大数据重点知识点
大数据重点知识点【精简 】
- 一.大数据特点(4V)(记住)
-
- 1.Volume(大量)
- 2.Velocity(高速)
- 3.Variety(多样)
- 4.value(低价值密度)
- 二.大数据的应用场景(了解)
- 三.大数据业务流程(无所谓)
- 四.Hadoop入门
-
- 1.hadoop基本介绍(了解)
- 2.hadoop特点(记住)
- 3.Hadoop搭建(重点理解)
-
- 1) 安装jdk
- 2)安装hadoop
- 3)hadoop结构
- 4) hadoop集群模式搭建(重点重)
- 免密
- 部署规划
一.大数据特点(4V)(记住)
1.Volume(大量)
单位: bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
转化关系
1Byte = 8bit
1K = 1024Byte
1MB = 1024K
1G = 1024M
1T = 1024G
1P = 1024T
2.Velocity(高速)
高速处理数据
3.Variety(多样)
数据的多样性
4.value(低价值密度)
提前杂乱数据中有价值的数据
二.大数据的应用场景(了解)
电商的广告推荐
比如在某商场买了一份药,之后的首页全是推荐药相关的商品
用户分析
对大量的账号数据进行分析规律,实习精准客户
物流仓库
统计物流和计算路线等大量数据
保险行业
对数据的风险分析和服务计算
人工智能+5g+虚拟化
都是未来的热门计算,都将用到大数据处理。
三.大数据业务流程(无所谓)
产品需求=>数据部门分析数据=>数据可视化
四.Hadoop入门
1.hadoop基本介绍(了解)
HADOOP
apache基金会开发的 分布式系统基础架构
hadoop准确是一个生态圈,其中包含着很多框架,总结一句话 hadoop是处理海量数据和储存海量数据的一个框架
创始人:Doug Cutting 但Lucene在上进行优化
名字来源:Doug Cutting的儿子喜欢大象
Hadoop截止2021年的三大发型版本: Apache、Cloudera、Hortonworks
2.hadoop特点(记住)
高可用性 高扩展性 高效性 高容错性

HDFS(分布式文件系统)
1.NameNode(nn):储存文件的元数据,如文件名等,以及文件的块列表和块所在的DataNode
2.DataNode(dn):具体存储文件数据,以及块数据效验和
3.Secondary NameNode(2nn):辅助NameNode 定时给NameNode元数据备份。
YARN
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
3)ApplicationMaster(AM):单个任务运行的老大
2)NodeManager(N M):单个节点服务器资源老大
4)Container:容器,相当一台独立的服务器,里面封装了
Hadoop流程

HDFS YARN MapReduce三者关系流程

大数据生态体系

3.Hadoop搭建(重点理解)
如果没有linux基础,请先去学linux
准备工具: vmwere下一台centos8虚拟机 远程连接工具
配置好网络并用连接工具连接上
ip:192.168.200.100
创建目录存放安装包
mkdir -vp /exper/software
创建目录存放解压包位置
mkdir -vp /exper/server
1) 安装jdk
下载1.8tar.gz版本 我这里用的15版本的后面会有报错
jdk下载地址
将安装包通过连接工具等方式copy到/exper/software 目录下 并解压到/exper/server目录下
cd /exper/software
tar -zxvf jdk-15.0.2_linux-x64_bin.tar.gz -C /exper/server/
配置环境变量
vi /etc/profile
在最底部插入
export JAVA_HOME=/exper/server/jdk-15.0.2/
export PATH=$JAVA_HOME/bin:$PATH
保存退出后刷新环境变量
source /etc/profile
测试
java
javac
2)安装hadoop
下载hadoop Binary 3.1.4文件
hadoop下载地址
老样子copy到/exper/software 目录下
然后解药到/exper/server目录下
cd /exper/software
tar -zxvf hadoop-3.1.4.tar.gz -C /exper/server/
配置环境变量
vi /etc/profile
加入以下命令
export HADOOP_HOME=/exper/server/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出wq!
刷新环境变量
source /etc/profile
测试
hadoop
3)hadoop结构
先介绍一下hadoop的3个环境模式

再看一下hadoop下的bin目录
cd /exper/server/hadoop-3.1.4/bin/
ll

图中3个文件 hdfs mapred yarn 是在linux常用的3个命令
本地模式测试
创建一个文件夹创建一个work.txt文件 里面随便输入一些单词
mkdir /exper/server/hadoop-3.1.4/wcinput
vi /exper/server/hadoop-3.1.4/wcinput/work.txt

执行/exper/server/hadoop-3.1.4/share/hadoop/mapreduce/目录下得hadoop-mapreduce-examples-3.1.4.jar
这个目录里存放着一些官方得实列程序
hadoop jar /exper/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount (文件的路径) (输出文件的路径)注:输出路径不能存在
执行后进入输出的文件路径查看

4) hadoop集群模式搭建(重点重)
克隆2台虚拟机

每台虚拟机都重新装载网卡


配置网络和主机名
hadoop1 192.168.200.100
hadoop2 192.168.200.110
hadoop3 192.168.200.111
3台机子设置hosts文件
vi /etc/hosts
插入以下文件

ping 主机名测试

免密
ssh-keygen -t rsa
一路回车
然后copy秘钥到所有其他机器
ssh-copy-id hadoop(1,2,3)//这里3台机子
测试是否免密码登入
ssh hadooop2
成功
部署规划
ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在
同一台机器上。
NameNode 和 SecondaryNameNode 不要安装在同一台服务器
ResourceManager SecondaryNameNode NameNode 分别放在不同的机子上
hadoop的四大配置文件
默认配置文件
[core-default.xml]
hadoop-common-3.1.4.jar/core-default.xml
[hdfs-default.xml]
hadoop-hdfs-3.1.4.jar/hdfs-default.xml
[yarn-default.xml]
hadoop-yarn-common-3.1.4.jar/yarn-default.xml
[mapred-default.xml]
hadoop-mapreduce-client-core-3.1.4.jar/mapred-default.xml
自定义核心配置文件
配置文件全在 /exper/server/hadoop-3.1.4/etc/hadoop/目录下
[core-site.xml]
configuration 中插入以下代码
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/exper/server/hadoop-3.1.4/data/</value>
</property>
[hdfs-site.xml]
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
[yarn-site.xml]
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
[mapred-site.xml]
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置完成 分发到另外2个机子上
rsync -rvl /exper/server/hadoop-3.1.4/etc/hadoop/ root@hadoop2:/exper/server/hadoop-3.1.4/etc/hadoop/
配置 workers
每台电脑配置可以直接同步rsync

注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
第一次启动格式化NameNode节点
hdfs namenode -format
hadoop目录下就会多一个data和log目录
启动
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
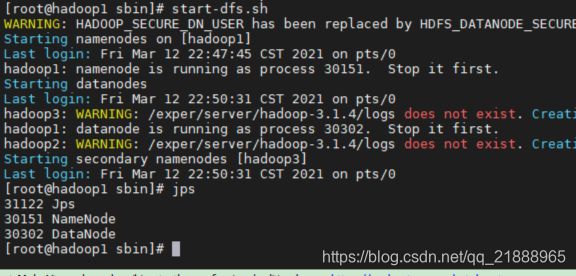
start-dfs.sh启动
如果报以下错
ERROR: JAVA_HOME is not set and could not be found.
在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME
localhost: root@localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
那台起不来就配置去哪台的免密免密
启动成功
在resourcemanager节点的那台机子启动start-yarn.sh (重点) 我这里是hadoop2

如果启动不了nodemanager节点
直接下载activation-1.1.1.jar到lib目录下,或者本地上传到${HADOOP_HOME}/share/hadoop/yarn/lib目录下后重新启动start-yarn.sh即可:
cd ${HADOOP_HOME}/share/hadoop/yarn/lib
wget https://repo1.maven.org/maven2/javax/activation/activation/1.1.1/activation-1.1.1.jar

Web 端查看 HDFS 的 NameNode (得在windwos上提前配置hosts文件域名重定向才能通过名字访问或者只能通过IP访问)
http://hadoop1:9870/
Web 端查看 YARN 的 ResourceManager
http://hadoop2:8088/
继续学习=>HDFS知识