[论文阅读]Coordinate Attention for Efficient Mobile Network Design
摘要
最近关于移动网络设计的研究已经证明了通道注意力(例如, the Squeeze-and-Excitation attention)对于提高模型的性能有显著的效果,但它们通常忽略了位置信息,而位置信息对于生成空间选择性注意图非常重要。在本文中,我们提出了一种新的移动网络注意力机制,将位置信息嵌入到通道注意力中,我们称之为“坐标注意力”。与通过二维全局池化将特征张量转换为单个特征向量的通道注意力不同,坐标注意力通过分别沿着两个空间方向聚合特征,将通道注意分解为两个一维特征编码过程。 这样可以在一个空间方向上捕获远程依赖关系,同时在另一个空间方向上保持精确的位置信息。然后将得到的特征图分别编码为一对方向感知和位置敏感的注意图,它们可以互补地应用于输入特征图,以增强感兴趣对象的表示。我们的坐标注意力十分简单,而且可以灵活地插入经典的移动网络,如MobileNetV2, MobileNeXt和EfficientNet而几乎没有计算开销。大量的实验表明,我们的坐标注意力不仅有利于ImageNet分类,更有趣的是,在下游任务如目标检测和语义分割中表现更好。代码可以在https://github.com/Andrew- Qibin/CoordAttention.获取
1.引言
注意力机制被用来告诉模型去注意什么和哪里,现在已经被广泛的研究和使用来促进现代深度神经网络的表现。然而,注意力机制在移动网络(大小受限)上的应用明显的落后于大型网络。这主要是因为对于移动网络,大部分的注意力机制所带来的计算开销是不可接受的。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第1张图片](http://img.e-com-net.com/image/info8/12f5f33c55dd451ea2ca778cb0fb6f9b.jpg)
考虑到移动网络受限的计算能力,对于移动网络迄今为止最流行的注意力机制仍然是Squeeze-and-Excitation(SE)注意力。它通过二维全局池化来计算通道注意力,以相当低的计算成本实现了明显的表现的提升。然而,SE注意力只考虑了通道之间的信息编码而忽略了位置信息的重要性,而这在视觉任务中对于捕获目标的结构又是至关重要的。之后的工作,比如BAM
和CBAM试图通过降低输入张量的通道维数,然后使用卷积计算空间注意力来利用位置信息,如图2(b)所示。然而,卷积只能捕获局部关系,而不能对视觉任务所必需的长期依赖关系进行建模。
在本文中,除了第一项工作之外,我们提出了一种新颖有效的注意力机制,通过将位置信息嵌入到通道注意力中,使移动网络能够关注大区域,同时避免产生显著的计算开销。为了缓解二维全局池化造成的位置信息的损失,我们将通道注意力分解为两个并行的一维特征编码过程,以有效地整合空间坐标信息到生成的注意力图。具体来说,我们的方法利用两个一维全局池化操作,分别将垂直和水平方向的输入特征聚合到两个独立的方向感知特征映射中。这两个嵌入了特定方向信息的特征图被分别编码成两个注意图,每个注意图捕获输入特征图沿一个空间方向的远程依赖关系。因此,位置信息可以保存在生成的注意力图中。然后,通过乘法将两个注意图应用于输入特征图,以强调感兴趣的表示。我们将提出的注意方法命名为坐标注意力,因为它的操作区分空间方向(即坐标)并生成感知坐标的注意力图。
我们的坐标注意力有以下的优点。首先,它不仅可以捕获跨通道信息,还可以捕获方向感知和位置敏感信息,这有助于模型更准确地定位和识别感兴趣的对象。其次,我们的方法灵活且轻量级,可以很容易地插入到移动网络的经典构建块中,例如MobileNetV2中提出的倒残差块和MobileNeXt[49]中提出的沙漏块,通过强调信息表示来增强特征。第三,作为一个预训练模型,我们的坐标关注力可以为移动网络的下游任务带来显著的性能提升,特别是对于那些具有密集预测的任务(例如,语义分割),我们将在我们的实验部分中展示。为了证明所提出的方法相对于之前移动网络注意力方法的优势,我们在ImageNet分类和流行的下游任务(包括目标检测和语义分割)中进行了广泛的实验。在相近的可学习参数量和计算量的情况下,我们的网络在ImageNet的 top-1分类准确率上实现了0.8%的性能提升。在目标检测和语义分割中,我们相比使用了在图一中展示的其他注意力机制的模型也有明显的提升。在未来,我们希望我们所提出的简单且高效的设计可以促进移动网络中注意力机制的发展。
2.相关工作
在本节中,我们对本文进行了简要的文献综述,包括之前关于高效网络架构设计和非局部注意力模型的研究。
2.1 移动网络架构
最近的最先进的移动网络大部分都是基于深度可分离卷积和逆残差块。 HBONet将下采样操作引入每个逆残差块来建模典型的空间信息。ShuffleNetV2在逆残差块的前后分别使用了一个通道分割模块和一个通道变换模块。之后,MobileNetV3结合神经架构搜索算法来搜索不同深度倒残差块的最优激活函数和扩展比。最近,Zhou等人重新思考了深度可分离卷积的利用方式,提出MobileNeXt,该方法采用了移动网络的经典瓶颈结构。
2.2注意力机制
注意力机制已被证明在各种计算机视觉任务中是有用的,例如图像分类和图像分割。一个成功的例子是SENet,它通过简单地压缩每个2D特征图来有效地建立通道之间的相互依赖关系。CBAM通过引入具有大尺寸卷积核对空间信息编码进一步推动了这一思路。后来的研究如GENet、GALA、AA和TA通过采用不同的空间注意机制或设计先进的注意力块扩展了这一思路。
非局部/自注意力网络由于其建立空间或通道注意力的能力最近非常受欢迎。典型的例子包括NLNet、GCNet、A2Net、SCNet、GSoP - Net或CC-Net,它们都利用了非局部机制捕获不同类型的空间信息。然而,由于自关注力模块内部的计算量很大,因此通常只适用于在大型模型中采用,而不适用于移动网络。
与这些利用昂贵且重的非局部或自关注力块的方法不同,我们的方法考虑了一种更有效的方法来捕获位置信息和通道之间的关系,以增强移动网络的特征表示。通过将2D全局池化操作分解为两个一维编码过程,我们的方法比其他具有轻量级属性的注意力方法执行得更好。(比如,SENet , CBAM和 TA )
3.坐标注意力
坐标注意力块可以被视作一个用来增强移动网络所学习到的特征的表达能力的计算单元。它可以取任意中间特征张量 X = [ x 1 , x 2 , … x c ] ∈ R C × H × W X = [x_1, x_2,…x_c] \in \Bbb R^{C \times H \times W} X=[x1,x2,…xc]∈RC×H×W作为输入然后输出一个增广表示的变换张量 Y = [ y 1 , y 2 , . . . , y c ] Y=[y_1,y_2,...,y_c] Y=[y1,y2,...,yc],其大小和 X X X一样。为了清晰地描述所提出的坐标注意力,我们首先回顾在移动网络中广泛使用的SE注意力。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第2张图片](http://img.e-com-net.com/image/info8/af5706cd4a1e466b841d6bc02e7237eb.jpg)
3.1 回顾“挤压-激发”注意力
正如[18]中所展示的,标准的卷积本身很难对通道之间的关系建模。显式地构建通道相互依赖关系可以提高模型对最终分类决策贡献更大的信息通道的敏感性。此外,使用全局平均池化也可以帮助模型捕获卷积所缺乏的全局信息。
在结构上,SE块可分解为压缩和激励两个步骤,分别用于全局信息嵌入和通道关系的自适应重新校准。给定输入 X X X,对于第 c c c个通道的压缩步骤可以被表示为下述公式:
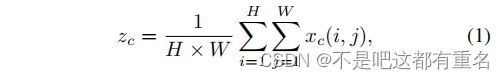
其中 z c z_c zc是与第 c c c个通道相关的输出。输入 X X X直接来自于一个有固定核大小的卷积层,因此可以看作是局部描述的一个集合。挤压操作使得收集全局信息成为可能。
第二步,激励,旨在完全捕获通道相关关系,可以表示为
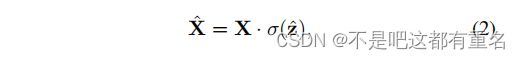
其中 . . .表示通道方向的乘法, σ \sigma σ表示sigmoid函数,而 z ^ \hat z z^是通过变换函数生成的结果,可以表示为:

其中, T 1 T_1 T1和 T 2 T_2 T2是两个可以学习的线性变换用来捕获每个通道的重要性。
SE模块已广泛应用于最近的移动网络而且被证明是实现最先进性能的关键组件。然而,它只考虑通过建模通道关系来重新权衡每个通道的重要性,而忽略了位置信息,正如我们将在第4节中通过实验证明的那样,位置信息对于生成空间选择性注意图也是重要的。在下面,我们介绍了一种新的注意块,它同时考虑了通道间关系和位置信息。
3.2 坐标注意力模块
我们的坐标注意力通过两个步骤用精确的位置信息编码通道关系和远程依赖关系:坐标信息嵌入与坐标注意力生成。所提出的坐标注意力块示意图如图2的右侧所示。在下面,我们将详细描述它。
3.2.1 坐标信息嵌入
全局池化通常用于通道注意力的全局空间信息编码,但它将全局空间信息压缩到通道描述符中,难以保留位置信息,而这对于视觉任务中空间结构的捕获至关重要。为了鼓励注意力块在空间上用精确的位置信息捕获远程交互,我们将全局池化分解为公式(1)中所表述的一对一维特征编码操作。具体来说,给定输入X,我们使用两个空间范围(H, 1)或(1,W)的池化核分别沿水平坐标和垂直坐标方向对每个通道进行编码。因此,第c个通道在高h处的输出可以表示为:
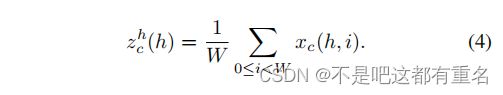
相似的,第c个通道在宽w处的输出可以表示为:
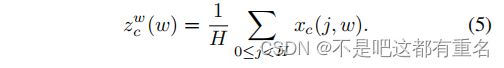
上述两种变换分别沿着两个空间方向聚合特征,产生一对方向感知特征映射。这与公式1产生单个特征向量的通道注意力方法中的挤压操作相当不同。这两种变换还允许我们的注意力块在一个空间方向上捕获远程依赖关系,并在另一个空间方向上保留精确的位置信息,这有助于神经网络更准确地定位感兴趣的对象。
3.2.2 坐标注意力生成
正如之前描述的,公式4和公式5使用了全局感受野然后对精确的位置信息编码。为了充分利用由此产生的丰富的表征,我们提出了第二种变换,称为坐标注意力生成。我们的设计参考了以下三个标准。首先,对于移动环境中的应用程序,新的变换应该尽可能简单和廉价。其次,它可以充分利用捕获的位置信息,从而准确地突出显示感兴趣的区域。最后但并非最不重要的是,它还应该能够有效地捕捉通道间关系,这在现有研究中已被证明是必不可少的。
具体来说,给定由公式4和公式5生成的聚合特征映射,我们首先将它们连接起来,然后将它们输入到共享的1 × 1卷积变换函数 F 1 F_1 F1,得到

其中 [ . , . ] [.,.] [.,.]表示沿着空间维度的连接操作, δ \delta δ是一个非线性激活函数, f ∈ R C / r × ( H + W ) f \in \Bbb R^{C/r \times (H+W)} f∈RC/r×(H+W)是在水平方向和垂直方向对空间信息进行编码的中间特征映射。这里,r是和SE块相同的控制块大小的缩放比。然后我们沿着空间维度把f分成两个张量 f h ∈ R C / r × ( H ) f^h \in \Bbb R^{C/r \times (H)} fh∈RC/r×(H)和 f w ∈ R C / r × ( W ) f^w \in \Bbb R^{C/r \times (W)} fw∈RC/r×(W)。另外的两个1x1卷积变换 F h F_h Fh和 F w F_w Fw被用于分别将 f h f_h fh和 f w f_w fw转换为与输入X具有相同通道数的张量,
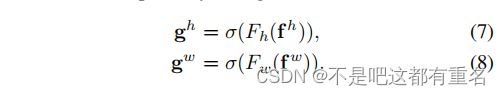
回想一下 δ \delta δ是sigmoid函数。为了降低模型的复杂度,我们通常通过一个合适的缩放比 r r r来降低 f f f的通道数。我们将在实验部分讨论不同的缩放比对性能的影响。输出 g h g^h gh和 g w g^w gw分别展开并用作注意力权重。最后,我们的坐标注意力块的输出 Y Y Y可以写成
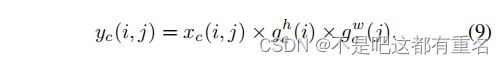
讨论不同于通道注意力只关注于重新权衡不同通道的重要性,我们的坐标注意块还考虑了空间信息的编码。如上所述,水平方向和垂直方向的注意力同时被施加到输入张量上。两个注意图中的每个元素反映了感兴趣的对象是否存在于相应的行和列中。这个编码过程可以让我们的坐标注意力更准确地定位感兴趣对象的确切位置,从而帮助整个模型更好地识别。我们将在实验部分详细地演示这一点。
3.3 实现
由于本文的目标是研究一种更好的方法来增强移动网络的卷积特征,在这里我们采用两种经典的轻量级架构,它们具有不同类型的残差块(即MobileNetV2和MobileNeXt)作为例子来证明所提出的坐标注意力块相对于其他著名的轻量化注意力块的优势。图3显示了我们如何将注意力块插入到MobileNetV2的逆残差块中和MobileNeXt的沙漏块中。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第3张图片](http://img.e-com-net.com/image/info8/a92e2c8fed2c469ebf9028de7c5776de.jpg)
4.实验
在本节中,我们首先描述了我们的实验设置,然后进行了一系列消融实验,以证明在所提出的坐标注意力中每个组成部分对性能的贡献。接下来,我们将我们的方法与一些基于注意力的方法进行比较。最后,我们报告了提出的方法与其他基于注意力的方法在目标检测和语义分割方面的对比结果。
4.1实验设置
我们使用PyTorch工具箱来实现我们所有的实验。在训练过程中,我们使用了衰减和动量为0.9的标准SGD优化器来训练所有模型。权重衰减始终设置为 4 × 1 0 − 5 4\times10^{−5} 4×10−5。采用初始学习率为0.05的余弦学习计划。我们使用四个NVIDIA GPU进行训练,批处理大小设置为256。没有额外的声明,我们采取MobileNetV2作为我们的基线,并训练所有的模型200轮。对于数据增强,我们使用与MobileNetV2相同的方法。我们展示了ImageNet数据集的分类结果。
4.2消融实验
坐标注意力的重要性为了证明所提出的坐标注意力的性能,我们进行了一系列消融实验,相应的结果列于表1。我们从坐标注意中去除水平注意力或垂直注意力,以了解编码坐标信息的重要性。正如表1中所示,使用了任意一个方向上的注意力的模型与用SE注意力的模型都有相近的性能表现。然而,当同时考虑水平注意力和垂直注意力时,我们得到的最佳结果如表1所示。实验结果表明,在可学习参数和计算成本相当的情况下,嵌入坐标信息对图像分类更有帮助。
不同的权重乘数在这里,我们以两个经典的移动网络(包括带有倒残差块的MobileNetV2和带有沙漏瓶颈块的MobileNeXt)为基准来看本文所提出的方法相比SE注意力和CBAM在不同权重乘数下的性能。在本实验中,我们采用三种典型的权重乘数,分别为{1.0,0.75,0.5}。如表2所示,当以MobileNetV2网络为基准时,CBAM模型与SE注意模型的结果相似。然而,使用了所提出的坐标注意力的模型在每种设置下都能产生最好的结果。正如表3所示,在使用MobileNeXt网络作为基准时,也可以观察到类似的现象。这表明,无论是沙漏瓶颈块还是逆残差块,无论选择哪个权重乘数,由于我们采用了先进的方法同时对位置信息和通道间信息进行编码,我们的坐标注意力都表现得最好。
缩放比r的影响为了研究不同的注意力块缩放比例对模型性能的影响,我们尝试减小缩放比例的大小然后观察性能的变化。如表4所示,当我们将r减小到原始大小的一半时,模型大小会增加,但可以产生更好的性能。这表明,通过降低缩放比来增加更多的参数对于提高模型性能很重要。更重要的是我们的坐标注意力依旧在这个实验中比SE注意力和CBAM表现得更好,反映了所提出的坐标注意力对缩放比的鲁棒性。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第4张图片](http://img.e-com-net.com/image/info8/5bf77db8bf404f6b8dc7cb40314a74d5.jpg)
4.3 与其他方法的比较
移动网络中注意力我们将坐标注意力与移动网络的其他轻量级注意力方法进行了比较,包括表二中广泛使用的SE注意力和CBAM。可以看出,添加SE关注已经使分类性能提高了1%以上。对于CBAM而言,图2(b)所示的空间注意力模块在移动网络中的贡献似乎不如SE注意力。然而,当考虑到所提出的坐标注意力时,我们得到了最好的结果。我们还在图4中可视化了使用不同注意力方法的模型产生的特征图。很明显,我们的坐标注意力在定位感兴趣的物体时比视觉注意力更有帮助
SE注意和CBAM。
我们认为所提出的坐标信息编码方式相对于CBAM具有双重优势。首先,CBAM中的空间注意力模块把通道维度压缩为1,导致信息的丢失。然而,我们的坐标注意力在瓶颈处使用适当的缩放比来降低通道维度,避免过多的信息丢失。其次,CBAM利用一个核大小为7 × 7的卷积层来编码局部空间信息,而我们的坐标注意力通过两个互补的一维全局池化操作来编码全局信息。这使得我们的坐标注意力能够捕捉对视觉任务至关重要的空间位置之间的远程依赖关系。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第5张图片](http://img.e-com-net.com/image/info8/c881ef08ec98419180682a3dd3f1c0a0.jpg)
更强的基线
为了进一步证明在更强大的移动网络中所提出的坐标注意力相对于SE注意力的优势,我们采用了EfficientNet-b0作为我们的基线。EfficientNet基于架构搜索算法并包含SE注意力。为了研究所提出的坐标注意力在EfficientNet上的性能,我们只是将SE注意力替换为我们所提出的坐标注意力。对于其他设置,我们遵循原论文。结果已列于表5。与原来的包含SE注意的EfficientNet-b0和其他方法相比,在有相近的可训练参数和计算量的条件下,我们的使用了坐标注意力的网络实现了最好的结果。这表明所提出的坐标注意力在强大的移动网络中仍然可以很好地发挥作用。
4.4应用
在本节中,我们对目标检测任务和语义分割任务进行了实验,以探索所提出的坐标注意力相对于其他注意力方法的迁移能力。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第6张图片](http://img.e-com-net.com/image/info8/51ea53b3624648389552a75e5b0c9ebe.jpg)
4.4.1 目标检测
实现细节
我们的代码基于PyTorch和SSDLite。照着[34],我们将SSDLite的第一层和第二层分别连接到输出步长为16和32的最后一个点向卷积,并将其余的SSDLite层添加到最后一个卷积层的顶部。在COCO上训练时,我们将批大小设置为256并使用同步的批量归一化。采用初始学习率为0.01的余弦学习曲线。我们训练了总共1,600,000轮。当在Pascal VOC上训练时,批大小被设置为24,所有模型都被训练了24万次迭代。权重衰减设置为0.9。初始学习率为0.001,然后在16万次迭代和20万次迭代时将其除以10。其他设置可参考[34,26]。
COCO上的结果
在本次实验中,我们沿用了之前的大部分工作,分别展示了AP, A P 5 0 AP_50 AP50, A P 7 5 AP_75 AP75, A P S AP_S APS, A P M AP_M APM和 A P L AP_L APL指标的结果。在表6中,我们显示了COCO2017年验证集上不同网络设置产生的结果。很明显,在MobileNetV2中加入坐标注意力可以显著提高检测结果(24.5 vs . 22.3),而只需要0.5M的参数开销和几乎相同的计算成本。与其他轻量级注意力方法相比,例如SE注意力和CBAM,我们的SSDLite320版本在几乎相同数量的参数和计算中实现了所有指标的最佳结果。
此外,我们还展示了基于SSDLite320的之前的最先进模型产生的结果,如表6所示。注意,一些方法(例如,MobileNetV3和MnasNet-A1)是基于神经架构搜索方法的,但我们的模型不是。显然,在AP方面,我们的检测模型与其他参数和计算接近的方法相比,取得了最好的结果。
在Pascal VOC上的结果
表7给出了采用不同的注意力方法对Pascal VOC 2007测试集的检测结果。我们观察到SE注意力和CBAM不能改善基线结果。然而,增加了提出的坐标注意力可以大大提高平均AP从71.7到73.1。在COCO和Pascal VOC数据集上的检测实验表明,与其他注意力方法相比,采用坐标注意力的分类模型具有更好的可迁移性。
4.4.2 语义分割
我们还进行了语义分割实验。遵循MobileNetV2,我们使用经典的DeepLabV3为例,并将所提出的方法与其他模型进行比较,以证明所提出的坐标注意力在语义分割中的可迁移能力。具体来说,我们丢弃最后一个线性算子,并将ASPP连接到最后一个卷积算子。考虑到移动应用,我们用深度可分离卷积取代了标准的3 × 3卷积算子,以减小模型的大小。ASPP中每个分支的输出通道设置256,ASPP中的其他组件保持不变(包括1×1卷积分支和图像级特征编码分支)。我们展示了两个广泛使用的语义分割基准的结果,包括Pascal VOC 2012和cityscape。对于实验设置,除了权重衰减设置为4e-5外,其他参数的设置我们严格遵循DeeplabV3论文。当输出步幅设置为16时,ASPP中的膨胀率为{6,12,18};当输出步幅设置为8时,ASPP中的膨胀率为{12,24,36}。
Pascal VOC 2012上的结果
Pascal VOC 2012分割基准包括一个背景类在内共有21个类。按照原文的建议,我们使用1464张图片的分割进行训练,1449张图片的分割进行验证。此外,正如之前的大多数工作所做的那样,我们通过添加来自[12]的额外图像来增强训练集,得到总共10,582张用于训练的图像。
我们在表8中展示了不同模型作为主干时的分割结果。我们在16和8两种不同的输出步长下展示了结果。注意,这里报告的所有结果都不是基于COCO预训练的。从表8中可以看出,配备了我们的坐标注意力的模型比原始的和使用了其他注意力方法的MobileNetV2表现要好得多。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第7张图片](http://img.e-com-net.com/image/info8/92b647763fff4c0f90dd46beb3614f22.jpg)
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第8张图片](http://img.e-com-net.com/image/info8/05e7810943d5405380e36e035cf618ae.jpg)
Cityscapes上的结果
cityscapes是一个著名的城市街景分割数据集,合计包含19个不同的类别。按照官方的建议,我们使用2975张图片进行训练,500张图片进行验证。只使用经过精细标注的图像进行训练。在训练中,我们随机裁剪原始图像到768×768。在测试过程中,所有图像保持原始大小(1024 × 2048)。
在表9中,我们展示了Cityscapes数据集上使用不同注意力方法的模型的分割结果。与原始的和使用了其他注意力方法的MobileNetV2相比,我们的坐标注意力可以在可学习参数数量相当的情况下大幅度提高分割结果。
讨论我们观察到,与ImageNet分类和目标检测相比,我们的坐标注意力在语义分割方面产生了更大的改进。我们认为这是因为我们的坐标注意力能够通过精确的位置信息捕获远程依赖关系,这更有利于具有密集预测的视觉任务,例如语义分割。
![[论文阅读]Coordinate Attention for Efficient Mobile Network Design_第9张图片](http://img.e-com-net.com/image/info8/5e6fec66d7c8434894ff6b85afc93474.jpg)
5.结论
本文提出了一种新的移动网络轻量级注意力机制——坐标注意力。我们的坐标注意力继承了通道注意力方法可以建模通道间关系的优点的同时可以实现用精确的位置信息捕获远距离依赖。在ImageNet分类、目标检测和语义分割方面的实验证明了该方法的有效性。