go通过pprof定位groutine泄漏
日常开发中除了会出现Panic、ErrorInfo等通过日志很容易捕捉到的错误,还会出现内存泄漏、CPU激增等日志难以捕捉的问题。今天小老虎就给大家介绍下如何使用pprof去捕捉内存、CPU这些日志难以排查到的问题。
pprof的访问
pprof是Golang的性能分析工具,可以帮助我们查看程序在运行过程中CPU、内存、协程、锁的详细信息,对于定位程序中的bug非常有帮助。在Golang内存泄漏的七种场景中小老虎对内存泄漏可能出现的场景做了详细的介绍,下面以死锁造成的内存泄漏为例,来看看怎样使用pprof定位到内存泄漏的位置。
Golang已经帮助我们封装好了一个pprof服务,我们这需要在代码中开启这个服务,并访问对于的url就可以轻松获取到程序运行时的资源情况。
//启动pprof服务供外部访问func pprofServer() {ip := "0.0.0.0:6060"if err := http.ListenAndServe(ip, nil); err != nil {fmt.Printf("start pprof failed on %s\n", ip)}}//协程拿到锁未释放,其他协程获取锁会阻塞,模拟内存泄漏func mutexTest() {mutex := sync.Mutex{}for i := 0; i < 10; i++ {go func() {mutex.Lock()fmt.Printf("%d goroutine get mutex", i)//模拟项目中后续代码耗时time.Sleep(100 * time.Millisecond)}()}time.Sleep(10 * time.Second)}func main() {go pprofServer()mutexTest()}
在浏览器中输入地址http://127.0.0.1:6060/debug/pprof/
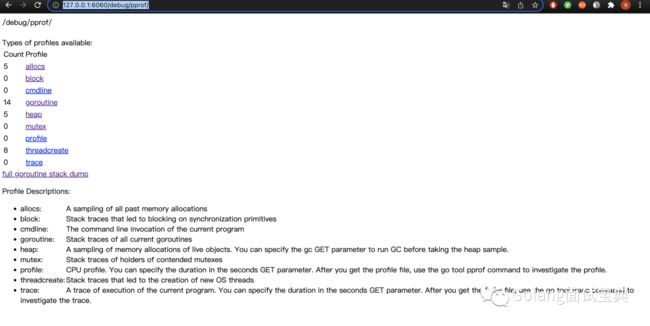
比较常用的有下面五种信息
goroutine:所有goroutine的详细信息,包括协程数量,协程调用栈
heap:程序堆内存信息(每1000次内存申请采样一次)
mutex:锁的调用信息
trace:程序调用栈信息
profile:程序执行的CPU信息(每1秒采样100次)
点击查看goroutine信息

image-20220306141533652
可以看到程序一共有15个协程其中有9个协程阻塞在了获取锁的位置,将url中的debug=1改为debug=2查看每个goroutine的详细信息。
debug=2查看每个goroutine的详细信息。
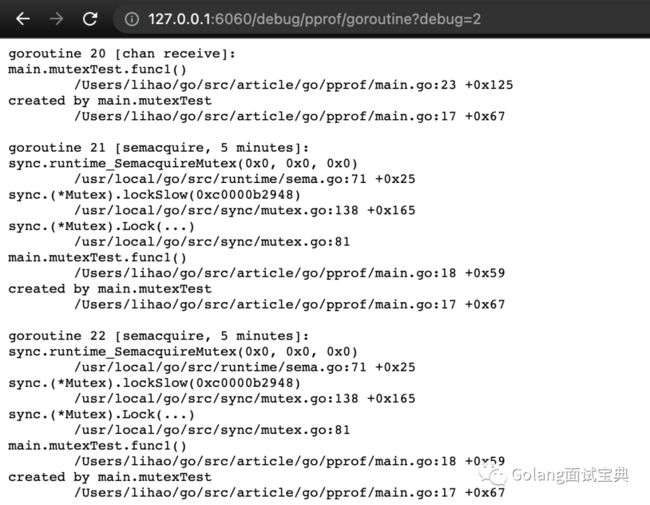
可以看到协程号为21和22的协程都阻塞在了锁的获取上,阻塞时间为5min。下面再通过代码很容易就定位到了goroutine泄漏的原因是获取锁失败了。
命令行交互
实际开发中,有些程序是部署在内网服务器中的,这时没有浏览器来提供可视化的界面,就需要通过命令来查看资源的使用情况。使用命令go tool pprof url可以获取指定的profile文件,该命令会发起http请求,然后获取到资源信息存储到本地,之后就可以使用命令查看运行信息,以下是5类请求的方式:
# 下载cpu profile,默认从当前开始收集30s的cpu使用情况,需要等待30sgo tool pprof http://localhost:6060/debug/pprof/profilego tool pprof http://localhost:6060/debug/pprof/profile?seconds=60 # wait60s# 下载heap profilego tool pprof http://localhost:6060/debug/pprof/heap# 下载goroutine profilego tool pprof http://localhost:6060/debug/pprof/goroutine# 下载block profilego tool pprof http://localhost:6060/debug/pprof/block# 下载mutex profilego tool pprof http://localhost:6060/debug/pprof/mutex
等待收集完成后就可以通过命令查看相应的信息,所有的交互命令都可以通过help指令查看。
go tool pprof http://localhost:6060/debug/pprof/profileFetching profile over HTTP from http://localhost:6060/debug/pprof/profileSaved profile in /pprof/pprof.samples.cpu.016.pb.gzType: cpuTime: Mar 6, 2022 at 4:15pm (CST)Duration: 30s, Total samples = 290ms ( 0.97%)Entering interactive mode (type "help" for commands, "o" for options)(pprof) helpCommands:callgrind Outputs a graph in callgrind formatcomments Output all profile commentsdisasm Output assembly listings annotated with samplesdot Outputs a graph in DOT formateog Visualize graph through eogevince Visualize graph through evincegif Outputs a graph image in GIF formatgv Visualize graph through gvkcachegrind Visualize report in KCachegrindlist Output annotated source for functions matching regexp
常用的命令有三种top、list、traces
top N:可以获取程序中资源消耗最大的前N个函数,例如输入top 10可以查看CPU消耗前十的函数
(pprof) top 10Showing nodes accounting for 270ms, 93.10% of 290ms totalShowing top 10 nodes out of 19flat flat% sum% cum cum%90ms 31.03% 31.03% 130ms 44.83% runtime.kevent40ms 13.79% 44.83% 40ms 13.79% runtime.libcCall30ms 10.34% 55.17% 30ms 10.34% runtime.kevent_trampoline20ms 6.90% 62.07% 50ms 17.24% runtime.checkTimers20ms 6.90% 68.97% 250ms 86.21% runtime.findrunnable20ms 6.90% 75.86% 20ms 6.90% runtime.lock220ms 6.90% 82.76% 30ms 10.34% runtime.runtimer10ms 3.45% 86.21% 10ms 3.45% runtime.(*randomEnum).next (inline)10ms 3.45% 89.66% 10ms 3.45% runtime.runOneTimer10ms 3.45% 93.10% 10ms 3.45% runtime.runqget
top指令会统计下面五种信息
-
flat: 函数本身占用的CPU时间。
-
flat%: 本函数CPU占使用中CPU总量的百分比。
-
sum%: 前面每一行flat百分比的累加,比如第2行的44.3%=第1行的31.03%+当前函数的13.79%
-
cum: 是累计量,例如main函数调用子函数mutexTest,那么子函数mutexTest的CPU使用量也会被记进来
-
cum%: 是累计量占总量的百分比
list func:产看某个函数的资源使用信息,函数匹配使用的是正则匹配。
(pprof) list mutexTestTotal: 7.73sROUTINE ======================== main.mutexTest.func1 in article/go/pprof/main.go0 3.82s (flat, cum) 49.42% of Total. . 19: fmt.Printf("%d goroutine get mutex", i). . 20: //模拟实际开发中的操作耗时. . 21: tick := time.Tick(time.Second / 100). . 22: var buf []byte. . 23: for range tick {. 3.82s 24: buf = append(buf, make([]byte, 1024*1024)...). . 25: }. . 26: time.Sleep(100 * time.Millisecond). . 27: wg.Done(). . 28: }(). . 29: }
显示该函数的占用0s(小数点后俩位则被舍去),累计上子函数的调用占用3.82s,占总CPU使用时间的49.42%。耗时主要积累在第24行,占用了3.82s。
在实际项目中可能会出现不同包中函数名相同的情况,尤其是接口中函数的问题定位,如果使用模糊查找自己想看的函数会很麻烦,这里提供几种特殊的正则匹配方式。(假设包括work的多个包中都有Show方法 ,以work包的特殊处理为例)
-
模糊匹配:输入函数的名称
-
精确匹配 :artical/go/pprof/main.Test,从根路径查找到包,使用包.方法名精确表示
-
结构体指针方法:list Show -focus = work* 只展示work包中的Show方法(等号俩边要有空格)
-
忽略某些包:list Show -work* 不展示work包中的Show方法
traces:查看函数调用栈信息
可视化工具
上面介绍的俩种方法都是pprof自带的检测方法,虽让能够帮助定位到程序的问题所在,但是每次打开CPU和内存分析文件都是密密麻麻的数字和代码,还是蛮头疼的,下面介绍pprof结合graphviz带来的可视化服务,是问题定位能够更加清晰。(首先需要下载graphviz)
首先将信息倒入到文件中curl -sK -v http://localhost:6060/debug/pprof/profile > cpu.out
然后用 go tool 工具go tool pprof -http=:8080 heap.out 使用该命令导出文件起一个服务,会自动跳到 UI 界面
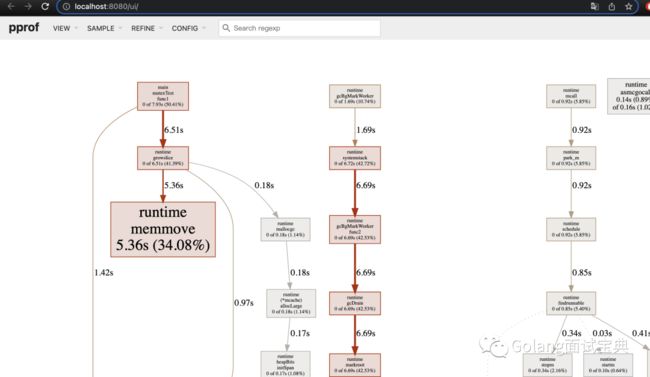
节点中的数字表示flat(函数使用量) of cum(函数包括子函数的使用量) cum%(cum占总使用量的百分比),节点越大越红表示该接节点的flat值越大,线越粗表示指向的节点cum值越大。
VIEW
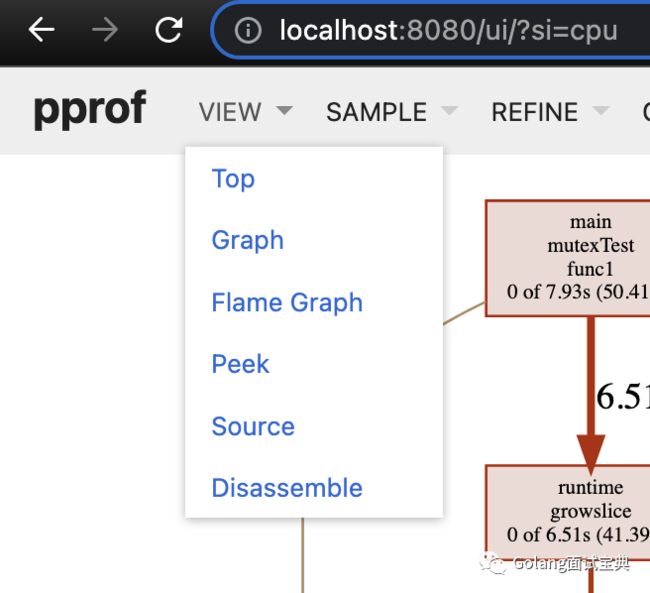
image-20220306173905386
Top:和top命令相同,将函数按资源使用进行排名
Graph:如图的函数调用逻辑图以及节点使用
Flame Graph:火焰图,资源使用按从大到小排列,点击可看详细信息
Peek:打印每个调用栈的信息
Source:显示具体函数的资源消耗信息,类似list命令
Disassemble:显示样本总量
SAMPLE

img
如果是内存信息SAMOLE这一栏有四个选项
alloc_objects:已分配的对象总量(不管是否已释放)
alloc_space:已分配的内存总量(不管是否已释放)
inuse_objects:已分配但尚未释放的对象数量
inuse_sapce:已分配但尚未释放的内存数量
REFINE
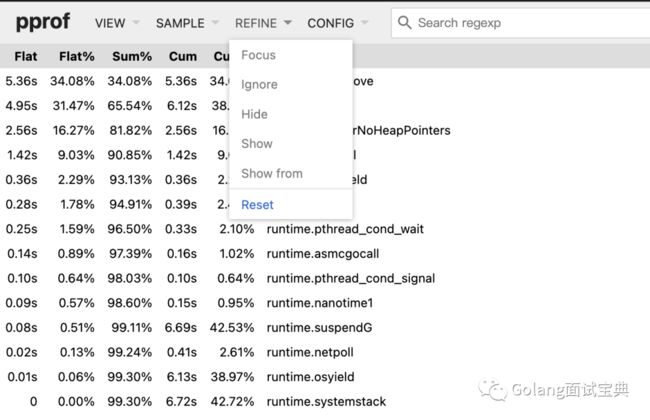
搭配搜索框使用按正则表达式对内容进行过滤(list命令)
总结
本文介绍了pprof自带的浏览器访问方式,以及在服务器上通过命令获取资源信息的方式和三种常用命令,top可以获取程序中子源消耗的函数排名,list可以获取指定函数的详细信息,trance可以打印出函数的调用栈。最后介绍了ppro结合graphviz带来的可视化服务,可以使得操作更加便利,火焰图更是直观简洁,能够帮助我们快速定位问题所在