))×3)−(2+(1+1))
− − ③ − − ② − − ① − − ④ − − ⑦ − − ⑥ − − ⑤ --③--②--①--④--⑦--⑥--⑤ −−③−−②−−①−−④−−⑦−−⑥−−⑤
将其写为后缀表达式,如下:
15 7 1 1 + − ÷ 3 × 2 1 1 + + − 15\quad7\quad1\quad1\quad+\quad-\quad÷\quad3\quad×\quad2\quad1\quad1\quad+\quad+\quad- 15711+−÷3×211++−
− − − − − − − − − ① − − ② − − ③ − − ④ − − − − − ⑤ − − ⑥ − − ⑦ ---------①--②--③--④-----⑤--⑥--⑦ −−−−−−−−−①−−②−−③−−④−−−−−⑤−−⑥−−⑦
发现一个规律:中缀表达式中,运算符生效的次序,在转化为后缀表达式后,其次序是从左到右依次生效的。
此外:由中缀表达式转为后缀表达式,由于中缀表达式的实际运算次数是不唯一的,所以后缀表达式的写法是不唯一的。
例如:
A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F
− − ③ − − ② − − ① − − ⑤ − − ④ --③--②--①--⑤--④ −−③−−②−−①−−⑤−−④
那么按照这种中序表达式运算符的顺序,其对应的后续表达式为:
A B C D − ∗ + E F / − A\quad B\quad C\quad D\quad -\quad * \quad+\quad E\quad F\quad/\quad- ABCD−∗+EF/−
− − − − − − ① − − ② − − ③ − − − − ④ − − ⑤ ------①--②--③----④--⑤ −−−−−−①−−②−−③−−−−④−−⑤
但如果对中序表达式执行另一种不同的运算顺序:
A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F
− − ⑤ − − ③ − − ② − − ④ − − ① --⑤--③--②--④--① −−⑤−−③−−②−−④−−①
那么其对应的后续表达式为:
A B C D − ∗ E F / − + A\quad B\quad C\quad D\quad -\quad * \quad E\quad F\quad/\quad-\quad + ABCD−∗EF/−+
− − − − − − − − ② − − ③ − − − − ① − − ④ − − ⑤ --------②--③----①--④--⑤ −−−−−−−−②−−③−−−−①−−④−−⑤
这两个后缀表达式的结果,肯定都是正确的,表达的都是同一个中缀表达式。
但是,如果我们要用计算机来实现中缀转后缀的算法的话,我们只应该得到一种输出结果(因为算法应该具有确定性,即同样的输入只能得到同样的输出),那么实际上,用算法实现的结果,应该是前一种后缀表达式的结果。
那么,怎样能够保证得到的是前一种后缀表达式的结果呢?
“左优先”原则:只要左边的运算符能先计算,就优先算左边的。
例如上面那个式子,我一上来可以先计算C-D,也可以先计算E/F,但是由于C-D是在左边的,所以优先计算C-D,这就是左优先原则。
通过左优先原则,可以保证中缀表达式的运算顺序是唯一的,因此便可以保证后缀表达式的结果是唯一确定的。
对于左优先原则,举个例子,如下:
A + B − C ∗ D / E + F A+B-C*D/E+F A+B−C∗D/E+F
很多人可能一上来会先算C*D,然后算/E,最后再进行加减法。
但是若要遵循左优先原则,即左边的运算符若能先计算,就先计算左边的。那么一开始应该先计算A+B。之后,由于减法不能先算了,那么第二步应该算乘法,第三步除法,第四步减法,最后+F。
得到
A B + C D ∗ E / − F + A\quad B\quad +\quad C\quad D\quad *\quad E\quad /\quad -\quad F\quad + AB+CD∗E/−F+
5.后缀表达式的计算(手算)
如果我们有一个后缀表达式,该如何对它的最终结果进行计算?
此处,我们将中缀和后缀放在一起对比着看:
( ( 15 ÷ ( 7 − ( 1 + 1 ) ) ) × 3 ) − ( 2 + ( 1 + 1 ) ) ((15÷(7-(1+1)))×3)-(2+(1+1)) ((15÷(7−(1+1)))×3)−(2+(1+1))
15 7 1 1 + − ÷ 3 × 2 1 1 + + − 15\quad 7\quad1\quad1\quad+\quad-\quad÷\quad3\quad×\quad2\quad1\quad1\quad+\quad+\quad- 15711+−÷3×211++−
对于下面的后缀表达式,我们应该
- 从左往右扫描,看到的第一个运算符是
+,那么我们便首先看到1 1 +的部分,将其进行运算,并在运算过后合并为一个操作数。 - 从左往右扫描,看到第二个运算符是
-,那么我们将刚才的结果,和7进行加法运算。 - 之后同理。
总结
后缀表达式的手算方法:
从左往右扫描,每遇到一个运算符,就让运算符前面最近的两个操作数执行对应运算,合体为一个操作数。
直到最终,所有操作数都合体成为一个操作数,且已经没有操作符了,表达式的结果就计算完毕了。
注意两个操作数的左右顺序。
由于每遇到一个运算符,就让运算符前面最近的两个操作数执行对应运算。因此,其具有后进先出的特点,用栈来实现是比较契合的。
6.后缀表达式的计算(机算)
用栈实现后缀表达式的计算:
①从左往右扫描下一个元素,直到处理完所有元素。
②若扫描到操作数,则压入栈,并回到①;否则执行③。
③若扫描到运算符,则弹出两个栈顶元素,执行相应运算,运算结果压回栈顶,回到①。
注意:先出栈的是“右操作数”。
若表达式合法,则最后栈中只会留下一个操作数,就是后缀表达式的计算结果。
对于后缀表达式来说,计算机无需关心哪个操作数是先生效,哪个是后生效的。只需从左往右扫描,先扫描到的就是先生效的,很适合计算机去操作
**思考:**后缀表达式怎么转中缀?
也很简单,从左往右扫描,该加括号的加上括号。注意左右顺序即可。
7.中缀表达式转前缀表达式(手算)
中缀转前缀的手算方法:
①确定中缀表达式中各个运算符的运算顺序。
②选择下一个运算符,按照「运算符 左操作数 右操作数」的方式组合成一个新的操作数。
③如果还有运算符没被处理,就继续②。
例如:
A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F
①先判断中缀表达式的各个运算符的运算顺序。(③–②--①–⑤--④)
②依次进行前缀组合,如第一步,
-CD。并将其视作一个整体。③直到所有运算符均处理完毕,停止。
− + A ∗ B − C D / E F -\quad+\quad A\quad*\quad B\quad-\quad C\quad D\quad /\quad E\quad F −+A∗B−CD/EF
到此,观察这个前缀表达式,运算符的执行次序依次为:(⑤–③--②–①--④),你会发现不论是从左往右,还是从右往左,它都是没有次序的。
那么类似于后缀表达式的原则,此处也有一个原则,如下。
“右优先”原则:只要右边的运算符能先计算,就优先算右边的。
那么,按照右优先的原则,过程应该如下:
①按照右优先原则判断各个运算符的运算顺序。(⑤–③--②–④--①)
②③略。
得到的结果为:
+ A − ∗ B − C D / E F +\quad A\quad -\quad*\quad B\quad-\quad C\quad D\quad /\quad E\quad F +A−∗B−CD/EF
对于这个前缀表达式,可以看出,其运算符的执行次序,是从右至左依次生效的(⑤–④--③–②--①)。
8.前缀表达式的计算
用栈实现前缀表达式的计算:
①从右往左扫描下一个元素,直到处理完所有元素。
②若扫描到操作数,则压入栈,并回到①;否则执行③。
③若扫描到运算符,则弹出两个栈顶元素,执行响应运算,运算结果压回栈顶,回到①。
注意:先出栈的是“左操作数”。
9.※中缀表达式转后缀表达式(机算)
初始化一个栈,用于保存暂时还不能确定运算顺序的运算符。
从左到右处理各个元素,直到末尾。可能遇到三种情况:
- 遇到操作数。直接加入后缀表达式。
- 遇到界限符。遇到“(”直接入栈;遇到“)”则依次弹出栈内运算符并加入后缀表达式,直到弹出“(”为止。注意:“(”不加入后缀表达式。
- 遇到运算符。依次弹出栈中优先级高于或等于当前运算符的所有运算符,并加入后缀表达式,若碰到“(”或栈空则停止。之后再把当前运算符入栈。
按上述方法处理完所有字符后,将栈中剩余运算符依次弹出,并加入后缀表达式。
实际上,中缀表达式转后缀表达式,其中操作数的前后顺序是不会改变的,改变的是运算符的先后顺序。我们用栈就是用来确定运算符的运算顺序。
对于优先级:乘除的优先级是高于加减的。乘与除、加与减的优先级是相等的。当然,在数学中可能还有其他运算符。但在此处我们只考虑加减乘除。
对于其中运算符入栈、出栈的逻辑分析:
对于中缀表达式来说,如
A + B − C ∗ D / E + F A+B-C*D/E+F A+B−C∗D/E+F
可以看到,每个操作数的左右两边都是有一个运算符的(除了头尾两个)。那么,当扫描到第二个运算符,即减号时,由于之前存入栈中的加号和它的优先级是相等的,也就是说,当扫描到减号时,我可以放心的让加号先出来,让加法先生效。反之,若当前扫描到了第三个运算符,即乘号。此时,栈中存放一个减号,那么我就不能让减号先出来进行生效。因为,若减号弹出栈去生效的话,减法就比乘法先生效了,这并不符合运算的规则。
那么,既然减法不能弹出进行生效,那么我的乘法能不能直接去生效?也是不行的。因为如果乘法后面刚好有一个界限符,即括号的话,乘法也是不能先生效的。所以,总之也要先将乘法压入栈中。
再往后,扫描到了除号。此时栈顶元素是乘法。同样的道理,可以放心的让乘法先生效。
同理,除法能直接生效吗?也不能,因为不能确定除法后面有没有括号。所以除法也要先压入栈中。
最后,扫描到了加号。检查栈中元素,依次弹出除号、减号。
最终得到后缀表达式,如下
A B + C D ∗ E / − F + AB+CD*E/-F+ AB+CD∗E/−F+
再看一个带有界限符,即带有括号的例子:
中缀表达式如下
A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F
从左到右扫描。
- 加号入栈。
- 遇到乘法,检查栈中元素,只有一个加号,则加号不能出栈进行生效,否则加号优先于乘法生效了,不符合运算规则。乘号入栈。
- 遇到左括号,说明在它之前的一切运算符,优先级都是偏低的,因此不必检查栈中元素的优先级,而直接将左括号入栈。
- 遇到减号,依次扫描栈中优先级高于或等于它的运算符,遇到左括号或栈空时停止。而此时栈顶元素即为左括号,所以停止。并将减号入栈。
- 此处的逻辑为,遇到减号时扫描栈,发现栈顶就是左括号,则说明减号左边的这个操作数,这个操作数的左边就是一个左括号,那么即将要做的事就是优先计算左右括号里面的表达式。所以扫描到左括号时停止。左括号就像空栈一样作为一个小的界限。同时,由于减法只是这个括号中的一个运算符,并不确定括号中是否还有其他运算符,如乘法,所以减法也不能立即生效,而要先入栈。
- 即,确定不了运算顺序的运算符都要先入栈。
- 遇到右括号,依次弹出栈内运算符,直到弹出左括号为止。即弹出减号,之后遇到左括号停止。
- 此处的逻辑为,当扫描到右括号时,就已经确定了这个小界限的范围了,括号内的内容整体是作为一部分优先计算的内容,所以我们可以直接的将栈中左括号之前的运算符全部弹出生效。
- 之后的减法,除法不再赘述。
最终得到后缀表达式
A B C D − ∗ + E F / − ABCD-*+EF/- ABCD−∗+EF/−
10.中缀表达式的计算(用栈实现)
即中缀转后缀+后缀表达式求值,这两个算法的结合。
用栈实现中缀表达式的计算:
- 初始化两个栈,操作数栈和运算符栈。
- 操作数栈:用于存放当前暂时还不能确定运算次序的操作数。
- 运算符栈:用于存放当前暂时还不能确定运算次序的操作符。
- 若扫描到操作数,压入操作数栈。
- 若扫描到运算符或界限符,则按照“中缀转后缀”相同的逻辑压入运算符栈
- 期间也会弹出运算符。每当弹出一个运算符时,就需要再弹出两个操作数栈的栈顶元素并执行相应运算,运算结果再压回操作数栈。
- 因为,你弹出一个运算符,就意味着要将这个运算符之前的两个操作数(此处的操作数也可以是已经完成某些运算的小整体)生效此运算。自然要弹出操作数栈的两个栈顶元素,求值后压回。
- 要注意,对于后缀表达式,操作数栈先弹出的是右操作数。
需要关注的一点是,此处这一系列逻辑,实际上是将中序表达式这样混合起来的运算表达式,转化为了有条理的,按照某个确定顺序,且每次只执行一个运算操作,最终得出正确结果的运算。
也就是需要把一个复杂的式子,拆解成一次又一次确定的、简单的,计算机能够执行的程序。
因此,将
A + B − C ∗ D / E + F A+B-C*D/E+F A+B−C∗D/E+F
这样的式子,翻译成与它等价的机器指令的时候。就需要用到此处中缀表达式的计算的这一系列思想和方法。是一个很重要、很有价值的思想方法。
(三)栈的应用——递归
递归函数就是调用它自身的一个过程。
1.普通函数调用背后的过程
void main(){
int a,b,c;
//...
func1(a,b);
c = a + b;
//......
}
void func1(int a, int b){
int x;
//...
func2(x);
x = x + 100;
//......
}
void func2(int x){
int m,n;
//......
}
在main执行的过程中,遇到了func1函数,于是转过去执行func1,在执行的过程中,遇到func2函数,于是转过去执行func2。
当func2执行结束后,func1的下一步便可以继续执行,直到func1全部结束。
当func1执行结束,main函数便得以继续进行,直到全部结束。
可以看到,函数调用的特点:最后被调用的函数最先执行结束(LIFO)。
就和栈的后进先出是一样的。
实际上,在我们的任何一段代码执行之前,系统都会给我们开辟一个函数调用栈,用来保存各个函数在调用过程中必须保存的一些信息。
函数调用时,需要用一个栈存储:
①调用返回地址
②实参
③局部变量
这也就是为什么,main函数中写了a,b两个参数,而调用func1函数的形参也是a,b,但却影响不到main函数中相应变量的值。这是因为func1函数调用时,是另外存储了其参数a,b的,这与刚刚main函数中的a,b并不是同一个。
返回地址就是指,在原函数中,执行完这个小函数后的下一操作语句的地址。
即对于main函数中,执行到func1(a,b),那么func1函数的函数调用栈中要存放参数a,b及局部变量x,还要存放main函数在下一句该执行的语句
c=a+b的地址。这样一来,当func1函数结束后,会找到这个返回地址以使得程序继续运行。
2.栈在递归中的应用
适合用递归算法解决的:可以把原始问题转化为属性相同,但规模较小的问题。
对于递归算法,要有两个关键要素:
- 递归表达式(递归体)
- 边界条件(递归出口)
此处主要讨论的是递归算法与栈之间的联系,并不过多关注递归算法的具体实现。
例1.递归算法求阶乘
//计算正整数 n!
int factorial(int n) {
if(n == 0 || n == 1) return 1;
else return n * factorial(n-1);
}
int main(){
//...
int x = factorial(10);
//......
}
递归调用时,函数调用栈可称为“递归工作栈”。
每进入一层递归,就将递归调用所需信息压入栈顶。
每退出一层递归,就从栈顶弹出相应信息。
因此,如果递归的层数过多,便会产生过多的栈,可能会导致栈溢出。
因为我们的内存资源,或者说系统给我们开辟的函数调用栈,肯定是有一个存储的上限的。
此处可以再次回顾:递归算法的空间复杂度的问题。
因此,可以自定义一个栈,将递归算法改造成非递归算法,然后在自己定义的栈中实现这个逻辑上的“递归”。
例2.递归算法求斐波那契数列
int Fib(int n) {
if(n == 0) return 0;
else if(n == 1) return 1;
else return Fib(n-1)+Fib(n-2);
}
int main(){
//...
int x = Fib(4);
//......
}
此处和上面的阶乘算法,又有所不同。
当算法return Fib(n-1) + Fib(n-2)时,会先将Fib(n-1)执行至最深层,最后全部返回上来后,再轮到Fib(n-2)的执行。同时,由于Fib(n-1)与Fib(n-2)实际上只相差了1,也就是说,例如计算Fib(4)+Fib(3)时,实际上有很大一部分是执行了两遍的(在Fib4中执行过后,Fib3中又执行了一遍)。
因此,递归算法可能包含很多重复计算。
总之,栈的缺点大致为:
- 效率低,太多层递归可能会导致栈溢出
- 可能包含很多重复计算
可以自定义栈,将递归算法改造成非递归算法。
(四)队列应用——树的层次遍历
注:在“树”的章节中会详细学习。
例如有这样一棵树:
1 / ∣ 2 3 / ∣ / ∣ 4 5 6 7 / ∣ / ∣ 8 9 10 11 1\\ /|\\ 2\quad3\\ /|\quad\ /|\\ 4\quad5\quad6\quad7\\ /|\qquad/|\\ 8\quad9\quad10\quad11 1/∣23/∣ /∣4567/∣/∣891011
对于树的层次遍历,就是对每一层,从左到右依次遍历。
这棵树的层次遍历即为:①②③④⑤⑥⑦⑧⑨⑩⑪。
那么如何用队列实现呢?
先初始化一个队列,之后,由树的头结点开始:
- 遍历结点①,入队,并将其左孩子、右孩子入队。
- ①->②->③
- 此时,遍历完毕①号结点,①出队。
- 出队情况:①
- 队列情况:②->③
- 遍历结点②,将其左孩子、右孩子入队。
- ②->③->④->⑤
- 此时,遍历完毕②号结点,②出队。
- 出队情况:①②
- 队列情况:③->④->⑤
- 遍历结点③,将其左孩子、右孩子入队。
- ③->④->⑤->⑥->⑦
- 此时,遍历完毕③号结点,③出队。
- 出队情况:①②③
- 队列情况:④->⑤->⑥->⑦
- 遍历结点④,其没有左右孩子。
- ④->⑤->⑥->⑦
- 此时,遍历完毕④号结点,④出队。
- 出队情况:①②③④
- 队列情况:⑤->⑥->⑦
- 遍历结点⑤,将其左右孩子入队。
- ⑤->⑥->⑦->⑧->⑨
- 此时,⑤出队。
- 出队情况:①②③④⑤
- 队列情况:⑥->⑦->⑧->⑨
- 以此类推。
(五)队列应用——图的广度优先遍历
注:在“图”章节中会详细学习。
例如有一个图,如下
2 − 1 6 − 8 ∣ ∣ / ∣ / ∣ 4 3 − 5 − 7 2-1\quad6-8\\ |\quad|\quad/|\quad/|\\ 4\quad3-5-7 2−16−8∣∣/∣/∣43−5−7
- 假设由①结点出发,检查其相邻结点,即②或③,看是否已被遍历过,都没有被遍历过,则加入队尾。
- ①->②->③
- 此时,①遍历完毕,①出队。
- 出队情况:①
- 队列情况:②->③
- 遍历至②结点,同样,看其相邻结点有没有被遍历过,没有遍历过的加入队尾。
- ②->③->④
- 此时,②出队。
- 出队情况:①②
- 队列情况:③->④
- 遍历至③。
- ③->④->⑤->⑥
- ③出队。
- 出队情况:①②③
- 队列情况:④->⑤->⑥
- 遍历至④,显然,与④相邻的结点都已被遍历过,则直接将④出队。
- ④出队
- 出队情况:①②③④
- 队列情况:⑤->⑥
- 遍历至⑤。
- ⑤->⑥->⑦->⑧
- ⑤出队。
- 出队情况:①②③④⑤
- 队列情况:⑥->⑦->⑧
- 后续的遍历,均不会再加入任何“没有被遍历过”的新的结点,因此之后均依次出队。
- 最终得到出队情况:①②③④⑤⑥⑦⑧
- 此时队列为空。
(六)队列在操作系统中的应用
多个进程争抢着使用有限的系统资源时,FCFS(First Come First Service,先来先服务)是一种常用策略。
就是哪个进程先申请,就让哪个进程先进行服务。
这与队列的先进先出是契合的。因此可用队列实现。
例如:CPU资源的分配。
例如:打印机的待打印队列。
九、矩阵的压缩存储
- 数组的存储结构
- 一维数组
- 二维数组
- 特殊矩阵
- 对称矩阵
- 三角矩阵
- 三对角矩阵
- 稀疏矩阵
(一)一维数组
ElemType a[10];//ElemType型一维数组
内 存 : a [ 0 ] a [ 1 ] a [ 2 ] a [ 3 ] a [ 4 ] a [ 5 ] a [ 6 ] a [ 7 ] a [ 8 ] a [ 9 ] 内存:a[0]\quad a[1]\quad a[2]\quad a[3]\quad a[4]\quad a[5]\quad a[6]\quad a[7]\quad a[8]\quad a[9] 内存:a[0]a[1]a[2]a[3]a[4]a[5]a[6]a[7]a[8]a[9]
各数组元素大小相同,且物理上连续存放。
因此,只需要知道其起始地址,就可以知道任何一个数组下标所对应元素的存放地址是多少。
起始地址
LOC数组a[i]的存放地址为
LOC + i * sizeof(ElemType) (0≤i<10)
注:除非题目特别说明,否则数组下标默认从0开始。要注意审题。
(二)二维数组
ElemType b[2][4];//2行4列的二维数组
逻 辑 : b [ 0 ] [ 0 ] b [ 0 ] [ 1 ] b [ 0 ] [ 2 ] b [ 0 ] [ 3 ] b [ 1 ] [ 0 ] b [ 1 ] [ 1 ] b [ 1 ] [ 2 ] b [ 1 ] [ 3 ] 逻辑:\\ b[0][0]\quad b[0][1]\quad b[0][2]\quad b[0][3]\\ b[1][0]\quad b[1][1]\quad b[1][2]\quad b[1][3] 逻辑:b[0][0]b[0][1]b[0][2]b[0][3]b[1][0]b[1][1]b[1][2]b[1][3]
在内存空间中存储时,由于要进行线性存储,因此要将逻辑上的非线性给改变为线性的存储模式。因此,有两种存储策略:行优先存储、列优先存储。
行优先存储即先从左到右将第一行元素依次存储,再将第二行元素依次存储。列优先存储道理是类似的。
行 优 先 存 储 , 内 存 : b [ 0 ] [ 0 ] b [ 0 ] [ 1 ] b [ 0 ] [ 2 ] b [ 0 ] [ 3 ] b [ 1 ] [ 0 ] b [ 1 ] [ 1 ] b [ 1 ] [ 2 ] b [ 1 ] [ 3 ] 列 优 先 存 储 , 内 存 : b [ 0 ] [ 0 ] b [ 1 ] [ 0 ] b [ 0 ] [ 1 ] b [ 1 ] [ 1 ] b [ 0 ] [ 2 ] b [ 1 ] [ 2 ] b [ 0 ] [ 3 ] b [ 1 ] [ 3 ] 行优先存储,内存:b[0][0]\quad b[0][1]\quad b[0][2]\quad b[0][3]\quad b[1][0]\quad b[1][1]\quad b[1][2]\quad b[1][3]\\ 列优先存储,内存:b[0][0]\quad b[1][0]\quad b[0][1]\quad b[1][1]\quad b[0][2]\quad b[1][2]\quad b[0][3]\quad b[1][3] 行优先存储,内存:b[0][0]b[0][1]b[0][2]b[0][3]b[1][0]b[1][1]b[1][2]b[1][3]列优先存储,内存:b[0][0]b[1][0]b[0][1]b[1][1]b[0][2]b[1][2]b[0][3]b[1][3]
同样地,只要知道起始地址LOC,也可知道任何一个元素的存放地址。(当然,要知道是按行优先存储还是列优先存储的)
M行N列的二维数组
b[M][N]中,
- 若按行优先存储,则
b[i][j]的存储地址 =LOC + (i*N + j) * sizeof(ElemType)即每一行有多少个元素,乘它前面有多少行,再加上它位于第几列。
- 若按列优先存储,则
b[i][j]的存储地址 =LOC + (j*M + i) * sizeof(ElemType)即每一列有多少个元素,乘它前面有多少列,再加上它位于第几行。
(三)普通矩阵的存储
最容易想到的就是用一个二维数组存储。
注意:描述矩阵元素时,行、列号通常从1开始;而描述数组时通常下标从0开始。因此要具体看题目所给条件,要注意审题。
这是对于普通矩阵的存储。
而对于某些特殊的矩阵,我们可以用一些巧妙的办法来压缩其存储空间。
特殊矩阵如:对称矩阵、三角矩阵、三对角矩阵、稀疏矩阵。
(四)对称矩阵的压缩存储

若n阶方阵中任意一个元素a(i, j),都有a(i, j) = a(j, i),则该矩阵为对称矩阵。
也就是以主对角线为对称轴,两侧对应元素的值相等。
其中,对称轴上方的区域(i
j)称为下三角区。
由于上三角区和下三角区的数据是完全相同的,因此我们在存储数据的时候,只需要存储主对角线及上下某一个三角区即可。
以只存储主对角线与下三角区为例。
按行优先原则将各元素存入一维数组中。(第一行存1个数据,第二行存2个数据,第三行存3个数据…)
思考:
-
数组大小应为多少?
- 第一行1个,第二行2个,第n行n个。等差数列求和。即(1+n)*n/2。
- 那么这个一维数组的下标也就是由0到(1+n)*n/2-1。
-
站在程序员的角度,对称矩阵压缩存储后怎样才能方便使用?
-
因为,我们存储数据的目的,还是最后要用这些数据。
当你在用这些数据的时候,从你的视角,你肯定是想看到一个矩阵,而不是看到一个一维数组。
你肯定是想由矩阵的下标,例如a(3, 2),来访问到相应的元素,而不是直接使用一维数组的某个下标。
对于这个问题,你可以自己实现一个“映射”函数,填入行号、列号,让函数自动计算其对应于一维数组中的下标,并将其中数据返回,即可。
-
那么,怎样把矩阵的行号、列号,正确的映射为与之对应的一维数组的下标?
即a(i, j) (i>j) → B[k]
关键在于:按行优先的原则,a(i, j)是第几个元素?
a(i, j)是第i行、第j列。
在其前面有i-1行。之前我们说了,第一行有1个元素,第二行有2个元素…
所以在其前面有:[1+2+…+(i-1)]个元素
又因为它是第j列,所以
它是一维数组中第
[1+2+...+(i-1)] + j个元素。由于数组下表k是从0开始的,所以上面的结果再减1即可。
-
如果要访问的是上三角区的元素怎么办?
虽然我们没有把上三角区的元素实际存放起来,但是由于对称矩阵拥有这样一个特性。所以我们可以将其行号和列号对调,之后再按照访问下三角区域的元素的方法访问即可。
-
注意:这些东西,要理解其是如何推导得到的,而不要去背。知道如何推导,那么,无论是行优先,还是列优先,无论是存放上三角,还是下三角,自己都可以正确的推导出结果。
例如从不同的角度来出题:
- 存储上三角?存储下三角?
- 行优先?列优先?
- 矩阵元素的下标从0开始?
- 数组下标从0开始?从1开始?
(五)三角矩阵的压缩存储
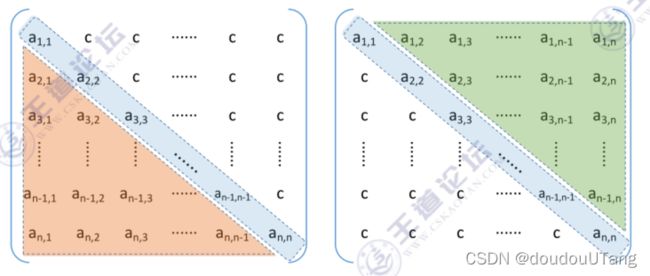
下三角矩阵:除了主对角线和下三角区,其余的元素都相同(常量C)。
上三角矩阵:除了主对角线和上三角区,其余的元素都相同(常量C)。
压缩存储策略:按行优先原则将下三角区域/上三角区域存入一维数组中。并在最后一个位置存储常量C。
总共所需的空间大小为:(1+2+...+n)+1
因此,若访问的是均为常量的那半个区域的话,其在一维数组中的访问位置,应该直接映射至一维数组的最后一位。
(六)三对角矩阵的压缩存储

三对角矩阵,又称带状矩阵:
当
| i - j | > 1时,有a(i, j) = 0 (i ≥ 1,j ≤ n)
压缩存储策略:按行优先(或列优先)原则,只存储带状部分。
总共所需的空间大小?
不难发现,对于带状矩阵,除了第一行、最后一行是两个数据元素外,其余的行都是三个数据元素。
因此其所存储的元素个数为
3n-2个。
怎么把a(i, j)映射到与之对应的一维数组下标处?
若
|i - j| > 1,其值肯定是0。反之则去数组里面找。
按行优先的原则,a(i, j)是一维数组中的第几个元素?
它是第i行,在它前面有i-1行,共3(i-1)-1个元素。
而且它是第i行的第j-i+2个元素。
所以a(i, j)是第
2i+j-2个元素。数组下标若从0开始,则以上数字均需减1。
反过来考虑,假设我们已知一维数组下标k,如何得知其在矩阵中的行、列,即i、j?
由于数组下标是从0开始的,因此下标k的元素是第k+1个元素。
第k+1个元素在第几行、第几列?
设其在第i行、第j列。
前i-1行共
3(i-1)-1个元素。所以显然,
3(i-1)-1 < k+1 ≤ 3i-1根据这个不等式,将i解出即可。同时j也轻易能够得出了。
(七)稀疏矩阵的压缩存储

稀疏矩阵:非零元素远远少于矩阵元素的个数。
当然,什么叫远远少于,这个并没有一个固定的界限。
压缩存储策略
- 方法一:
顺序存储——三元组(行,列,值)
注,此处三元组中存放的行号、列号,就是从1开始的了,因为它并不是个数组。
显然,用这种方法存储稀疏矩阵的数据的话,若要访问某一行某一列的数据,就要从头顺序的依次扫描三元组,对其行号、列号遍历,直到查找到目标。就不具备随机存取的特性了。
- 方法二:
链式存储——十字链表法
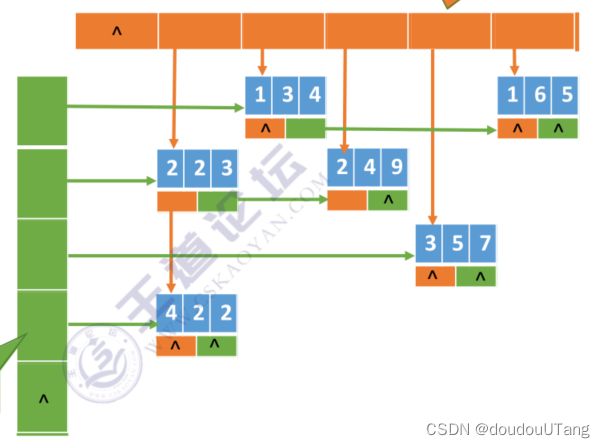
在“上侧”定义一个数组,用来存放每一列的指针,叫做向下域(down),指向第j列的第一个元素;
在“左侧”定义一个数组,用来存放每一行的指针,叫做向右域(right),指向第i行的第一个元素。
每个非零元素成为一个数据结点,被存放着。
(也就是向下域、向右域都指向当前列/行的第一个非零数据所形成的数据结点)
其中,每个非零数据结点,除存放三元组(行,列,值)外,还存放两个指针,分别指向同列的下一个元素、同行的下一个元素。