批量汇总nmon结果文件Excel数据
1、原由
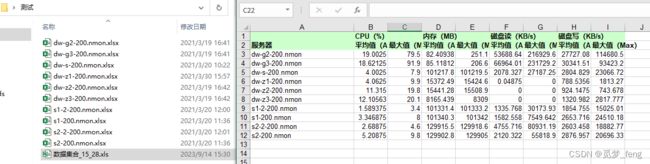
在使用nmon监控服务器资源以后,因为服务器较多,生成了几十个结果文件。现在需要统计每个文件中cpu、内存、disk等平均值、最大值信息。
太多表了,就写了个Python脚本,以后可能用的上,先记录一下。
nmon生成的Excel中,需要获取的CPU平均值、最大值:

汇总表需要填写内容:

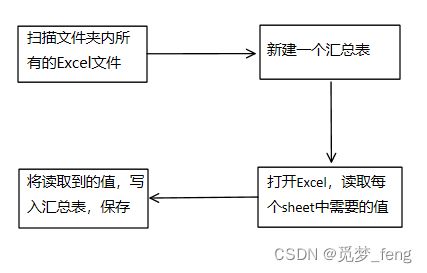
2、想法
准备使用Python的xlrd库读取每个报告的数据,xlwt库写入Excel,汇总数据。
3、脚本实现
使用Python3.9,xlrd1.2.0之后的版本不支持xlsx格式,支持xls格式。要么安装老版本:pip install xlrd==1.2.0,要么修改文件后缀名为.xls。
import os
import re
import sys
from datetime import datetime
import xlrd
import xlwt
from xlutils.copy import copy
3.1、扫描文件夹内所有的Excel文件
新建了一个类,初始化各变量,同时遍历指定文件夹路径,提取路径中.xlsx报告。将报告名称、路径、总数保存到列表中,方便后面使用。
class ExcelCut:
def __init__(self, folder_path):
self.folder_path=folder_path # 设置报告文件夹路径
self.file_paths=[] # 全部报告路径
self.file_names=[] # 全部报告名称
self.name='' # 新建报告名称
self.hang_number=2 # 初始写入行
self.success=0 # 已读数
self.count=0 # 总报告数
max_depth=2 # 设置遍历文件深度
self.get_file_paths(max_depth)
def get_file_paths(self, max_depth):
"""提取报告路径、名称"""
for root, dirs, files in os.walk(self.folder_path, topdown=True): # 遍历文件夹及其子文件夹中的.xlsx文件
depth=root[len(self.folder_path):].count(os.sep)
if depth > max_depth: # 深度超过限制,不继续递归
del dirs[:]
for file in files:
if file.endswith('.xlsx'): # 条件筛选.xlsx
file_path=os.path.join(root, file)
self.file_paths.append(file_path) # 保存报告路径
self.count=len(self.file_paths) # 统计报告数量
if self.count == 0:
print('扫描完成----------没有发现.xlsx格式的文件')
sys.exit() # 没有发现报告,程序退出
else:
print(f'扫描完成----------发现{self.count}个Excel文件')
pattern=r'[^\\]+(?=\.xlsx$)' # 提取路径中报告名称
self.file_names.extend([re.search(pattern, file_path).group() for file_path in self.file_paths])
3.2、新建一个汇总表
使用xlwt创建新表格,新建表名称为:数据集合_时_分 .xls,表内新建名为"数据"的sheet,新增表头名称:“服务器”、“CPU(%)”、“内存(MB)”、“磁盘读(KB/s)”、"磁盘写(KB/s)"等。
保存路径放在了报告文件夹,方便查看。
def new(self):
"""新建Excel,与表头"""
workbook=xlwt.Workbook(encoding='utf-8') # 新建
new_worksheet=workbook.add_sheet("数据")
style=xlwt.easyxf('pattern: pattern solid, fore_colour LIGHT_GREEN ; font: bold on') # 设置颜色
new_worksheet.col(0).width=256 * 28 # 列宽
data=[
("服务器", (0, 1), (0, 0)), # 合并 第0行到第1行的 第0列到第0列
("CPU(%)", (0, 0), (1, 2)),
("内存(MB)", (0, 0), (3, 4)),
("磁盘读(KB/s)", (0, 0), (5, 6)),
("磁盘写(KB/s)", (0, 0), (7, 8))]
for text, rows, cols in data: # 写入表头
new_worksheet.write_merge(rows[0], rows[1], cols[0], cols[1], text, style)
headers=["平均值(Avg)", "最大值(Max)", "平均值(Avg)", "最大值(Max)", "平均值(Avg)", "最大值(Max)",
"平均值(Avg)", "最大值(Max)"]
for i in range(1, len(headers) + 1):
new_worksheet.write(1, i, headers[i - 1], style)
now_time=datetime.now()
formatted_time=now_time.strftime('%H_%M')
self.name=f'{self.folder_path}\\数据集合_{formatted_time}.xls' # 保存路径在报告文件夹路径 当前时间的时、分结尾命名
workbook.save(f'{self.name}') # 保存
print(f'{self.name}----新建成功')
生成的汇总表:

生成的汇总表内容:

3.3、打开Excel,读取每个sheet中需要的值
使用xlrd打开Excel文件。新建read_excl函数,传入Excel地址与名称,返回数据列表。
SYS_SUMM中,需要CPU的Avg与Max,每个表数据可能不同,行数就不一样。但CPU%的列数不会改变,就读取第12列,定位CPU%的行数。向下两个就是需要获取的数据,其它数据同理。
def read_excl(self, xpath, file_name):
"""打开大表,读取信息,返回列表"""
try:
data=xlrd.open_workbook(xpath)
print(f"读取{file_name}表数据")
table=data.sheet_by_name("SYS_SUMM") # cpu
cpu=table.col_values(11, start_rowx=0, end_rowx=None) # 返回由该列中所有的单元格对象组成的列表
cpu_number=cpu.index('CPU%')
cpu_avg=table.cell_value(cpu_number + 1, 11)
cpu_max=table.cell_value(cpu_number + 2, 11)
table=data.sheet_by_name("MEM")
mem=table.col_values(10, start_rowx=1, end_rowx=None) # 内存
mem_avg=sum(mem) / len(mem)
mem_max=max(mem)
table=data.sheet_by_name("DISK_SUMM")
disk=table.col_values(0, start_rowx=0, end_rowx=None) # disk
disk_number=disk.index('Avg.')
disk_r_avg=table.cell_value(disk_number, 1)
disk_r_max=table.cell_value(disk_number + 2, 1)
disk_w_avg=table.cell_value(disk_number, 2)
disk_w_max=table.cell_value(disk_number + 2, 2)
values=[file_name, cpu_avg, cpu_max, mem_avg, mem_max, disk_r_avg, disk_r_max, disk_w_avg, disk_w_max]
self.success+=1 # 成功数量+1
return values
except BaseException as result:
print(f"错误:读取{file_name}表数据失败\n")
print(result)
3.4、将读取到的值,写入汇总表,保存
最后一步,新建汇总表后,循环读取,并写入保存。
xlutils可用于拷贝原excel或者在原excel基础上进行修改,并保存。
def main(self):
"""遍历所有Excel,写入汇总"""
self.new() # 新建汇总表
# 打开编辑汇总表
excel=xlrd.open_workbook(self.name, formatting_info=True) # formatting_info=True保留原有的数据格式
new_excel=copy(excel) # 将xlrd对象拷贝转换成xlwt对象
sheet=new_excel.get_sheet("数据") # 通过sheet名称获取表格
for row in range(self.count): # 遍历表,写每行
va=self.read_excl(self.file_paths[row], self.file_names[row])
for col in range(9): # 遍历写每列
sheet.write(self.hang_number, col, va[col])
self.hang_number+=1 # 行数
new_excel.save(self.name) # 保存excel文件
print(f'应截报告{self.count}个,已截取报告{self.success}个')
4、运行结果
所有文件已读取。
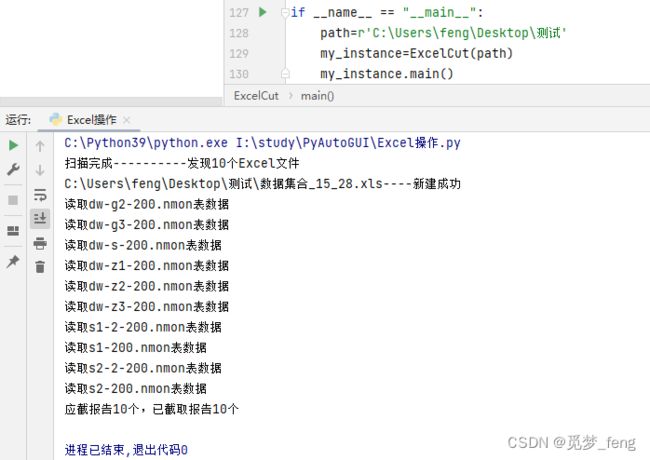
数据汇总写入到表内。