CHAPTER 1: SCALE FROM ZERO TO MILLIONS OF USERS
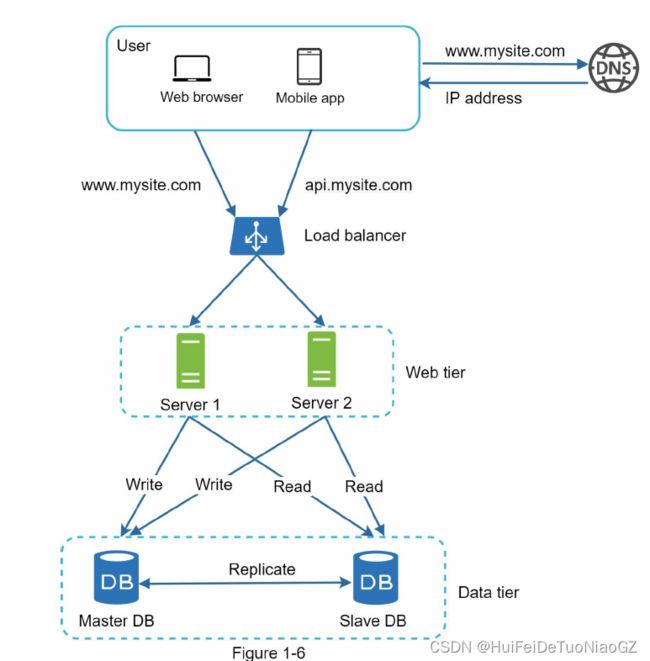
Single server setup
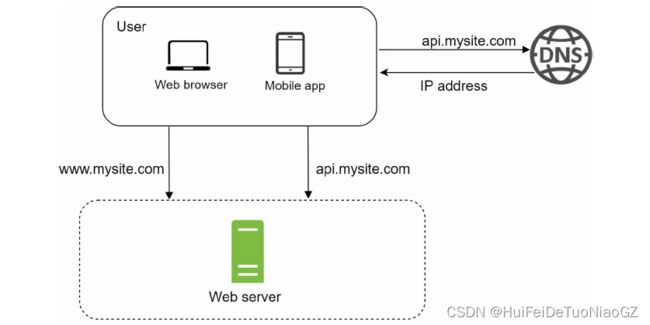
request flow
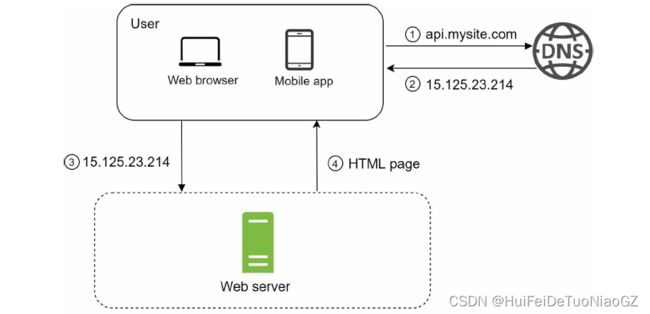
Database
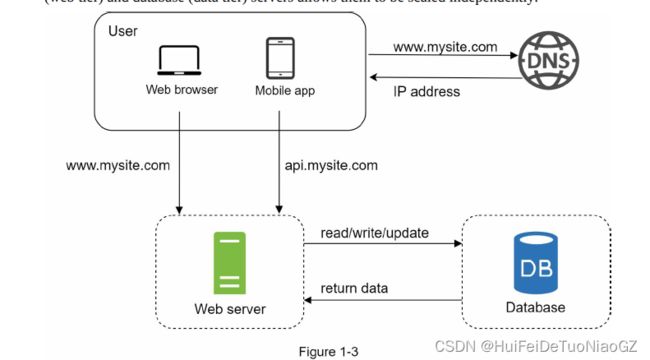
Separating web/mobile traffic
(web tier) and database (data tier) servers allows them to be scaled independently.
Which databases to use?
Relational databases represent and store data in tables and rows. You can perform join
operations using SQL across different database tables.
Non-Relational databases are also called NoSQL databases.
These databases are grouped into four categories: key-value stores, graph stores, column stores, and document stores(stored like json). Join
operations are generally not supported in non-relational databases.
Non-relational databases might be the right choice if:
• Your application requires super-low latency.
• Your data are unstructured, or you do not have any relational data.
• You only need to serialize and deserialize data (JSON, XML, YAML, etc.).
• You need to store a massive amount of data.
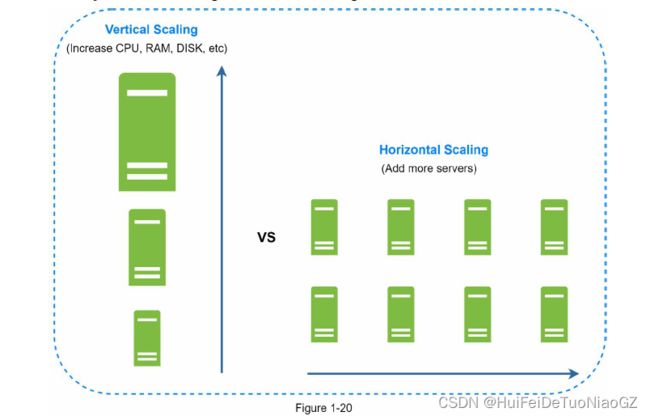
Vertical scaling vs horizontal scaling
Vertical scaling, referred to as “scale up”, means the process of adding more power (CPU,
RAM, etc.) to your servers.
traffic is low
simple
has limit
have not failover and redundancy
Horizontal scaling, referred to as “scale-out”, allows you to scale
by adding more servers into your pool of resources.
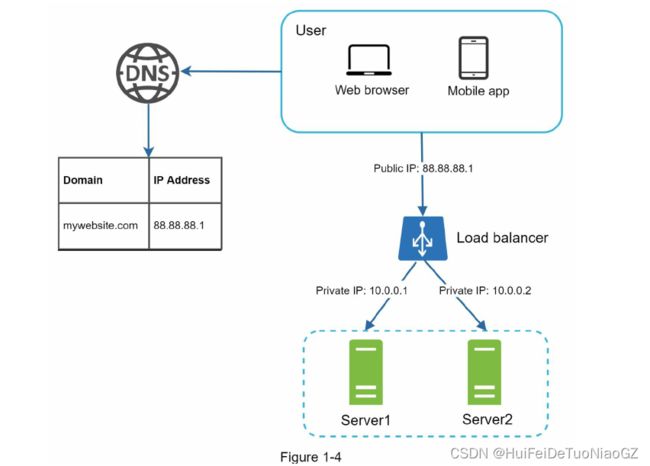
Load balancer
Database replication

Most applications require a much higher ratio of reads to writes; thus, the number of slave
databases in a system is usually larger than the number of master databases.
Advantages of database replication:
• Better performance: In the master-slave model, all writes and updates happen in master
nodes; whereas, read operations are distributed across slave nodes. This model improves
performance because it allows more queries to be processed in parallel.
• Reliability: If one of your database servers is destroyed by a natural disaster, such as a
typhoon or an earthquake, data is still preserved. You do not need to worry about data loss
because data is replicated across multiple locations.
• High availability: By replicating data across different locations, your website remains in
operation even if a database is offline as you can access data stored in another database
server.
if only one slave and slave is down, master can temperarily work as a slave
if master is down, a slave can work as a master but the data in the slave might not be up to date. So we need datafix and to set up a new master is usually more complicated. One solution to this is to use multiple master.
Cache tier

Consider using cache when data is read frequently but modified infrequently.
Expiration policy.
Consistency
Mitigating failures: A single cache server represents a potential single point of failure
(SPOF), defined in Wikipedia as follows: “A single point of failure (SPOF) is a part of a
system that, if it fails, will stop the entire system from working”
use multiple caches or overprovision the required memory
Eviction Policy
Content delivery network (CDN)
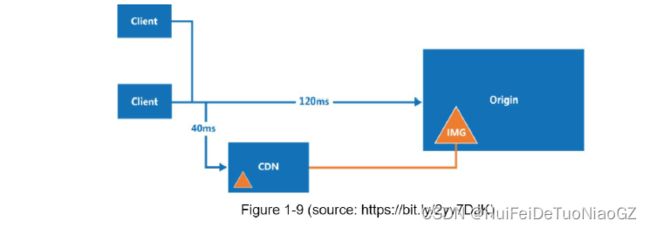
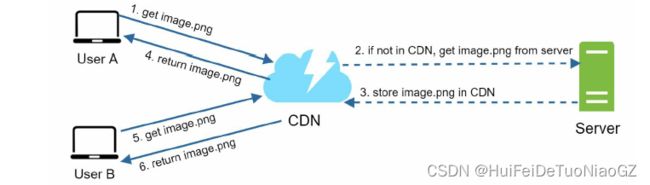
Cost: CDNs are run by third-party providers
Setting an appropriate cache expiry
CDN fallback
Invalidating files
Invalidate the CDN object using APIs provided by CDN vendors.
• Use object versioning to serve a different version of the object. To version an object,
you can add a parameter to the URL, such as a version number. For example, version
number 2 is added to the query string: image.png?v=2.
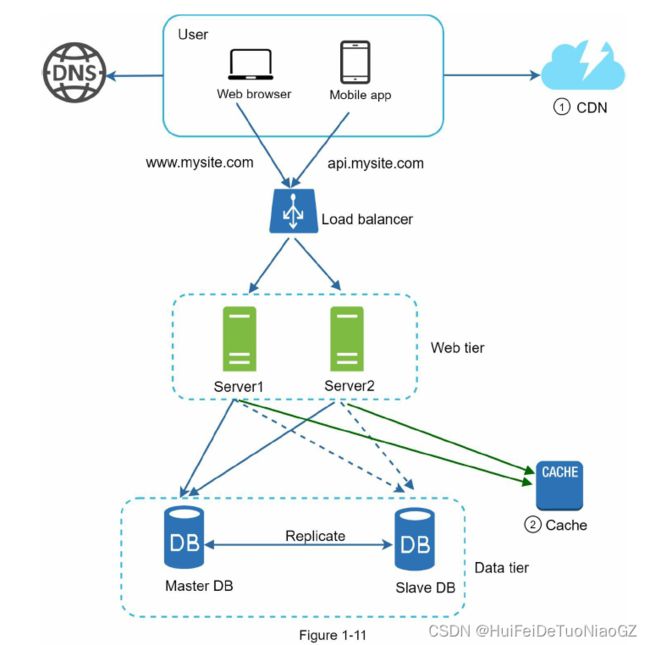
- Static assets (JS, CSS, images, etc.,) are no longer served by web servers. They are
fetched from the CDN for better performance. - The database load is lightened by caching data.
Stateless web tier
Now it is time to consider scaling the web tier horizontally. For this, we need to move state
(for instance user session data) out of the web tier.A good practice is to store session data in
the persistent storage such as relational database or NoSQL. Each web server in the cluster
can access state data from databases. This is called stateless web tier.
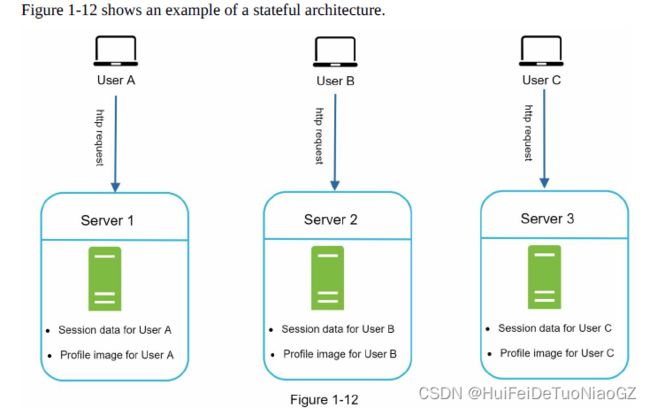
Stateful architecture
Stateless architecture
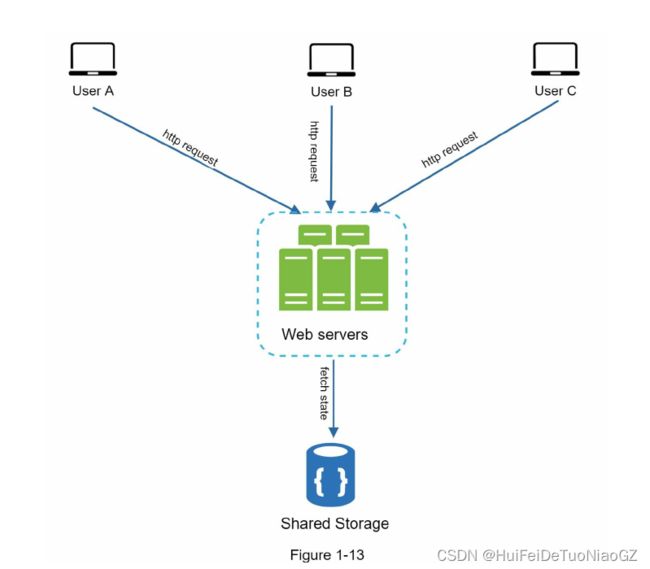
we move the session data out of the web tier and store them in the persistent
data store.
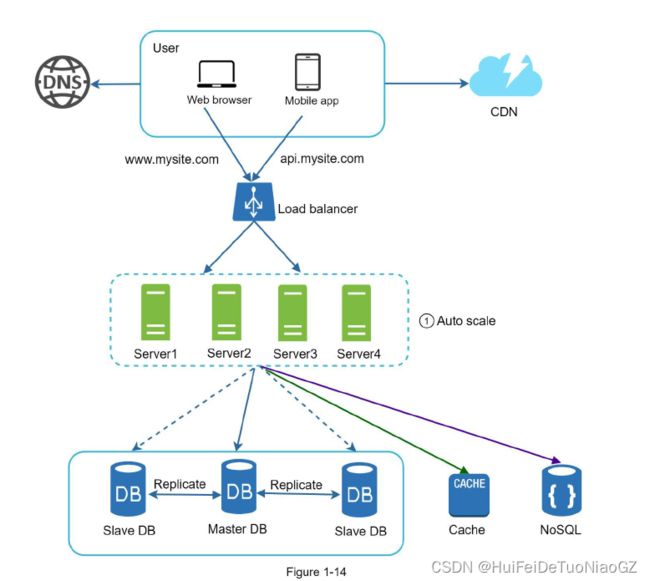
Autoscaling means adding or
removing web servers automatically based on the traffic load. After the state data is removed
out of web servers, auto-scaling of the web tier is easily achieved by adding or removing
servers based on traffic load.
Data centers
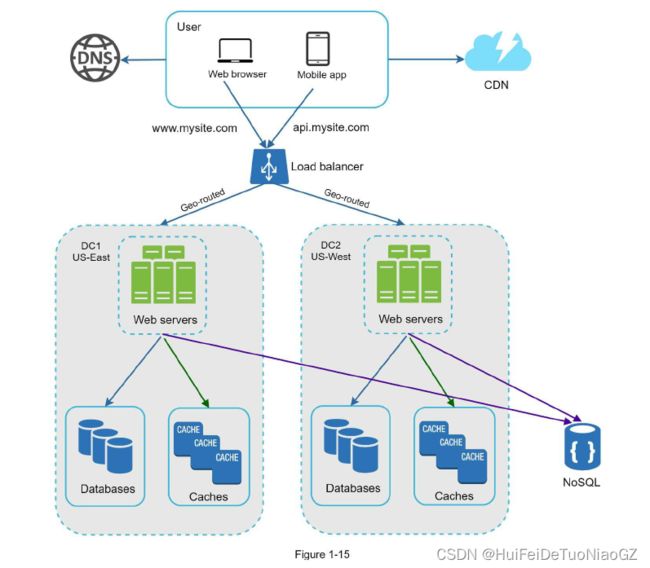
geoDNS is a DNS service that allows domain
names to be resolved to IP addresses based on the location of a user.
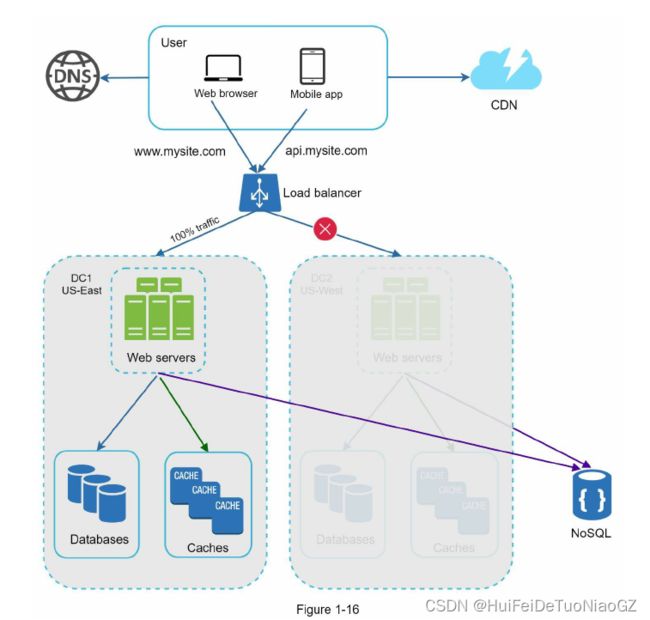
Traffic redirection: Effective tools are needed to direct traffic to the correct data center.
GeoDNS can be used to direct traffic to the nearest data center depending on where a user
is located.
Data synchronization
Test and deployment: With multi-data center setup, it is important to test your
website/application at different locations. Automated deployment tools are vital to keep
services consistent through all the data centers
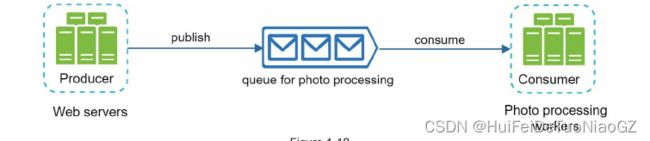
Message queue
A message queue is a durable component, stored in memory, that supports asynchronous
communication.

Decoupling
The consumer can read messages from the queue even when the producer is unavailable.
The producer and the consumer can be scaled independently
Logging, metrics, automation
Logging: Monitoring error logs is important because it helps to identify errors and problems
in the system. You can monitor error logs at per server level or use tools to aggregate them to
a centralized service for easy search and viewing.
Metrics: Collecting different types of metrics help us to gain business insights and understand
the health status of the system. Some of the following metrics are useful:
• Host level metrics: CPU, Memory, disk I/O, etc.
• Aggregated level metrics: for example, the performance of the entire database tier, cache
tier, etc.
• Key business metrics: daily active users, retention, revenue, etc.
Automation: When a system gets big and complex, we need to build or leverage automation
tools to improve productivity. Continuous integration is a good practice, in which each code
check-in is verified through automation, allowing teams to detect problems early. Besides,
automating your build, test, deploy process, etc. could improve developer productivity
significantly.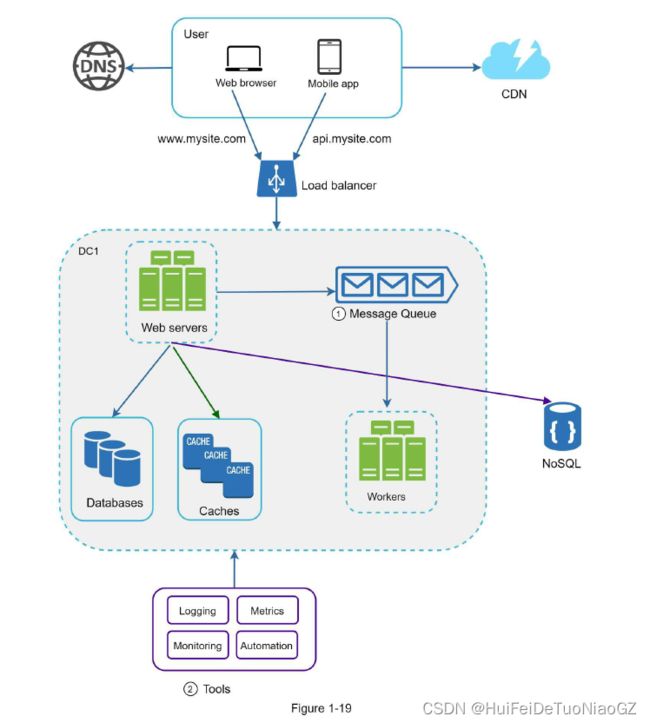
Database scaling
Vertical scaling
vertical scaling comes with some serious drawbacks:
hardware limits
Greater risk of single point of failures.
The overall cost of vertical scaling is high. Powerful servers are much more expensive
Horizontal scaling
Anytime you access data, a hash function is used to find the
corresponding shard. In our example, user_id % 4 is used as the hash function.
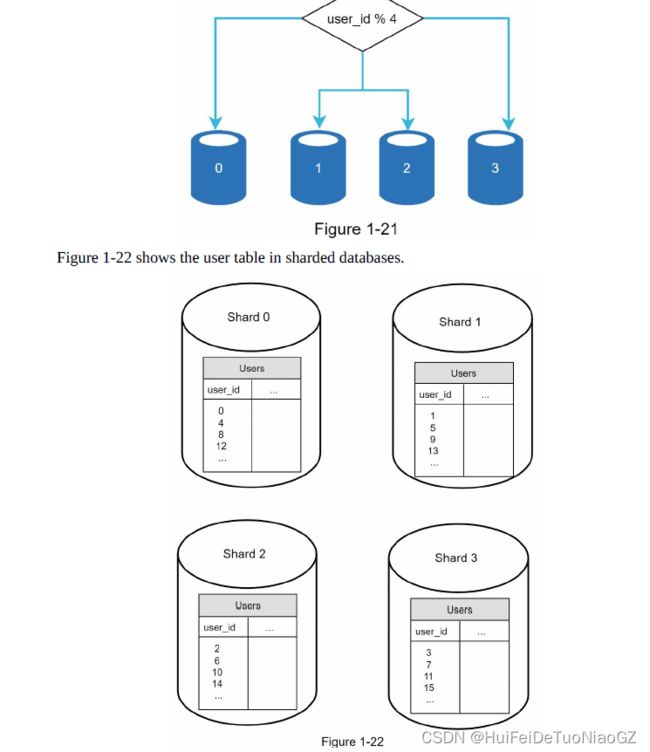
Resharding data
Celebrity problem
also called a hotspot key problem. Excessive access to a specific
shard could cause server overload. Imagine data for Katy Perry, Justin Bieber, and Lady
Gaga all end up on the same shard.
we may need to allocate a shard for each
celebrity. Each shard might even require further partition.
Join and de-normalization: Once a database has been sharded across multiple servers, it is
hard to perform join operations across database shards. A common workaround is to denormalize the database so that queries can be performed in a single table.
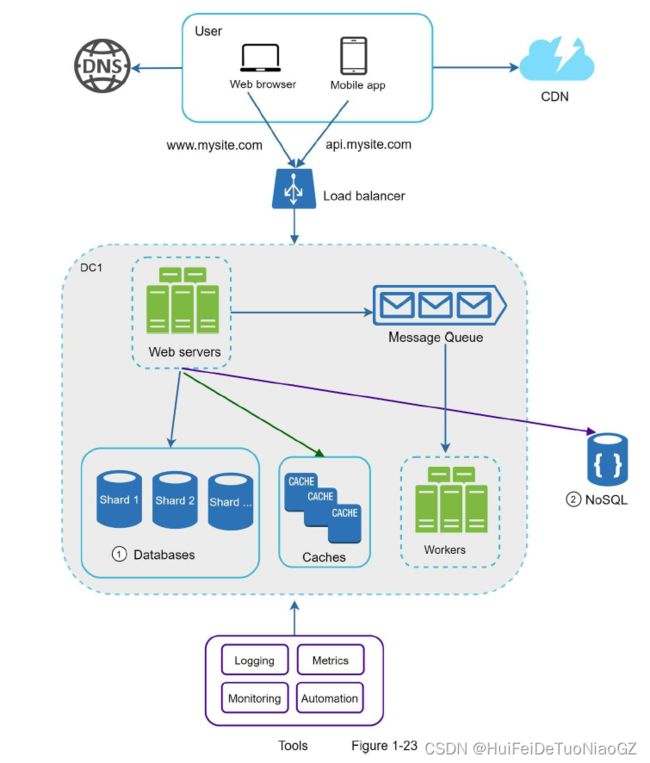
• Keep web tier stateless
• Build redundancy at every tier
• Cache data as much as you can
• Support multiple data centers
• Host static assets in CDN
• Scale your data tier by sharding
• Split tiers into individual services
• Monitor your system and use automation tools