智慧城市道路通行时间预测(笔记未完成版)
数据与任务目标分析
数据
道路通行时间
当前道路在该时间段内有车通行的时间
道路长宽情况
道路连接情况
任务
基于历史数据预测某个时间段内,如预测未来一个月travel_time, 每2分钟内通行时间。
构建时间序列,基于时间序列预测
预测高峰点(如6 7 8 13 14 15 16 17 18 点)的车流量,不用预测每个点
数据预处理
缺失值
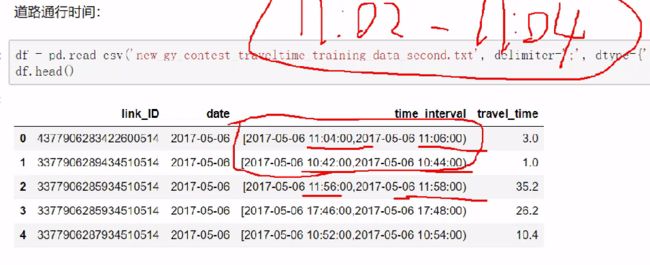
数据集筛选与标签转换
数据集中有些数据可能由于异常情况导致不适合建模(堵车,维修等)
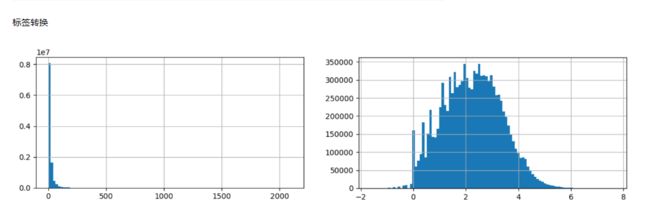
*标签 数据不呈正太分布,取log值进行转换
df = df.drop(['time_interval'], axis=1)
df['travel_time'] = np.log1p(df['travel_time'])
- 筛选离群点
#剔除掉一些离群点
def quantile_clip(group):
group[group < group.quantile(.05)] = group.quantile(.05)
group[group > group.quantile(.95)] = group.quantile(.95)
return group
#对每条道路,每天执行
df['travel_time'] = df.groupby(['link_ID', 'date'])['travel_time'].transform(quantile_clip)
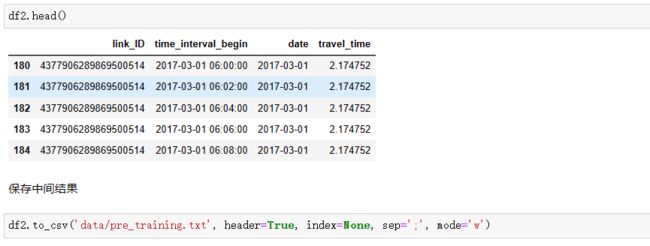
df.head(5)
- 根据需求来选择样本数据
#根据需求来选择样本数据
df = df.loc[(df['time_interval_begin'].dt.hour.isin([6, 7, 8, 13, 14, 15, 16, 17, 18]))]
项目仅需针对部分高峰时刻进行预测,所以只要选择相应时间的数据即可。
缺失值处理
- 数据存在缺失,如时间段不连续
建立连续的时间序列数据,再与原来的数据进行合并
df = pd.read_csv('data/raw_data.txt', delimiter=';', parse_dates=['time_interval_begin'], dtype={'link_ID': object})
df.head()
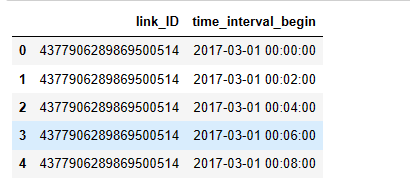
- 构建时间序列数据,原始数据表中没有列出的数据均需要填充
date_range = pd.date_range("2017-03-01 00:00:00", "2017-07-31 23:58:00", freq='2min')
date_range[:5]

new_index = pd.MultiIndex.from_product([link_df['link_ID'].unique(), date_range],
names=['link_ID', 'time_interval_begin'])
new_df = pd.DataFrame(index=new_index).reset_index()
new_df.head()
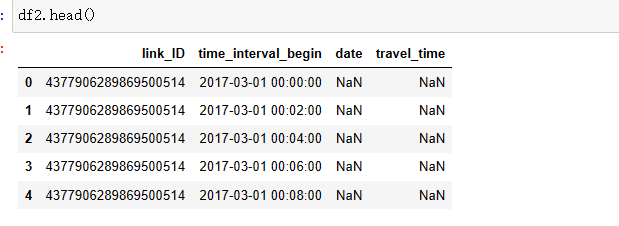
#合并,出现大量缺失值
df2 = pd.merge(new_df, df, on=['link_ID', 'time_interval_begin'], how='left')
- 筛选所需时间段数据
df2 = df2.loc[(df2['time_interval_begin'].dt.hour.isin([6, 7, 8, 13, 14, 15, 16, 17, 18]))]
df2 = df2.loc[~((df2['time_interval_begin'].dt.year == 2017) & (df2['time_interval_begin'].dt.month == 7) & (
df2['time_interval_begin'].dt.hour.isin([8, 15, 18])))]
df2 = df2.loc[~((df2['time_interval_begin'].dt.year == 2017) & (df2['time_interval_begin'].dt.month == 3) & (
df2['time_interval_begin'].dt.day == 31))]
df2['date'] = df2['time_interval_begin'].dt.strftime('%Y-%m-%d')
补全时间序列
- 用回归算法预测
- 用插值填充
df = pd.read_csv('data/pre_training.txt', delimiter=';', parse_dates=['time_interval_begin'], dtype={'link_ID': object})
df['travel_time2'] = df['travel_time']
df.head()
多个月统计-季节性变化-小时
def date_trend(group):
tmp = group.groupby('date_hour').mean().reset_index()
def nan_helper(y):
return np.isnan(y), lambda z: z.nonzero()[0]
y = tmp['travel_time'].values
nans, x = nan_helper(y)
if group.link_ID.values[0] in ['3377906282328510514', '3377906283328510514', '4377906280784800514',
'9377906281555510514']:
tmp['date_trend'] = group['travel_time'].median()
else:
regr = linear_model.LinearRegression()
regr.fit(x(~nans).reshape(-1, 1), y[~nans].reshape(-1, 1))
tmp['date_trend'] = regr.predict(tmp.index.values.reshape(-1, 1)).ravel()
group = pd.merge(group, tmp[['date_trend', 'date_hour']], on='date_hour', how='left')
return group
df['date_hour'] = df.time_interval_begin.map(lambda x: x.strftime('%Y-%m-%d-%H'))
df.head()

蓝线回归得到的值存在df[‘date_trend’]里,此时travel_time就更新为df[‘travel_time’] = df[‘travel_time’] - df[‘date_trend’],表示date_trend作为大的趋势已经被线性回归决定了,剩下的就是研究这个残差了,之后训练和预测都是基于残差,最后用预测出来的残差加上相应的date_trend即可得到需要的预测值
df = df.drop(['date_hour', 'link_ID'], axis=1)
df = df.reset_index()
df = df.drop('level_1', axis=1)
df['travel_time'] = df['travel_time'] - df['date_trend']
df.head()
日变化量(分钟)
- 插值法
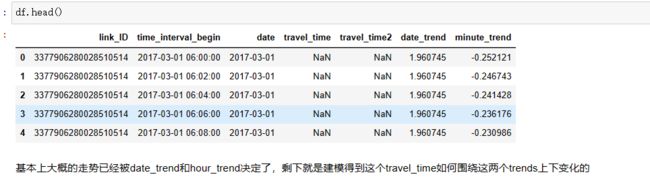
def minute_trend(group):
tmp = group.groupby('hour_minute').mean().reset_index()
#s的值越小,对数据拟合越好,但是会过拟合的危险;
spl = UnivariateSpline(tmp.index, tmp['travel_time'].values, s=0.5) # s代表复杂度,s越小越容易过拟合?(待了解)
tmp['minute_trend'] = spl(tmp.index)
group = pd.merge(group, tmp[['minute_trend', 'hour_minute']], on='hour_minute', how='left')
return group
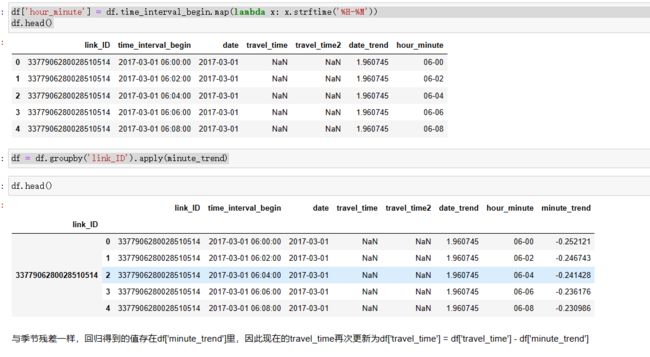
df['hour_minute'] = df.time_interval_begin.map(lambda x: x.strftime('%H-%M'))
df.head()

df = df.drop(['hour_minute', 'link_ID'], axis=1)
df = df.reset_index()
df = df.drop('level_1', axis=1)
df['travel_time'] = df['travel_time'] - df['minute_trend']
其他因素/特征的影响
- 选择训练特征
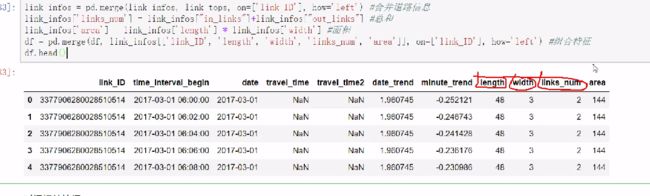
link_infos = pd.read_csv('gy_contest_link_info.txt', delimiter=';', dtype={'link_ID': object})
link_tops = pd.read_csv('gy_contest_link_top.txt', delimiter=',', dtype={'link_ID': object})
link_infos = pd.merge(link_infos, link_tops, on=['link_ID'], how='left') #合并道路信息
link_infos['links_num'] = link_infos["in_links"]+link_infos["out_links"] #总和
link_infos['area'] = link_infos['length'] * link_infos['width'] #面积
df = pd.merge(df, link_infos[['link_ID', 'length', 'width', 'links_num', 'area']], on=['link_ID'], how='left') #组合特征
df.head()
- 时间相关特征
- 节假日判断
df.loc[df['date'].isin(
['2017-04-02', '2017-04-03', '2017-04-04', '2017-04-29', '2017-04-30', '2017-05-01',
'2017-05-28', '2017-05-29', '2017-05-30']), 'vacation'] = 1
df.loc[~df['date'].isin(
['2017-04-02', '2017-04-03', '2017-04-04', '2017-04-29', '2017-04-30', '2017-05-01',
'2017-05-28', '2017-05-29', '2017-05-30']), 'vacation'] = 0
df['minute'] = df['time_interval_begin'].dt.minute
df['hour'] = df['time_interval_begin'].dt.hour
df['day'] = df['time_interval_begin'].dt.day
df['week_day'] = df['time_interval_begin'].map(lambda x: x.weekday() + 1)
df['month'] = df['time_interval_begin'].dt.month
df.head()
- linkID 是否可做特征
可不用做特征
如果
序列补全
标准化
def std(group):
group['travel_time_std'] = np.std(group['travel_time'])
return group
df = df.groupby('link_ID').apply(std)
df['travel_time'] = df['travel_time'] / df['travel_time_std']
df.head()
get_dummies
本项目中影响不大
建设回归模型来预测缺失值
params = {
'learning_rate': 0.2,
'n_estimators': 30,
'subsample': 0.8,
'colsample_bytree': 0.6,
'max_depth': 10,
'min_child_weight': 1,
'reg_alpha': 0,
'gamma': 0
}
df = pd.get_dummies(df, columns=['links_num', 'width', 'minute', 'hour', 'week_day', 'day', 'month'])
df.head()
训练的数据train_df 为travel_time非空的数据,而测试集test_df为travel_time空的数据
feature = df.columns.values.tolist()
train_feature = [x for x in feature if
x not in ['link_ID', 'time_interval_begin', 'travel_time', 'date', 'travel_time2', 'minute_trend',
'travel_time_std', 'date_trend']]
train_df = df.loc[~df['travel_time'].isnull()]
test_df = df.loc[df['travel_time'].isnull()].copy()
print (train_feature)
训练数据切分
X = train_df[train_feature].values
y = train_df['travel_time'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
eval_set = [(X_test, y_test)]
regressor = xgb.XGBRegressor(learning_rate=params['learning_rate'], n_estimators=params['n_estimators'],
booster='gbtree', objective='reg:linear', n_jobs=-1, subsample=params['subsample'],
colsample_bytree=params['colsample_bytree'], random_state=0,
max_depth=params['max_depth'], gamma=params['gamma'],
min_child_weight=params['min_child_weight'], reg_alpha=params['reg_alpha'])
regressor.fit(X_train, y_train, verbose=True, early_stopping_rounds=10, eval_set=eval_set)
print (test_df[train_feature].head())
print (test_df[train_feature].info())
test_df['prediction'] = regressor.predict(test_df[train_feature].values)
df = pd.merge(df, test_df[['link_ID', 'time_interval_begin', 'prediction']], on=['link_ID', 'time_interval_begin'],
how='left')
feature_vis(regressor,train_feature)

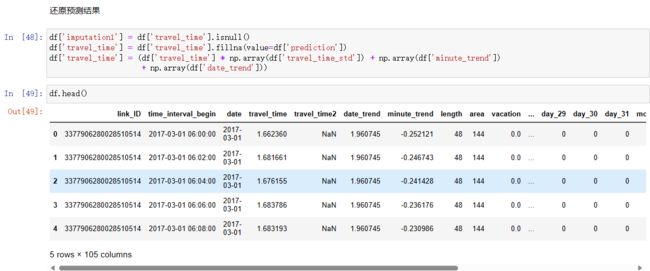
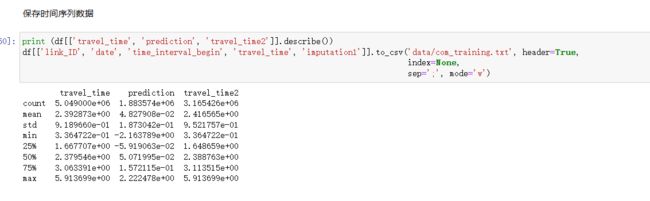
构建特征
TIPS
- 减去季节趋势项后预测残差,最后再加上趋势项
- 季节趋势项包含:日、时 等方面
- 利用回归模型来预测缺失值,建立完整的序列数据