【mysql代码解读】仅通过sql查询树结构的所有子节点 手把手带你解读复杂sql
目录
-
- 事件起因
- 代码解读:
-
- 接下来我们来拆解解读这个“我认为比较复杂的sql”:
- 得到的结果字符串再转换为字符串集合列表:
- 总结
事件起因
在看一个老项目的时候,看到的一个比较神奇的操作,我们平时查询有层级关系的内容时,比如一个部门表或者类别表的时候,常常会使用到树结构,就是在mysql的表中有一列是pid,也就是父亲id,从而形成树结构,这种情况,我们一般在服务端(后端)采用递归遍历的方式来循环访问数据库,从而得到一个树结构的列表,要想访问某个节点下的所有子节点,大致也是这种方式,从要开始找的节点开始向下找,然后递归遍历子节点继续向下找子节点
我遇到了一个什么呢?就是在找一个结点下所有子结点的时候,我看到一个野路子,它的源代码是这样的:(该代码是在mapper层的,通过注解@select的方式写的sql)
首先:要明确我们的目标,我们的目标是:找到树结构中某个id下所有的子节点
@Select("SELECT max(t3.childId)\n" +
" FROM (\n" +
" SELECT *,\n" +
" IF\n" +
" (\n" +
" find_in_set( t1.pid, @p ) > 0,\n" +
" @p := concat( @p, ',', id ),\n" +
" 0\n" +
" ) AS childId\n" +
" FROM\n" +
" ( SELECT id, pid FROM sys_category t ORDER BY id ) t1,\n" +
" ( SELECT @p := #{parentId}) t2\n" +
" ) t3\n" +
" WHERE\n" +
" childId != 0")
String selectChildByPid(@Param("parentId") String parentId);
原图:

代码解读:
因为看这代码挺有意思,就把它拉出来分析了一下
我将它单独拉到了navicat里进行分段执行了一下
在代码里面是一个变量的值,我就单独给了一个指定值

对应的可复制sql:
select
max(t3.childId)
from
(
select *,
if( find_in_set(t1.pid, @p) > 0,@p := concat(@p,',',id),0 ) as childId
from
(select id, pid from sys_category t order by id) t1,
(select @p := "1492039984654921729") t2
) t3
where childId != 0
接下来我们来拆解解读这个“我认为比较复杂的sql”:
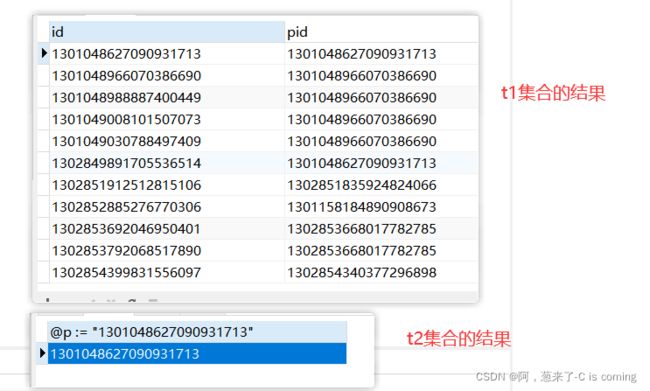
首先sql 要从最内部逐层像外执行,所以我们先解读最内部的sql,那就是t1集合与t2集合的产生:

这个也较为简单,分别执行的话,就是下面的结果(注意这儿引进了一个变量 @p ,且t1的集合是根据id的大小从小到大排序的):
- 然后再向外面扩展一层:(我觉得这段sql语句理解起来的重难点就主要是在这儿)
整个执行和解释过程我写在了图中,按照1,2,3,4,5的顺序阅读的话,那么也能对这个sql了解得更多一点吧

- 再向外扩展一层:
那就是最外面的一层了,这一层没有执行其他的东西,主要是一个max函数和对数据进行了筛选,只要有子节点的的最大值(其实就是变量p子结点最多的那个值)

关于max函数:
知识点:
mysql字符串大小比较:使用MAX()查询一个字符串类型的字段时,
字符串类型大小比较是先比较首字符的ASCII码的大小,然后依次往后进行比较的。
只求最后得出的这个变量p的最长的一个值 也就是目标结点id下的所有的子节点
得到的结果字符串再转换为字符串集合列表:
另:这种的sql查询结果是一个采用","号隔开的要查询目标结点其下所有子id的字符串(也包含自身的id)
就像这样:

要想在后端将它转换会列表集合,那么只需要:
执行这样的操作:
List<String> childIdList = Arrays.asList(childId.split(",")
就能得到一个某个id(节点)下的所有节点id的字符串集合
总结
这个sql主要利用了变量p在执行过程中反复给它赋值(增加新的子结点的id),在变化的过程中就得出了所有的子节点的id 还有就是变量的使用、find_in_set和max函数的使用 难点主要在变量的执行过程中的变化和函数 当然 理解完之后(大佬回到新手村)发现其实这也不难
当然这个项目中在做的过程中也发现:它所记录的id居然是使用的字符串格式进行存储(而非常规的bigint):
