spark6. 如何设置spark 日志
spark yarn日志全解
-
- 一.前言
- 二.开启日志聚合是什么样的
-
- 2.1 开启日志聚合MapReduce history server
- 2.2 如何开启Spark history server
- 三.不开启日志聚合是什么样的
- 四.正确使用log4j.properties
一.前言
本文只讲解再yarn 模式下的日志配置。
二.开启日志聚合是什么样的
在yarn模式下,executor 进程和ApplicationMaster进程都会运行在containers中。YARN 有两种方式处理 container logs(也就是我们的spark日志)开启日志聚合和不开启日志聚合
- MapReduce history server :
是hadoop yarn的日志聚合服务,会把运行结束后的任务日志放在hdfs 上,复制完成后则每台机器上的本地日志就会被删除。 另外hdfs上 的所有日志可以设置保留一定时间,避免占用太多磁盘空间。此服务一般用19888端口 - Spark history server
是spark的 ui页面, 默认spark只运行中才可以打开ui, 要想查看所有的历史任务的ui则必须开启此服务
在Spark history server 中查看运行日志会重定向到MapReduce history server 中。 此服务一般用18080端口
2.1 开启日志聚合MapReduce history server
yarn-site.xml
<property>
<!--开启日志聚合-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--聚合的日志保留时间>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<!--聚合的日志存储位置>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yarn/${yarn.resourcemanager.cluster-id}/logs</value>
</property>
<property>
<!-- 此配置是为了spark ui可以看到日志>
<name>yarn.log.server.url</name>
<value>http://master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:19888/jobhistory/logs</value>
</property>
mapred-site.xml
<property>
<!--mapreduce job日志历史日志服务地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:10020</value>
</property>
启动 MapReduce history server服务 sbin/mr-jobhistory-daemon.sh start historyserver
则在程序结束之后container logs 会被copy到hdfs上,此时要查看日志可以通过:yarn logs -applicationId , 要注意的是当任务是accept的时候这个命令是没有日志的,因为还未分配containers, 另一个值得注意的是这个命令会打印出当前运行的日志,但是不是实时跟踪的。也可以使用 HDFS shell or API 来查看日志,这里不做过多解释。
The logs are also available on the Spark Web UI under the Executors Tab
but you have both the Spark history server and the MapReduce history server running and configure yarn.log.server.url in yarn-site.xml properly
这句话的意思是说在spark ui也是可以看到日志,前提条件是开始Spark history server and the MapReduce history server 并在yarn-site.xml 中配置yarn.log.server.url。
值得注意的是spark本身不存储日志, 当在sparkui 查看日志的时候,也是重定向到yarn.log.server.url。
2.2 如何开启Spark history server
spark ui默认只展示正在运行的任务,如果想展示所有的任务,则需要开启Spark history server
- 打开hdfs-site.xml 找到如下配置查看端口,我的配置中是9000
dfs.namenode.rpc-address.hdfs-cluster.nn1
mast-ip:9000
- spark-default.conf 添加如下配置:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mast-ip:9000/spark-history #注意端口为上面找到的端口
spark.yarn.historyServer.address mast-ip:18080 #spark history 的webui
- ./sbin/start-history-server.sh (进入master 的spark安装目录的sbin中执行此命令)
- 打开 mast-ip:18080 (spark的history server)
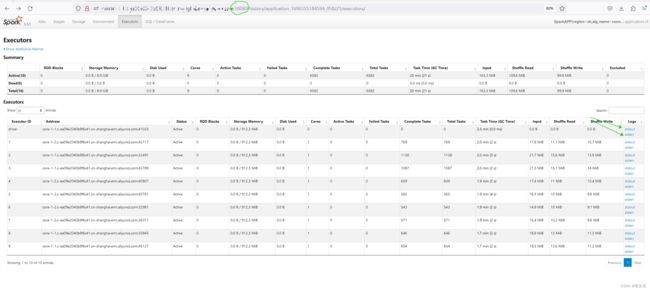
仔细看途中的绿色箭头,点击之后会重定向到:mast-ip:19888, 这正是hadoop yarn 的history server 地址。这也证明了spark本身不存储日志。
三.不开启日志聚合是什么样的
当日志聚合不打开的时候,再yarn运行的任务日志被保留在每个container所在的机器上,这个日志目录由以下参数决定:
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/mnt/disk1/yarn/userlogs,/mnt/disk2/yarn/userlogs</value>
</property>
这些日志路径中包含applicationID 和containerID,很容易找到,这些日志再 Spark Web UI也能看到 并且不需要启动hadoop的
MapReduce history server。
在本地不止有日志,为了方便追溯历史任务的执行信息,还缓存了任务执行的需要的各种信息,比如filecache,
甚至还可以找到曾经任务的启动脚本(如下) 缓存时间通过:yarn.nodemanager.delete.debug-delay-sec设置( 在任务结束多长时间后,删除本地化的日志缓存【缓存包含启动命令脚本文件, jar缓存文件,日志等】) 此设置需要重启集群。
缓存时间通过:yarn.nodemanager.delete.debug-delay-sec设置( 在任务结束多长时间后,删除本地化的日志缓存【缓存包含启动命令脚本文件, jar缓存文件,日志等】) 此设置需要重启集群。
四.正确使用log4j.properties
- 配置全局log4j.properties
意思是所有的任务用同一个log4j.properties - 独立配置log4j.properties
考虑一个使用场景,比如我们想每个任务使用独立的log4j.proprtties, 且再log4j.properties中用自定义变量定义一个路径,
这样可以达到每个任务 输出到独立的文件中,方便我们做日志采集。
上面的场景就不适合用默认的log4j.properties了
如果想要使用自定义的log4j日志配置,需要下面几个步骤:
第一种写法带 –file
- 使用spark-submit的–files参数,上传自定义 log4j-driver.properties(名字随便)和log4j-executor.properties(名字随便)
- 使用 --conf spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j-driver.propertie
- 使用 --conf spark.executor.extraJavaOptions=-Dlog4j.configuration=log4j-executor.properties
第二种写法不带 –file, 要求配置文件在每台机器上都存在,且必须以file: 开头,意思是本地路径协议
- 使用 --conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:/…/…/…/log4j-driver.propertie
- 使用 --conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:/…/…/…/log4j-executor.properties
下面附上我自己用的一个例子:
spark-submit \
--master yarn \
--deploy-mode cluster \
--class alg.test.SparSocketDemo \
--conf spark.driver.extraJavaOptions="-Dlog4j2.formatMsgNoLookups=true -Ddriver.path=/driver/mm/ -Dlog4j.configuration=dr.log4j.properties -noverify -javaagent:/opt/apps/TAIHAODOCTOR/taihaodoctor-current/emr-agent/btrace-agent.jar=libs=spark-3.2" \
--conf spark.executor.extraJavaOptions="-Dlog4j2.formatMsgNoLookups=true -Dexecutor.path=/executor/mm/ -Dlog4j.configuration=ex.log4j.properties -noverify -javaagent:/opt/apps/TAIHAODOCTOR/taihaodoctor-current/emr-agent/btrace-agent.jar=libs=spark-3.2" \
--files /root/dr.log4j.properties,/root/ex.log4j.properties \
/root/JavaAndScala-1.0-SNAPSHOT.jar
下面是dr.log4j.properties ,仅供参考
# Set everything to be logged to the console
log4j.rootCategory=INFO, console, LOGFILE
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p [%t] %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
log4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN
# For deploying Spark ThriftServer
# SPARK-34128: Suppress undesirable TTransportException warnings involved in THRIFT-4805
log4j.appender.console.filter.1=org.apache.log4j.varia.StringMatchFilter
log4j.appender.console.filter.1.StringToMatch=Thrift error occurred during processing of message
log4j.appender.console.filter.1.AcceptOnMatch=false
log4j.appender.LOGFILE = org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File = /tmp/${driver.path}/driver.log
log4j.appender.LOGFILE.Append = true
log4j.appender.LOGFILE.layout = org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
注意我的LOGFILE 中有个 ${driver.path}, 这会接收启动命令中的 -Ddriver.path=/driver/mm/
这意味着 我的每次启动都通过-Ddriver.path=XXX 传递不同的路径,这样我的每个任务都会在不同的目录下生成日志文件。
我可以自定义appName 并将appName 凭借在上面的路径上,这在实际开发中很有意义。
大家可能会注意到上面的启动命令driver和executor分别用的不i同的log4j 配置文件, 这是为了防止driver的日志和executor混杂在一起。spark官网推荐我们这么做,这种自定义的方式还可以吧。并且我们只是在原来的基础加了一个 LOGFILE appender, 并未修log4j.properties本省的配置, 不会影响原本的日志聚合, 以及原本的日志采集。