Map接口
Map接口是用于存储键值对映射关系的接口。Map接口提供了一种通过键来访问值的方式,Map中的每个键都是唯一的,值可以重复。
Map接口常用实现类:HashMap、TreeMap,LinkedHashMap等。
HashMap
HashMap常用方法
构造方法
public HashMap( ):默认初始化容量是16,默认的加载因子是0.75,扩容比例是2倍扩容。
public HashMap( int initialCapacity ):可以对容量进行设置,加载因子默认是0.75.
常用方法
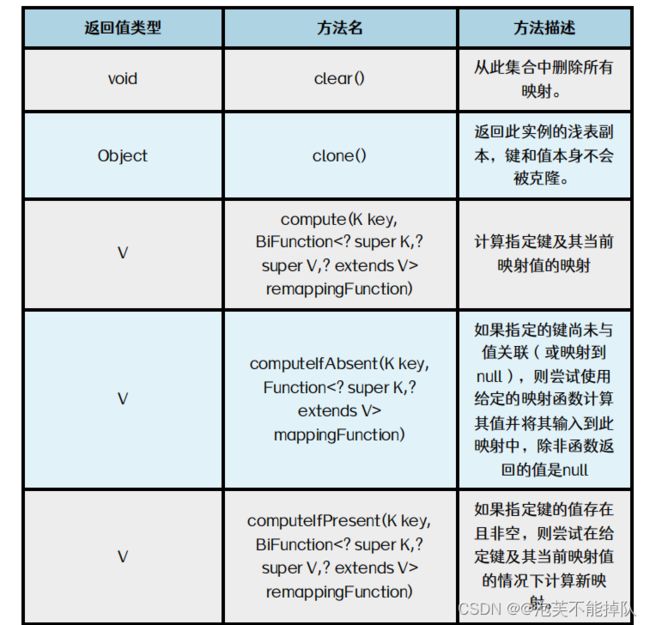
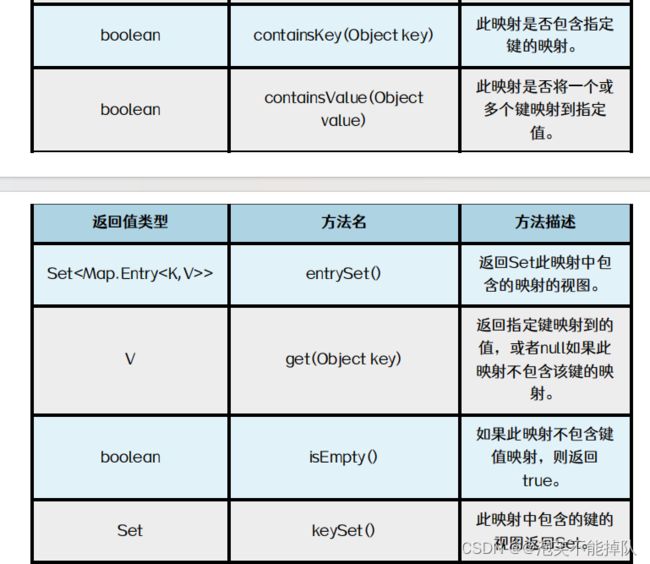
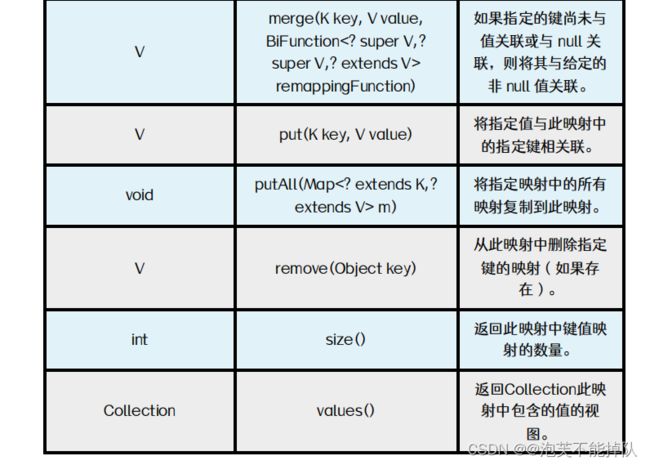
Map.of( ):返回一个不可修改的集合对象。
containsValues( ):需要重写equals方法。
put( ):如果key不存在映射,把key和value放进Map中,返回null,如果key存在,用新的value覆盖旧的value,并返回旧的value。
compute,computeIfAbsent,computeIfPresent三个方法的总结
compute(K key, BiFunction remappingFunction):无论key是否 存在,都会进入apply( )。
- 如果key存在,但是apply()方法返回的是null,这个key就会被删除。如果apply()返回的不是null,就会把返回值和key映射起来,hashMap.put(key,返回值)。
- 如果key不存在,apply( )方法返回的是非null,key就会和返回值映射起来,并且添加到集合中,hashMap.put(key,返回值)。如果apply()返回的是null,就不会添加映射。
HashMap hashMap = new HashMap<>();
hashMap.put(1, new TVPlay("甄嬛传", 74));
hashMap.put(2, new TVPlay("长风渡", 40));
hashMap.put(3, new TVPlay("莲花楼", 40));
hashMap.put(4, new TVPlay("长相思", 40));
hashMap.put(5, new TVPlay("长相思", 40));
TVPlay compute = hashMap.compute(6, new BiFunction() {
@Override
public TVPlay apply(Integer key, TVPlay value) {
System.out.println("key" + key);
System.out.println("value" + value);
// TVPlay hj = new TVPlay("回家的诱惑", 80);
return null;
}
});
System.out.println(compute); // null
System.out.println(hashMap.containsKey(6)); // false
System.out.println(hashMap.get(6)); // null
System.out.println(hashMap); computeIfAbsent(K key, Function mappingFunction)
- 当key不存在映射,或者映射为null时,也就是containsKey()返回true, get(key) == null才会执行apply方法。
- 如果apply()返回的是非null,key就会和返回值映射起来,添加到集合中。
- 如果apply()返回值是null,则apply()不做任何操作。
TVPlay tvPlay = hashMap.computeIfAbsent(7, new Function() {
@Override
public TVPlay apply(Integer key) {
System.out.println(key);
return new TVPlay("长月烬明", 40);
}
});
System.out.println(tvPlay); // 长月烬明
System.out.println(hashMap.containsKey(7)); // true
System.out.println(hashMap.get(7)); // 长月烬明 computeIfPresent(K key, BiFunction remappingFunction)
- 当key存在映射且非空,也就是containsKey()返回true, get(key) != null才会执行apply()方法。
- 如果apply()方法的返回值是null,则会删除这个key。
- 如果apply()方法的返回值不是null,key会和返回值映射起来,添加到集合中。
TVPlay t = hashMap.computeIfPresent(7, new BiFunction() {
@Override
public TVPlay apply(Integer integer, TVPlay tvPlay) {
System.out.println(integer);
System.out.println(tvPlay);
return new TVPlay("仙剑奇侠传", 37);
}
});
System.out.println(t); // 仙剑
System.out.println(hashMap.containsKey(7)); // true
System.out.println(hashMap.get(7)); // 仙剑 merge(K key, V value, BiFunction remappingFunction)
- 如果key没有映射,或者映射为null,key就会和value映射起来,并返回value
- 如果key有映射且映射不为null,apply()返回值为null时,key会被删除
- 如果key有映射且映射不为null,apply()返回值不为null时,key会和返回值映射起来,value就会被替换,并添加到集合中。
TVPlay t1 = hashMap.merge(7, new TVPlay("庆余年", 56), new BiFunction() {
@Override
public TVPlay apply(TVPlay tvPlay, TVPlay tvPlay2) {
System.out.println(tvPlay); // 仙剑
System.out.println(tvPlay2); // 庆余年
return tvPlay2;
}
});
System.out.println(t1); // 庆余年
System.out.println(hashMap.containsKey(7));
System.out.println(hashMap.get(7)); HashMap底层原理
HashMap底层数据结构:哈希表 ,JDK8之前的哈希表:数组+链表,JDK8之后的哈希表:数组+链表+红黑树。哈希表是一种增删改查,性能相对较好的数据结构。
往HashMap中添加元素时的过程
- 第一次往HashMap中存储键值对时,底层会创建一个长度为16的数组。
- 把键和值封装成Entry对象。
- 再根据entry对象的键计算,用hash()方法计算键的hash值,与值无关。
- 用hash值对数组长度取余,得到index。
- 判断index处的元素是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置,如果不为null,进行第六步。
- 调用equals( )方法,判断index处的对象的键和Entry对象的键是否相同,如果相同,那么Entry对象的键会替换index处对象的键,如果不相同,就像在链表中添加元素一样,一直往后找最后一个,把Entry对象的添加到链表的后面。
HashMap底层注意点
底层数组默认长度为16,如果数组中长度超过阈值(阈值 = 初始容量*负载因子),就会对数组进行2倍扩容。
从HashMap底层存储元素的过程可以发现,决定键是否重复依赖于两个方法,hashCode(),equals(),两个键的hash值重复,并且equals返回true,就认为键重复。
Hashtable
Hashtable是Java中的一种哈希表数据结构,实现类Map接口,提供了键值对检索和存储的功能。
Hashtable的特点
- 线程安全
- 键和值都不允许为null
动态扩容:Hashtable在存储键值对的数量超过阈值(初始容量*负载因子)时会自动扩容,2倍+1扩容。
Hashtable构造方法
public Hashtable( ):使用默认初始容量 (11) 和负载因子 (0.75) 构造一个新的空集合对象
public Hashtable( int capacity ):指定初始容量
public Hashtable( int capacity , Float loadFactor):指定初始容量和负载因子
Hashtable常用方法
获取键的枚举(和比较器类似)
获取值的枚举(和比较器类似)
//获取值的枚举
Enumeration elements = hashtable.elements();
while (elements.hasMoreElements()){ //此枚举类中是否还有元素
String s = elements.nextElement(); //获取当前的元素
System.out.println(s);
}
//获取键的枚举
Enumeration keys = hashtable.keys();
while (keys.hasMoreElements()){
System.out.println(keys.nextElement());
} HashMap和Hashtable的区别
-
都实现了Map接口,都存储的是键值对
- HashMap初始容量是16,扩容是2倍扩容,Hashtable初始容量是11,扩容是2被+1
- HashMap允许null键和null值,但是null只能有一个,Hashtable不允许null键和null值
- HashMap线程不安全,Hashtable线程安全
LinkedHashMap
特点:有序,不重复,无索引。
- 保持插入顺序,遍历的时候会按照元素的插入顺序输出
- 初始容量和负载因子:LinkedHashMap可以指定初始容量和负载因子,用法与HashMap相同
- 可以按照访问顺序排序:LinkedHashMap提供了一个构造方法,当设置为按照访问顺序排序时(access),每次访问元素(包括获取值,更新值,删除元素等操作)都会导致该元素被移到链表末尾。
//如果access设置成true,会按照访问顺序排序
//被访问过的会被放到尾部,最后一个被访问的放到最后一个
LinkedHashMap linkedHashMap = new LinkedHashMap<>(160,0.75f,true);
linkedHashMap.put(1,"王鹤棣");
linkedHashMap.put(2,"李雪琴");
linkedHashMap.put(3,"小辣");
linkedHashMap.put(4,"汪苏泷");
linkedHashMap.put(5,"徐志胜");
linkedHashMap.put(6,"郭麒麟");
System.out.println(linkedHashMap.get(5));
System.out.println(linkedHashMap.get(2));
//能直接打印是因为LinkedHashMap的父类重写了toString
// System.out.println(linkedHashMap);
Set> entries1 = linkedHashMap.entrySet();
for (Map.Entry entry : entries1) {
System.out.println(entry.getKey() + "---->" + entry.getValue());
} LinkedHashMap构造方法
public LinkedHashMap( ):默认初始容量16,负载因子0.75
public LinkedHashMap( int capacity ):指定初始容量
public LinkedHashMap( int capacity, Float loadFactor ):指定初始容量和负载因子
public LinkedHashMap( int capacity, Float loadFactor, Boolean access ):指定初始容量和负载因子,设置按照访问顺序排序。
LinkedHashMap常用方法
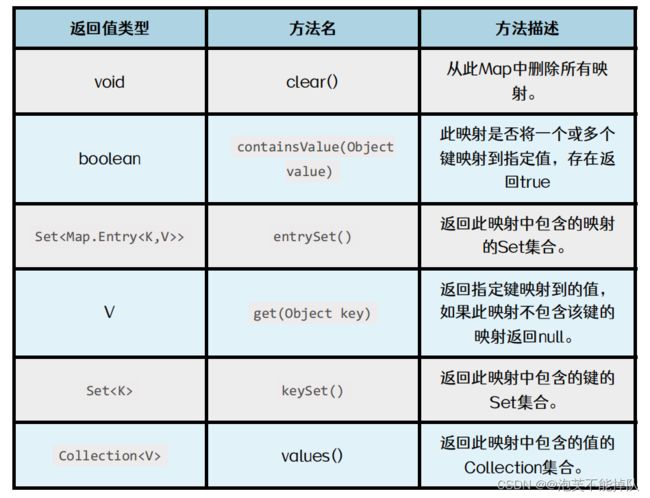
Map集合的遍历
Collection values = map.values(); // 值的集合
System.out.println(values);
Set set = map.keySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
Integer value = map.get(key);
System.out.println(key + "-->" + value);
} map.values( ):返回map中所有值的集合。
map.keySet():获取所有键的Set集合。
// entrySet() 获取到 map 中所有的键值对
// Set
// Set 中存储的对象类型是 Map.Entry
Set> entrySet = map.entrySet();
for (Map.Entry entry : entrySet) {
// Map.Entry 存储的是key和value
System.out.println(entry.getKey() + "==" + entry.getValue());
} Map中所有的键值对都放到了entrySet集合中。
使用forEach遍历:
map.forEach(new BiConsumer() {
@Override
public void accept(String key, Integer value) {
System.out.println(key);
System.out.println(value);
System.out.println(key + "==" + value);
}
});
// map.forEach((key, value) -> System.out.println(key + "-->" + value)); Map集合的案例
public static void main(String[] args) {
//某个班级80名学生,有ABCD四个景点,统计想去哪个景点的人数最多
//假设把所有人的选择看成一个长度为80的字符串
String choice = "abbbcccd";
HashMap hashMap = new HashMap<>();
for (int i = 0; i < choice.length(); i++){
char c = choice.charAt(i);
if(hashMap.containsKey(c + "")){
Integer value = hashMap.get(c + "");
hashMap.put(c + "",value + 1);
}else {
hashMap.put(c + "",1);
}
}
int max = 0;
String str = "";
Set> entries = hashMap.entrySet();
for (Map.Entry entry : entries) {
if(max < entry.getValue()){
max = entry.getValue();
str = entry.getKey();
}
}
System.out.println("最想去的景点是:" + str);
System.out.println(hashMap);
} TreeMap
TreeMap集合的特点也是有键决定的,默认按照键的升序排序, 键不重复,也是无索引。
TreeMap构造方法
public TreeMap( ):默认容量和负载因子
TreeMap常用方法
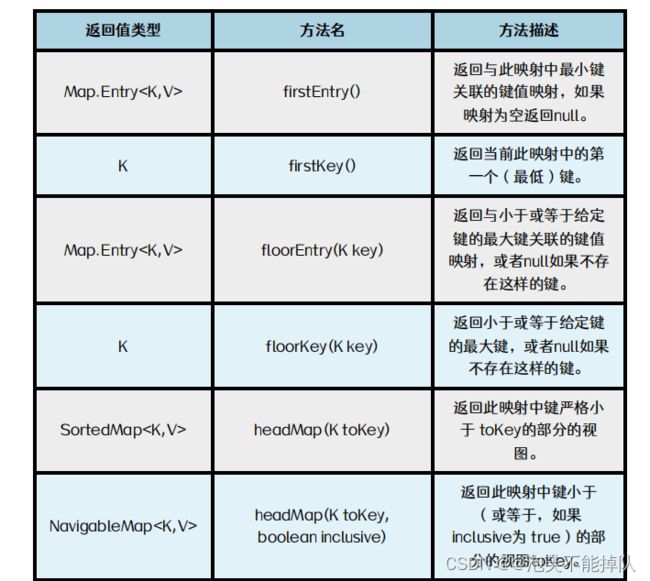
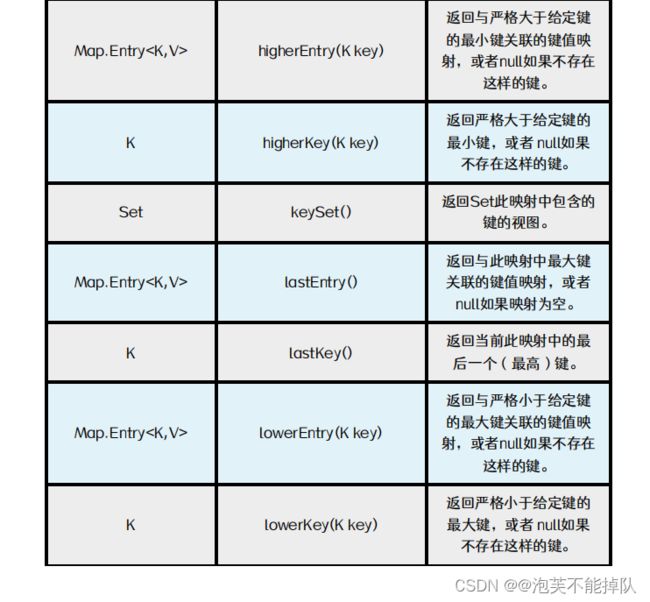
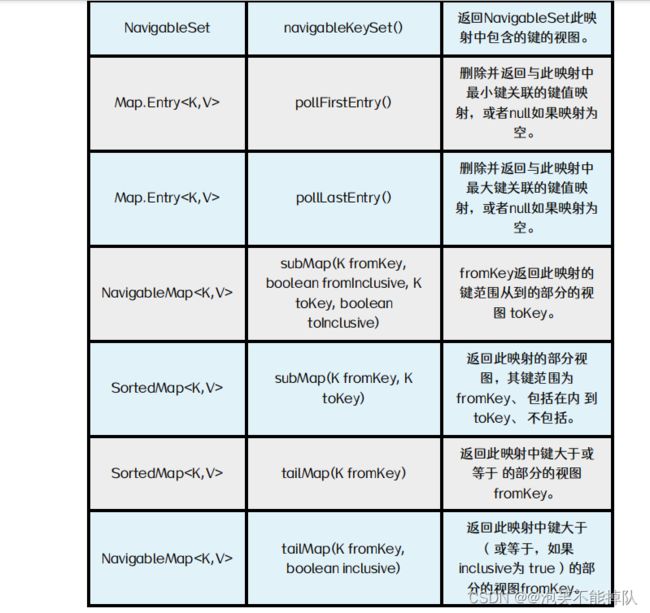
注意:只有TreeMap的键才能排序,HashMap的键不能排序。