前端面试题汇总(含答案)(JS篇)
主要自用,持续更新,相同类型的题目尽量放在了一起,参考的实在太多了就没有列出,侵权烦请联系删除。提示:自动生成的目录在页面右边---------->>>>>>>>>>>>>>>>
Js的一些基础忽略点
- 在JS中想要使用${}获取变量 要在` `中使用(这个引号是~这个键的那个引号)
Js的数据类型有哪些
基本类型:String、Number、Boolean、Null、Undefined、symbol(ES6)
引用类型:Object、Array、Date、Function、Error、RegExp、Math、Number、String、Boolean、Globle。
js内置类型有七种:String、Number、Boolean、Null、Undefined、Symbol(ES6)、Object
js基本数据类型和引用类型的区别
- 声明变量时不同的内存分配:
1)原始值:存储在栈(stack)中的简单数据段,也就是说,它们的值直接存储在变量访问的位置。(这些原始类型占据的空间是固定的,所以可将他们存储在较小的内存区域 – 栈中。这样存储便于迅速查寻变量的值。)
2)引用值:存储在堆(heap)中的对象,也就是说,存储在变量处的值是一个指针(point),指向存储对象的内存地址。(引用值的大小会改变,所以不能把它放在栈中,否则会降低变量查寻的速度。相反,放在变量的栈空间中的值是该对象存储在堆中的地址。地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响。)
- 不同的内存分配机制也带来了不同的访问机制
1)在javascript中是不允许直接访问保存在堆内存中的对象的,所以在访问一个对象时,首先得到的是这个对象在堆内存中的地址,然后再按照这个地址去获得这个对象中的值,这就是传说中的按引用访问。
2)而原始类型的值则是可以直接访问到的。
- 复制变量时的不同
1)原始值:在将一个保存着原始值的变量复制给另一个变量时,会将原始值的副本赋值给新变量,此后这两个变量是完全独立的,他们只是拥有相同的value而已。
2)引用值:在将一个保存着对象内存地址的变量复制给另一个变量时,会把这个内存地址赋值给新变量,也就是说这两个变量都指向了堆内存中的同一个对象,他们中任何一个作出的改变都会反映在另一个身上。(这里要理解的一点就是,复制对象时并不会在堆内存中新生成一个一模一样的对象,只是多了一个保存指向这个对象指针的变量罢了)。多了一个指针
- 参数传递的不同(把实参复制给形参的过程)
原始值:只是把变量里的值传递给参数,之后参数和这个变量互不影响。
引用值:对象变量它里面的值是这个对象在堆内存中的内存地址,这一点你要时刻铭记在心!因此它传递的值也就是这个内存地址,这也就是为什么函数内部对这个参数的修改会体现在外部的原因了,因为它们都指向同一个对象。
判断基本数据类型的方法
判断数据类型的方法一般可以通过:typeof、instanceof、constructor、Object.prototype.toString.call();四种常用方法
-
typeof:(可以对基本类型(包括function)做出准确的判断,但对于引用类型,用它就有点力不从心了),typeof 返回一个表示数据类型的字符串,返回结果包括:number、boolean、string、object、undefined、function、Symbol6种数据类型。
-
instanceof(判断是否是某个类的实例)
//基本数据类型是没有检测出他们的类型
var str = 'hello';
alert(str instanceof String);//false
var bool = true;
alert(bool instanceof Boolean);//false
var num = 123;
alert(num instanceof Number);//false
var nul = null;
alert(nul instanceof Object);//false
var und = undefined;
alert(und instanceof Object);//false
var oDate = new Date();
alert(oDate instanceof Date);//true
var json = {};
alert(json instanceof Object);//true
var arr = [];
alert(arr instanceof Array);//true
var reg = /a/;
alert(reg instanceof RegExp);//true
var fun = function(){};
alert(fun instanceof Function);//true
var error = new Error();
alert(error instanceof Error);//true
//使用下面的方式创建num、str、boolean,是可以检测出类型
var num = new Number(123);
var str = new String('abcdef');
var boolean = new Boolean(true);
console.log(num instanceof Number)
console.log(num instanceof String)
- constructor:查看对象对应的构造函数
constructor 在其对应对象的原型下面,是自动生成的。当我们写一个构造函数的时候,程序会自动添加:构造函数名.prototype.constructor = 构造函数名
var str = 'hello';
alert(str.constructor == String);//true
var bool = true;
alert(bool.constructor == Boolean);//true
var num = 123;
alert(num.constructor ==Number);//true
var nul = null;
//null和undefined是无效的对象,因此是不会有constructor存在的
alert(nul.constructor == Object);//报错
//var und = undefined;
//alert(und.constructor == Object);//报错
var oDate = new Date();
alert(oDate.constructor == Date);//true
var json = {};
alert(json.constructor == Object);//true
var arr = [];
alert(arr.constructor == Array);//true
var reg = /a/;
alert(reg.constructor == RegExp);//true
var fun = function(){};
alert(fun.constructor ==Function);//true
var error = new Error();
alert(error.constructor == Error);//true
//特殊情况
function Aaa(){
}
Aaa.prototype.constructor = Aaa;//程序可以自动添加,当我们写个构造函数的时候,程序会自动添加这句代码
function BBB(){}
Aaa.prototype.constructor = BBB;//此时我们就修改了Aaa构造函数的指向问题
alert(Aaa.construtor==Aaa);//false
//constructor并没有正确检测出正确的构造函数
//备注:使用Object.create()创建的js对象,没有constructor
//null和undefined没有相应的构造形式,而Date,只有相应的构造形式而没有文字形式两者相反
- Object.prototype.toString(可以说不管是什么类型,它都可以立即判断出)
toString是Object原型对象上的一个方法,该方法默认返回其调用者的具体类型,更严格的讲,是 toString运行时this指向的对象类型, 返回的类型格式为[object xxx],xxx是具体的数据类型,其中包括:String,Number,Boolean,Undefined,Null,Function,Date,Array,RegExp,Error,HTMLDocument,… 基本上所有对象的类型都可以通过这个方法获取到
var str = 'hello';
console.log(Object.prototype.toString.cal(str));//[object String]
var bool = true;
console.log(Object.prototype.toString.cal(bool))//[object Boolean]
var num = 123;
console.log(Object.prototype.toString.cal(num));//[object Number]
var nul = null;
console.log(Object.prototype.toString.cal(nul));//[object Null]
var und = undefined;
console.log(Object.prototype.toString.cal(und));//[object Undefined]
var oDate = new Date();
console.log(Object.prototype.toString.cal(oDate));//[object Date]
var json = {};
console.log(Object.prototype.toString.cal(json));//[object Object]
var arr = [];
console.log(Object.prototype.toString.cal(arr));//[object Array]
var reg = /a/;
console.log(Object.prototype.toString.cal(reg));//[object RegExp]
var fun = function(){};
console.log(Object.prototype.toString.cal(fun));//[object Function]
var error = new Error();
console.log(Object.prototype.toString.cal(error));//[object Error]
其实面试官也经常喜欢让说一种最简单的判断是数组的方法,记住喽是object.prototype.toString.call()哦!
JS堆和栈
- 堆栈基础
1.栈(stack): 由操作系统自动分配内存空间,自动释放,存储的是基础变量以及一些对象的引用变量,占据固定大小的空间。
2.堆(heap): 由操作系统动态分配的内存,大小不定也不会自动释放,一般由程序员分配释放,也可由垃圾回收机制回收。
- 堆栈区别
1、栈:基础变量的值是存储在栈中,而引用变量存储在栈中的是指向堆中的数组或者对象的地址,这就是为何修改引用类型总会影响到其他指向这个地址的引用变量。(线性结构,后进先出)
优点:
(1)栈中的内容是操作系统自动创建、自动回收,占据固定大小的空间,因此内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
(2)相比于堆来说存取速度会快,并且栈内存中的数据是可以共享的,例如同时声明了var a = 1和var b =1,会先处理a,然后在栈中查找有没有值为1的地址,如果没有就开辟一个值为1的地址,然后a指向这个地址,当处理b时,因为值为1的地址已经开辟好了,所以b也会同样指向同一个地址。
缺点:
相比于堆来说的缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
2、堆:堆内存中的对象不会随方法的结束而销毁,就算方法结束了,这个对象也可能会被其他引用变量所引用(参数传递)。创建对象是为了反复利用(因为对象的创建成本通常较大),这个对象将被保存到运行时数据区(也就是堆内存)。只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在核实的时候回收它。
优点:
(1) 堆是操作系统动态分配的大小不定的内存,因此方便存储和开辟内存空间。
(2)堆中保存的对象不会自动释放,一般由程序员分配释放,也可由垃圾回收机制回收,因此生存周期比较灵活。
缺点:
相比于栈来说的缺点是,存在堆中的数据大小与生存期是不确定的,比较混乱,杂乱无章。
- 一些总结
1.复制方式不一样,值类型的是深复制(深拷贝),引用类型的是浅复制(浅拷贝),变量的复制其实是引用的传递。
2.(1)如果想要堆溢出,比较简单,可以循环创建对象或大的对象;(2)如果想要栈溢出,可以递归调用方法,这样随着栈深度的增加,JVM (虚拟机)维持着一条长长的方法调用轨迹,直到内存不够分配,产生栈溢出。
栈进制转换
- 进制转换
function change(num){
let stack = new Stack()
while(num>0){
stack.push(num%2)
num = Math.floor(num2)
}
let str = ''
while(!stack.isEmpty()){
str += stack.pop()
}
return str
}
prototype和__proto__
https://github.com/dreamapplehappy/hacking-with-javascript/blob/master/points/understand-prototype-proto.md
原型链,继承相关(ES5与ES6)
原型链作为实现继承的主要方法。每个构造函都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。而我们让原型对象等于另一个类型的实例,此时的原型对象将包含一个指向另一个原型的指针,如果相应的另一个原型中也包含着一个指向另一个构造函数的指针,加入另一个原型又是另一个类型的实例,这样层层的递进就构成了实例与原型的链条,这就是所谓的原型链。基本模式的代码:
function SuperType(){
this.property = true;
}
SuperType.prototype.getSuperValue = function(){
return this.property;
}
function SubType(){
this.subproperty = false;
}
SubType.prototype = new SuperType();
SubType.prototype.getSubVaule = function (){
return this.subproperty;
}
//这个时候的instance.constructor指向的是SuperType
//因为原来的Subtype.prototype中的contructor被重写了
var instance = new SubType();
alert(instance.getSuperValue()) //true
//确定原型与实例的关系
alert(instance instanceof Object) //true
alert(instance instanceof SuperType) //true
alert(instance instanceof SubType) //true
alert(Object.prototype.isPrototypeOf(instance)) //true

- 借用构造函数
解决原型中包含引用类型值所带来的问题,使用apply()和call()方法可以在新创建的对象上执行构造函数
function SuperType(){
this.colors = ["red", "blue", "green"];
}
function SubType(){
//继承了SuperType
SuperType.call(this); // 借调了超类型的构造函数
}
var instance1 = new SubType();
instance1.colors.push("black");
alert(instance1.colors) //有black
var instance2 = new SubType();
alert(instance2.colors) //无black
//还可以在子类型构造函数中向超类型构造函数传递参数
function SuperType(name){
this.name = name;
}
function SubType(){
//继承SuperType并且传递了参数
SuperType.call(this,"hello")
//实例属性(放在继承的后面,防止超类型构造函数重写子类型的属性)
this.age = 29
}
//问题。不能函数复用,方法都在构造函数中定义,超类型原型中的方法对自类型不可见
- 组合继承(伪经典继承 最常用)
原型链+借用构造函数技术;实现既能分别拥有自己的属性,又可以使用相同的方法,但这种方法会每次都调用两次超类型的构造函数,一次在创建自类型,另一次是在子类型构造函数的内部
function SuperType(name){
this.name = name;
this.colors = ["red","blue","green"]
}
SuperType.prototype.sayName = function(){
return this.name
}
function SubType(name,age){
SuperType.call(this,name);
this.age = age;
}
//继承方法(继承超类的属性和方法)
SubTupe.prototype = new SuperType();
//这一次是在新对象上创建了实例和方法
SubType.prototype.contructior = SubTupe;
SubType.prototype.sayAge = function(){
return this.age;
}
var instance1 = new SubType("hello",28);
instance1.colors.push("black");
instance1.sayName();
instance1.sayAge();
var instance2 = new SubType("xixi",30);
alert(instance2.colors) //无“black"
instance2.sayName();
instance2.sayAge(); //均是自己的
- 原型式继承
并没有使用严格意义上的构造函数,而是借助原型可以基于已有的对象创建新对象,同时还不必因此创建自定义类型,会产生共用的引用类型
//使用函数
//Object.create()方法只传一个参数就是使用此方法
//传递两个参数就是另一个为新对象定义额外属性的对象
funciton object(o){
//临时构造函数,将传入对象作为这个构造函数的原型
function F(){}
F.prototype = o;
return new F();
}
//------------
var person = {
name:"hello",
color:["xixi","didi","dada"] //这种引用类型会共享
};
var anotherPerson = Obejct.create(person);
var anotherPerson1 = Object.create(person); //它会和上面的共享color引用类型
var anthoerPerson2 = Object.create(person,{
name:{
value:"greg"
}
});//这种方式指定的任何属性都会覆盖原型对象上的同名属性
alert(anotherPerson2.name); //"greg"
- 寄生式继承
类似于工厂模式,创建一个仅用于封装继承过程的函数,此函数在内部以某种方式来增强对象,但不能做到函数复用,与构造函数模式类似
//使用的函数
function createAnother(original){
var clone = object(original); //通过调用函数创建一个新对象
clone.sayHi = function(){
alert("hi");
};
return clone;
}
//-----------
var person = {
name:"Nicholas",
friends: ["haha","lala","dada:]
};
var anotherPerson = createAnother(person) //新对象不仅具有person的所有属性方法也自己的sayHi()方法
- 寄生组合式继承(最理想的继承范式)
通过借用构造函数来继承属性,通过原型链的混成形式来继承方法,其实我们无非就是想要超类型原型的一个副本而已,没必要调用超类型的构造函数,它只调用了一次SuperType构造函数,因此避免了在SubType.prototype上穿件不必要的多余的属性,并且原型链还能保持不变
//使用的函数
function inheritPrototype(subType, superType){
var prototype = object(superType.prototype); //创建对象
prototype.constructor = subType; //增强对象
subType.prototype = prototype; 指定对象
}
//-------
function SuperType(name){
this.name = name;
this.colors = ["red","blue","green"]
}
SuperType.prototype.sayName = function(){
return this.name
}
function SubType(name,age){
SuperType.call(this,name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function(){
return this.age;
}
- ES6的继承
ES6中提供了class和extends来实现继承,这两个词本质上是ES5继承的语法糖,只是方便人来使用和记忆。
class Person {
// constructor
constructor (name) {
this.name = name
}
// 其他私有方法
say () {
console.log(`我的名字叫${this.name}`);
}
}
class taec extends Person {
constructor (name,age) {
super(name)
this.age = age
}
getage() {
console.log(`我叫${this.name}今年${this.age}岁`);
}
}
let p = new taec('Taec',18)
console.log(p);
p.say()
p.getage()
- ES6继承的proto和prototype
子类.proto = 父类
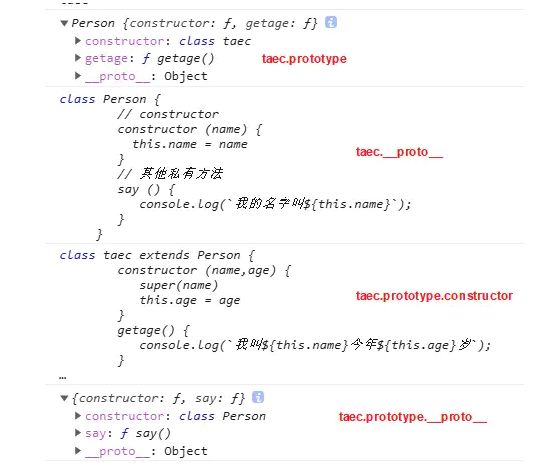

- es5和es6继承的区别是
es5是先创建子类,实例化父类并添加到子类this中实现继承;而es6是先创建父类,实例化子集中通过调用super方法访问父类后,通过修改this实现继承。
Object.defineProperty()
Object.defineProperty()的作用就是直接在一个对象上定义一个新属性,或者修改一个已经存在的属性
Object.defineProperty(obj, prop, desc)
箭头函数与普通函数的区别
- this(执行上下文)指向
(1)普通函数中的this:在简单调用中,非严格模式下,指向window。严格模式下,如果this没被指定值,那么才为undefined。
function parent() {
console.log(this);
}
parent();// window。其实parent()相当于parent.call(window)
'use strict';
function parent() {
console.log(this);
}
parent(1,2); // undefined
parent.call(1,2); // this为1
function parent() {
console.log(this);
}
const obj = {
name: 'ha'
}
parent.call(obj); // this指向obj对象
//作为某个对象方法调用时,this指向该对象。当该普通函数被间接调用时,即:使用call()和apply()方法调用时,this指向call()和apply()第一个参数。注意:在非严格模式下, 当第一个参数为null或者undefined时,调用函数中的this指向window
(2)箭头函数中的this:没有自己的this,内部this的值,依赖于外部非箭头函数的this。箭头函数其实是更简单的函数
//箭头函数在定义之后,this 就不会发生改变了,无论用什么样的方式调用它,this 都不会改变;
function make () {
return ()=>{
console.log(this);
}
}
const testFunc = make.call({ name:'foo' });
testFunc(); //=> { name:'foo' }
testFunc.call({ name:'bar' }); //=> { name:'foo' }
(3)绑定住this
function make () {
var self = this;
return function () {
console.log(self);
}
}
//或者只绑定一个this
function make () {
return function () {
console.log(this);
}.bind(this);
}
- 构造函数
1)普通函数可以作为构造函数来用,用new去新建对象实例。
2)箭头函数不能当做构造函数去用,并且,会报错。
- arguments对象
在普通函数中,会自动绑定上的各种局部变量,箭头函数都是十分单纯的沿着作用域链向上寻找,箭头函数更适合函数式编程,除了它更短以外,使用箭头函数也更难被那些没有显示声明的变量影响,导致你产生意料之外的计算结果;
function regular() {
const arrow = (...arg) => {
console.log(arg); // [[1,2,3], 232]
}
arrow([1,2,3], 232);
}
regular(1,3);//2:[1,2,3],232
-
隐式return
1)普通函数:用return去返回一个函数的结果。无return语句,或者return后面无表达式,则返回undefined。
2)箭头函数:如果函数仅有一个表达式,那么该表达式的结果会被隐式返回。 -
当作为回调方法去使用时
1)普通函数:由于普通函数的this,由执行时候确定。那么当做为定时器函数或者事件监听器的回调去执行时,就有this指向的问题了。这时候,你或许需要用bind()方法去绑定this值。
2)箭头函数:箭头函数的this,由定义它的时候,外部非箭头函数中this所决定。因此,如果需要将一个函数作为回调函数去执行,并且,不希望函数中的this发生改变时。那么,非箭头函数就是把利器了。
class Hero {
constructor(heroName) {
this.heroName = heroName;
}
logName = () => {
console.log(this.heroName);
}
}
const batman = new Hero('Batman');
setTimeout(batman.logName, 1000); // after 1 second logs "Batman"
说说关于this
但是不管函数是按哪种方法来调用的,请记住一点:谁调用这个函数或方法,this关键字就指向谁
- 普通函数调用
//这个地方person作为window的方法来调用,在代码的一开始定义了一个全局变量name,值为xl,它相当于window的一个属性,即window.name="xl",又因为在调用person的时候this是指向window的,因此这里会输出xl.
function person(){
this.name="xl";
console.log(this);
console.log(this.name);
}
person(); //输出 window xl
var name="xl";
function person(){
console.log(this.name);
}
person(); //输出 xl
- 作为方法来调用
var name="XL";
var person={
name:"xl",
showName:function(){
console.log(this.name);
}
}
person.showName(); //输出 xl
//这里是person对象调用showName方法,很显然this关键字是指向person对象的,所以会输出name
var showNameA=person.showName;
showNameA(); //输出 XL
//这里将person.showName方法赋给showNameA变量,此时showNameA变量相当于window对象的一个属性,因此showNameA()执行的时候相当于window.showNameA(),即window对象调用showNameA这个方法,所以this关键字指向window
var personA={
name:"xl",
showName:function(){
console.log(this.name);
}
}
var personB={
name:"XL",
sayName:personA.showName
}
personB.sayName(); //输出 XL
//虽然showName方法是在personA这个对象中定义,但是调用的时候却是在personB这个对象中调用,因此this对象指向
- 作为构造函数来调用
function Person(name){
this.name=name;
}
var personA=Person("xl");
console.log(personA.name); // 输出 undefined
console.log(window.name);//输出 xl
//上面代码没有进行new操作,相当于window对象调用Person("xl")方法,那么this指向window对象,并进行赋值操作window.name="xl".
var personB=new Person("xl");
console.log(personB.name);// 输出 xl
//这部分代码的解释见下
//下面这段代码模拟了new操作符(实例化对象)的内部过程
function person(name){
var o={};
o.__proto__=Person.prototype; //原型继承
Person.call(o,name);
return o;
}
var personB=person("xl");
console.log(personB.name); // 输出 xl
//因此`person("xl")`返回了一个继承了`Person.prototype`对象上的属性和方法,以及拥有`name`属性为"xl"的对象,并将它赋给变量`personB`.
所以`console.log(personB.name)`会输出"xl"
- call/apply方法调用
var name="XL";
var Person={
name:"xl",
showName:function(){
console.log(this.name);
}
}
Person.showName.call(); //输出 "XL"
//这里call方法里面的第一个参数为空,默认指向window。
//虽然showName方法定义在Person对象里面,但是使用call方法后,将showName方法里面的this指向了window。因此最后会输出"XL";
funtion FruitA(n1,n2){
this.n1=n1;
this.n2=n2;
this.change=function(x,y){
this.n1=x;
this.n2=y;
}
}
var fruitA=new FruitA("cheery","banana");
var FruitB={
n1:"apple",
n2:"orange"
};
fruitA.change.call(FruitB,"pear","peach");
console.log(FruitB.n1); //输出 pear
console.log(FruitB.n2);// 输出 peach
- Function.prototype.bind()方法
var name="XL";
function Person(name){
this.name=name;
this.sayName=function(){
setTimeout(function(){
console.log("my name is "+this.name);
},50)
}
}
var person=new Person("xl");
person.sayName() //输出 “my name is XL”;
//这里的setTimeout()定时函数,相当于window.setTimeout(),由window这个全局对象对调用,因此this的指向为window, 则this.name则为XL
var name="XL";
function Person(name){
this.name=name;
this.sayName=function(){
setTimeout(function(){
console.log("my name is "+this.name);
}.bind(this),50) //注意这个地方使用的bind()方法,绑定setTimeout里面的匿名函数的this一直指向Person对象
}
}
var person=new Person("xl");
person.sayName(); //输出 “my name is xl”;
如何更改普通函数this指向
- this在不同场景下的指向
1.普通函数中 this 指向 window
2.定时器中的 this 也是指向 window
3.构造函数中的 this 指向实例化对象
4.方法中的 this 指向调用者
5.事件处理函数中的 this 指向事件源
6.自调用函数中的 this 指向 window
7.箭头函数中的 this 指向上一级 this 或者所在作用域的 this
- 修改this指向的三种方法
1.call方法
function fn(sex){
console.log(this)
this.sex = sex
}
let obj = {uname:'阿飞',age:22}
//第一个参数是修改this指向谁,后面的参数用来传参
fn.call(obj, '男')
// 函数调用call,call会让函数执行,执行过程中改变this指向
2.apply方法
function fn(sex){
console.log(this)
this.sex = sex
}
let obj = {uname:'阿飞',age:22}
//用法跟 call 方法相同,不同之处就是除第一个参数外,后面的参数是放在一个数组里面,
fn.apply(obj, ['男'])
// 函数调用apply,apply会让函数执行,执行过程中改变this指向
3.bind 方法
//不会让函数执行而是相当于返回一个改变this之后的函数
function fn(sex) {
console.log(this)
this.sex = sex
}
let obj = { uname: '阿飞', age: 22 }
fn.bind(obj, '男')()
// 函数调用bind,bind不会让函数执行,执行过程中改变this指向
apply bind call区别
- 参数区别
//call 方法第一个参数是要绑定给this的值,后面传入的是一个参数列表,当第一个参数为null、undefined的时候,默认指向window
Fun.call(obj,'arg1', 'arg2')
//apply接受两个参数,第一个参数是要绑定给this的值,第二个参数是一个参数数组。当第一个参数为null、undefined的时候,默认指向window
Fun.apply(obj,['arg1', 'arg2'])
//bind接受两个参数,第一个参数是要绑定给this的值,第二个参数是一个参数数组,这一点与apply相同。
- 调用区别
call、apply都是立即调用。bind 方法不会立即执行,而是返回一个改变了上下文 this 后的函数,便于稍后调用。而原函数 中的 this 并没有被改变,依旧指向原来该指向的地方。bind应用场景:给参数指定默认参数、绑定构造函数
function fn(a, b, c) {
console.log(a, b, c);
}
var fn1 = fn.bind(null, 'Dog');
fn('A', 'B', 'C'); // A B C
fn1('A', 'B', 'C'); // Dog A B
fn1('B', 'C'); // Dog B C
fn.call(null, 'Dog');
手写bind方法(可以不用apply或call吗)
function fn(a,b,c){
console.log('this---------',this);
console.log('参数',a,b,c);
}
//bind函数
Function.prototype.bind1=function(){
console.log('arguments--',arguments);
//把arguments转换成数组
let arr=Array.prototype.slice.call(arguments)
let t=arr.shift();
let _this=this;
return function(){
return _this.apply(t,arr)
}
}
let fn1=fn.bind1({x:100},10,20,30)
console.log(fn1());
promise介绍一下
注意看一些这方面的程序输出题
Promise是异步编程的一种解决方案,可以替代传统的解决方案–回调函数和事件。ES6统一了用法,并原生提供了Promise对象。作为对象,Promise有一下两个特点: * (1)对象的状态不受外界影响。 * (2)一旦状态改变了就不会在变,也就是说任何时候Promise都只有一种状态。
Promise有三种状态,分别是:Pending(进行中),Resolved(已完成),Rejected(已失败)。Promise从Pending状态开始,如果成功就转到成功态,并执行resolve回调函数;如果失败就转到失败状态并执行reject回调函数
//Promise构造函数接收一个函数作为参数,该函数的两个参数是resolve,reject,它们由JavaScript引擎提供。其中resolve函数的作用是当Promise对象转移到成功,调用resolve并将操作结果作为其参数传递出去;reject函数的作用是单Promise对象的状态变为失败时,将操作报出的错误作为其参数传递出去。如下面的代码:
function greet(){
var promise = new Promise(function(resolve,reject){
var greet = "hello world";
resolve(greet);
});
return promise;
}
greet().then(v=>{
console.log(v);//resolve()传递出来的参数
})
//创建一个Promise对象会立即执行里面的代码,所以为了更好的控制代码的运行时刻,可以将其包含在一个函数中,并将这个Promise作为函数的返回值。
- Promise的then方法
promise的then方法带有以下三个参数:成功回调,失败回调,前进回调,一般情况下只需要实现第一个,后面是可选的。Promise中最为重要的是状态,通过then的状态传递可以实现回调函数链式操作的实现。先执行以下代码:
function greet(){
var promise = new Promise(function(resolve,reject){
var greet = "hello world";
resolve(greet);
});
return promise;
}
var p = greet().then(v=>{
console.log(v);
})
console.log(p);
//打印:Promimse{}
//hello world
//promise执行then还是一个promise,并且Promise的执行是异步的,因为hello world在最后一条输出语句的前面就打印出来,且Promise的状态为pending(进行中)。
因为Promise执行then后还是Promise,所以就可以根据这一特性,不断的链式调用回调函数。下面是一个 例子:
function greet(){
var promise = new Promise(function(resolve,reject){
var greet = "hello world";
resolve(greet);
});
return promise;
}
greet().then(v=>{
console.log(v+1);
return v;
})
.then(v=>{
console.log(v+2);
return v;
})
.then(v=>{
console.log(v+3);
})
function judgeNumber(num){
var promise1 = new Promise(function(resolve,reject){
num =5;
if(num<5){
resolve("num小于5,值为:"+num);
}else{
reject("num不小于5,值为:"+num);
}
});
return promise1;
}
//.then后包含有两个方法,前一个执行resolve回调的参数,后一个执行reject回调的参数。
judgeNumber().then(
function(message){
console.log(message);
},
function(message){
console.log(message);
}
)
- all用法
Promise的all方法提供了并行执行异步操作的能力,在all中所有异步操作结束后才执行回调。(回调函数需要等到所有的Promise都执行完再执行)
function p1(){
var promise1 = new Promise(function(resolve,reject){
console.log("p1的第一条输出语句");
console.log("p1的第二条输出语句");
resolve("p1完成");
})
return promise1;
}
function p2(){
var promise2 = new Promise(function(resolve,reject){
console.log("p2的第一条输出语句");
setTimeout(()=>{console.log("p2的第二条输出语句");resolve("p2完成")},2000);
})
return promise2;
}
function p3(){
var promise3 = new Promise(function(resolve,reject){
console.log("p3的第一条输出语句");
console.log("p3的第二条输出语句");
resolve("p3完成")
});
return promise3;
}
Promise.all([p1(),p2(),p3()]).then(function(data){
console.log(data);
})
//输出
//p1第一条 p1第二条 p2第一条 p3第一条 p3第二条 p2第二条
//['p1完成','p2完成','p3完成']
//race用法,race等到第一个Promise改变状态就开始执行回调函数
Promise.race([p1(),p2(),p3()]).then(function(data){
console.log(data);
})
//输出
//p1 p1 p2 p3 p3 p1完成 p2第二条
注意:由于promise是异步的,所以不要在后面的代码里添加依赖promise改变的代码
手写了一个Promise.all()
Promise.all() 方法接收一个promise的iterable类型(注:Array,Map,Set都属于ES6的iterable类型)的输入。 —— 说明所传参数都具有Iterable,也就是可遍历。并且只返回一个Promise实例。—— 说明最终返回是一个Promise对象。
那个输入的所有promise的resolve回调的结果是一个数组。—— 说明最终返回的结果是个数组,且数组内数据要与传参数据对应。这个Promise的resolve回调执行是在所有输入的promise的resolve回调都结束,或者输入的iterable里没有promise了的时候。—— 说明最终返回时,要包含所有的结果的返回。它的reject回调执行是,只要任何一个输入的promise的reject回调执行或者输入不合法的promise就会立即抛出错误,并且reject的是第一个抛出的错误信息。—— 说明只要一个报错,立马调用reject返回错误信息。
const PromiseAll = (iterator) => {
const promises = Array.from(iterator); // 对传入的数据进行浅拷贝,确保有遍历器
const len = promises.length; // 长度
let index = 0; // 每次执行成功+1,当等于长度时,说明所有数据都返回,则可以resolve
let data = []; // 用来存放返回的数据数组
return new Promise((resolve, reject) => {
for (let i in promises) {
promises[i]
.then((res) => {
data[i] = res;
if (++index === len) {
resolve(data);
}
})
.catch((err) => {
reject(err);
});
}
});
};
const promise1 = Promise.resolve('promise1');
const promise2 = new Promise(function (resolve, reject) {
setTimeout(resolve, 2000, 'promise2');
});
const promise3 = new Promise(function (resolve, reject) {
setTimeout(resolve, 1000, 'promise3');
});
PromiseAll([promise1, promise2, promise3]).then(function(values) {
console.log(values);
});
追踪Promise的错误
- ES5的异常捕获通过try catch
//报错,捕获不到,settimeout进入异步任务队列
try {
setTimeout(function() {
throw new Error("error")
}, 1000)
} catch(e) {
console.log(e)
}
//修改
setTimeout(() => {
try {
throw new Error("error")
} catch(e) {
console.log(e);
}
}, 1000);
- ES6通过promise的rejected捕获
function fn() {
return new Promise((resolve, reject) => {
setTimeout(() => {
reject("error")
}, 1000)
})
}
fn()
.catch(err => {
console.log(err)
})
- ES6通过async,await优化promise时的异常捕获
//报错in promise error
function fn() {
return new Promise((resolve, reject) => {
setTimeout(() => {
reject("error")
}, 1000)
})
}
async function go() {
let res = await fn()
console.log(res)
}
go()
//解决方式1 在go中添加try catch,但这样 不够优雅
//解决方式2 通过返回一个pending状态的结果终端promise链的方式
function fn() {
return new Promise((resolve, reject) => {
setTimeout(() => {
//reject("error")
return new Promise(() => {}) //中断promise链
}, 1000)
})
}
async function go() {
let res = await fn()
console.log(e)
}
go()
- 通过监听unhandledrejection事件,可以捕获未处理的Promise错误。
window.addEventListener('unhandledrejection', event => ···);
//这个事件是PromiseRejectionEvent实例,它有2个最重要的属性:
//1.promise: reject的Promise
//2.reason: Promise的reject值
//示例代码:
window.addEventListener('unhandledrejection', event =>
{
console.log(event.reason); // 打印"Hello, Fundebug!"
});
function foo()
{
Promise.reject('Hello, Fundebug!');
}
foo();
async/await
- async/await是写异步代码的新方式,以前的方法有回调函数和promise
- async/await是基于promose实现的,他不能用于普通的函数
- async/await与promise一样,是非阻塞的
- async/await使得异步代码看起来像同步代码
如果await等到的是一个 Promise 对象,await 就忙起来了,它会阻塞后面的代码,等着 Promise 对象 resolve,然后得到 resolve 的值,作为 await 表达式的运算结果。其实这就是 await 必须用在 async 函数中的原因。async 函数调用不会造成阻塞,它内部所有的阻塞都被封装在一个 Promise 对象中异步执行。
- promise 使用 .then 链式调用,但也是基于回调函数
- async/await 更加优雅的异步编程的写法
1.它是消灭异步回调的终极武器;2.它是同步语法,也就是用同步的写法写异步的代码
- 例子(异步加载图片)
//里面函数为AJAX,因此是异步任务
let loadImg = (url)=>{
const p = new Promise((resolve,reject)=>{
let newImg = document.createElement("img")
newImg.src = url
newImg.onload = function(){
resolve(newImg)
}
newImg.error = function(){
reject(new Error('Could not load Image at url'))
}
})
return p
}
//通过 .then 来获取结果
loadImg(url1)
.then((img)=>{
console.log(img.width,img.height)
document.body.appendChild(img)
return loadImg(url2)
})
.then((img)=>{
console.log(img.width,img.height)
document.body.appendChild(img)
})
.catch((err)=>{
console.log(err)
})
//使用 async 和 await 的方法来写,立即执行函数
(async function(){
// loadImg(url1) 返回 promise 对象
// await 可以拿到从 resolve 传递过来的 dom 对象
const img1 = await loadImg(url1)
document.body.appendChild(img1)
const img2 = await loadImg(url2)
document.body.appendChild(img2)
})()
//await 接 async 函数
async function loadImg1(){
const img1 = await loadImg(url1)
return img1
}
(async function(){
//img1可以拿到 resolve 里面的值
const img1 = await img1
document.body.appendChild(img1)
})()
- 执行顺序
function timeout(){
return new Promise(resolve=>{
setTimeout(()=>{
console.log(1)
resolve()//成功态
})
})
}
//情况一
async function fn(){
timeout()
console.log(2)
}
fn() //打印出 2 一秒后 1
//情况2
async function fn(){
await timeout()
console.log(2)
}
fn() //1秒后打印出 1 2
//写法二
function timeout(){
return new Promise(resolve=>{
setTimeout(()=>{
resolve(1)//成功态,传递参数1
})
})
}
async function fn(){
const res = await timeout() //需要一个变量来接收await return的参数
console.log(res)
console.log(2)
}
fn() //1秒后打印出 1 2
- async/await的实质
1.Promise一般用来解决层层嵌套的回调函数2.async/await 是消灭异步回调的终极武器3.JS还是单线程,还是得有异步,还是得基于 event loop(轮询机制)4.async/await 只是一个语法糖
//1.可以使用promise的.then 链式层层调用
//2.也可以使用 async/await ,用同步的代码来解决异步问题
//依次获取数据,完全是同步的写法
//await会等待该行代码完全运行,才执行后面的代码
async function getDate(){
const res1 = await request("./a.json")
console.log(res1)
const res1 = await request("./b.json")
console.log(res2)
const res1 = await request("./c.json")
console.log(res3)
}
async/await和Promise的关系
-
async/await 是消灭异步回调的终极武器
-
但和Promise并不排斥,两者相辅相成
-
执行 async 函数,返回的是 Promsie 对象
-
await 相当于 Promise 的 then ,then指的是成功,不指失败
-
try…catch 可捕获异常,代替了 Promise的 catch
-
await 后面接 Promise
1.await p1相当于是 p1.then,并且只是成功态的then
2.await 和 then 的区别就是:then还需要传回调进去,但 await 可以直接得到值
(async function(){
const p1 = Promise.resolve(300) //一个成功态的promise对象,且传了result为300
const res = await p1 // return 值
console.log(res) // 300
})
- 区别
fn().then(
data=>{
console.log(data)
}
)
//await直接通过返回值来接收daita, return data
const res = await fn()
//await后面跟的不是promise对象而是数值时,会自动包装成成功态的promise对象,并且传值给 resolve 为400
(async function(){
const res = await 400 //Promise.resolve(400)
console.log(res) //400
})()
//接async函数
(async function(){
const res = await fn() //fn()会返回promise对象,原理一样
console.log(res) //400
})()
//接promise为空
//1.什么都打印不出来,因为 new Promise 里面没有任何状态改变,而await一直在等待状态改变,只有状态改变了,await才会允许执行后面的代码
(async function(){
const p = new Promise(()=>{})
const res = await p
console.log(res)
console.log("success")
})()
//接promise的error
//1.会出现报错,await相当于成功态的 .then ,都没有成功,因此不会执行后面的代码,因为JS是单线程的。解决:使用 try…catch 偷偷解决掉 error,保证代码运行——捕获到错误就不会影响后面的输出
(async function(){
const p = Promise.reject("error")
const res = await p
console.log(res)
console.log("success")
})() //什么都打印不出来
(async function(){
const p = Promise.reject("error")
try{
const res = await p
console.log(res)
}catch(error){
console.log(error)
}
console.log("success")
})() //打印出 error 和 success
async输出顺序
- 一道例子
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2 start');
return new Promise((resolve, reject) => {
resolve();
console.log('async2 promise');
})
}
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
}).then(function() {
console.log('promise3');
});
//输出顺序
async1 start
async2 start
async2 promise
promise1
promise2
promise3
async1 end
闭包
闭包就是能够读取其他函数内部变量的函数,是定义在一个函数内部的函数,本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
//f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
function f1(){
var n=999;
nAdd=function(){n+=1}
function f2(){
alert(n);
}
return f2;
}
var result=f1();
result(); // 999
nAdd();
result(); // 1000
闭包造成内存泄漏:因为闭包就是能够访问外部函数变量的一个函数,而函数是必须保存在内存中的对象,所以位于函数执行上下文中的所有变量也需要保存在内存中,这样就不会被回收,如果一旦循环引用或创建闭包,就会占据大量内存,可能会引起内存泄漏。
//解决内存泄露问题(在退出函数之前将不使用的局部变量全部删除,可以使变量赋值为null
//这段代码会导致内存泄露
window.onload = function(){
var el = document.getElementById("id");
el.onclick = function(){
alert(el.id);
}
}
//解决方法为
window.onload = function(){
var el = document.getElementById("id");
var id = el.id; //解除循环引用
el.onclick = function(){
alert(id);
}
el = null; // 将闭包引用的外部函数中活动对象清除
}
//由于jQuery考虑到了内存泄漏的潜在危害,所以它会手动释放自己指定的所有事件处理程序。只要坚持使用jQuery的事件绑定方法,就可以一定程度上避免这种特定的常见原因导致的内存泄漏。
- 闭包的使用场景
封装功能时(需要使用私有的属性和方法),函数防抖、函数节流、函数柯里化、给元素伪数组添加事件需要使用元素的索引值。
函数防抖
//就是指触发事件后在 n 秒内函数只能执行一次,如果在 n 秒内又触发了事件,则会重新计算函数执行时间。通俗一点:在一段固定的时间内,只能触发一次函数,在多次触发事件时,只执行最后一次。
//搜索功能,在用户输入结束以后才开始发送搜索请求,可以使用函数防抖来实现;
/**
* @function debounce 函数防抖
* @param {Function} fn 需要防抖的函数
* @param {Number} interval 间隔时间
* @return {Function} 经过防抖处理的函数
* */
function debounce(fn, interval) {
let timer = null; // 定时器
return function() {
// 清除上一次的定时器
clearTimeout(timer);
// 拿到当前的函数作用域
let _this = this;
// 拿到当前函数的参数数组
let args = Array.prototype.slice.call(arguments, 0);
// 开启倒计时定时器
timer = setTimeout(function() {
// 通过apply传递当前函数this,以及参数
fn.apply(_this, args);
// 默认300ms执行
}, interval || 300)
}
}
函数节流
//就是限制一个函数在一定时间内只能执行一次。
//改变浏览器窗口尺寸,可以使用函数节流,避免函数不断执行;滚动条scroll事件,通过函数节流,避免函数不断执行。
/**
* @function throttle 函数节流
* @param {Function} fn 需要节流的函数
* @param {Number} interval 间隔时间
* @return {Function} 经过节流处理的函数
* */
function throttle(fn, interval) {
let timer = null; // 定时器
let firstTime = true; // 判断是否是第一次执行
// 利用闭包
return function() {
// 拿到函数的参数数组
let args = Array.prototype.slice.call(arguments, 0);
// 拿到当前的函数作用域
let _this = this;
// 如果是第一次执行的话,需要立即执行该函数
if(firstTime) {
// 通过apply,绑定当前函数的作用域以及传递参数
fn.apply(_this, args);
// 修改标识为null,释放内存
firstTime = null;
}
// 如果当前有正在等待执行的函数则直接返回
if(timer) return;
// 开启一个倒计时定时器
timer = setTimeout(function() {
// 通过apply,绑定当前函数的作用域以及传递参数
fn.apply(_this, args);
// 清除之前的定时器
timer = null;
// 默认300ms执行一次
}, interval || 300)
}
}
> 函数节流与函数防抖的区别:我们以一个案例来讲一下它们之间的区别:设定一个间隔时间为一秒,在一分钟内,不断的移动鼠标,让它触发一个函数,打印一些内容。函数防抖:会打印1次,在鼠标停止移动的一秒后打印。函数节流:会打印60次,因为在一分钟内有60秒,每秒会触发一次。总结:节流是为了限制函数的执行次数,而防抖是为了限制函数的执行时机。
写一个原生伪代码new函数(用js实现New方法)
function Person (name, age) {
this.name = name;
this.age = age;
this.habit = 'Games';
}
Person.prototype.strength = 60;
Person.prototype.sayYourName = function () {
console.log('I am ' + this.name);
}
function myNew(fn, ...args) {
let obj = new Object() // 首先创建一个空的对象
let F=function(){};
F.prototype= fn.prototype;
obj=new F();//指向原型
let ret = fn.apply(obj, args) // 用fn这个构造函数,把其作用域指向obj对象,参数为args
//若构造函数fn返回的是引用类型,就返回ret;
//若构造函数fn返回的是基本类型,就返回obj;
return typeOf ret === 'object' ? ret : obj; //确保构造器总是返回一个对象
};
var person1 = myNew(Person, 'Kevin', '18')
深拷贝和浅拷贝
- 浅拷贝只是拷贝一层,更深层次对象级别的只拷贝引用。
- 浅拷贝是拷贝的内存地址,使新对象指向拷贝对象的内存地址。深拷贝是重新开辟一块内存空间,用来存放sources对象的值。
- 浅拷贝可以用for in 来实现,也可用es6新增方法Object.assign(target,…sources) 来实现,target为目标对象,sources为原对象(要进行拷贝的对象)
- 浅拷贝后改变target中的值,sources也会进行改变。深拷贝不会这样
- 深拷贝可以基于函数封装的方法来进行实现。
map和foreach的区别
- 总的来说 map 的速度大于forEach。
- map会返回一个新的数组,不会改变原来的数组,forEach不会返回新数组,允许对原数组进行修改。
- 都有参数,item, index arr 。
- 内部匿名函数的this指向都是window。
var arr = [1,2,3]
var str = arr.map((value,index,arr) => {
return value/2
})//这个得到的str为[0.5,1,1.5]
var str = arr.forEach((value,index,arr) =>{
return value/2
})//这个得到的str为undefined
- jQuery中的$.each()(无返回值)
$.each(arr, function(index,value){})
- jQuery中的$.map()(有返回值可以return出来)
$.map(arr, function(value, index){
return XXX
})
for in for of区别
- 遍历数组通常使用for循环
ES5的话也可以使用forEach,ES5具有遍历数组功能的还有map、filter、some、every、reduce、reduceRight等,只不过他们的返回结果不一样。但是使用foreach遍历数组的话,使用break不能中断循环,使用return也不能返回到外层函数。
- for in 遍历数组的毛病
1.index索引为字符串型数字,不能直接进行几何运算
2.遍历顺序有可能不是按照实际数组的内部顺序
3.使用for in会遍历数组所有的可枚举属性,包括原型。例如上栗的原型方法method和name属性
所以for in更适合遍历对象,不要使用for in遍历数组。那么除了使用for循环,如何更简单的正确的遍历数组达到我们的期望呢(即不遍历method和nam e),ES6中的for of更胜一筹.
for in遍历的是数组的索引(即键名),而for of遍历的是数组元素值。for of遍历的只是数组内的元素,而不包括数组的原型属性method和索引name
- 遍历对象
遍历对象通常使用for in来遍历对象的键名
Object.prototype.method=function(){
console.log(this);
}
var myObject={
a:1,
b:2,
c:3
}
for (var key in myObject) {
console.log(key);
}
//打印a b c
- 总结
for…of适用遍历数/数组对象/字符串/map/set等拥有迭代器对象的集合.但是不能遍历对象,因为没有迭代器对象.与forEach()不同的是,它可以正确响应break、continue和return语句for-of循环不支持普通对象,但如果你想迭代一个对象的属性,你可以用for-in循环(这也是它的本职工作)或内建的Object.keys()方法:
实现一个for循环内的setTImeout输出
- 问题
//这种情况会输出5个6
for (var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
//这种情况fun没有发现实参所以仍然是5个6
for (var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
- 解决方案1:闭包(经典)
//实际参数跟定时器内部的i有强依赖
for (var i=1; i<=5; i++) {
(function(j) {
setTimeout( function timer() {
console.log( j );
}, j*1000 );
})(i);
}
- 解决方案2:拆分结构
//定时器和循环放在不同的部分
function timer(i) {
setTimeout( console.log( i ), i*1000 );
}
for (var i=1; i<=5;i++) {
timer(i);
}
- 解决方案3:let
//因为for循环头部的let不仅将i绑定到for循环中,事实上它将其重新绑定到循环体的每一次迭代中,确保上一次迭代结束的值重新被赋值。setTimeout里面的function()属于一个新的域,通过var定义的变量是无法传入到这个函数执行域中的,通过使用let来声明块变量能作用于这个块,所以function就能使用i这个变量了,这个匿名函数的参数作用域和for参数的作用域不一样,是利用了这一点来完成的。这个匿名函数的作用域有点类似类的属性,是可以被内层方法使用的。
for (let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
- 解决方案4:setTimeout第三个参数
//由于每次传入的参数是从for循环里面取到的值,所以会依次输出1到5。
for (let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000, i );
}
类数组有什么用?跟数组有什么区别?如何转化?
- 类数组
//类数组是指在写法上跟数组一样,比如arguments,函数的第一个参数是argument[0],写法上跟数组一样,但是不是数组,他的原型是Object。
function functionName() {
console.log(arguments);
}
functionName(3, 5)
Arguments(2) [3, 5, callee: ƒ, Symbol(Symbol.iterator): ƒ]
0:3
1:5
callee:ƒ functionName()
length:2
Symbol(Symbol.iterator):ƒ values()
__proto__:Object
//打印出来之后可以看到其实他的构造函数是Object,只不过这个对象的key值是0,1…写出来之后类似数组的下标,所以叫类数组。
var arr = ['你好', 'json', 'array']
var obj = {
0: '你好',
1: 'json',ds
2: 'array',
length: 3
}
//上面代码不难看出,obj也有length属性,访问属性也可以通过obj[0]的方式去访问,这样的对象就可以说是类数组。但是他又不是数组,因为它不能使用数组的push等方法。但是我们也可以通过下面的方法去调用。
arr.push('新的元素');
[].push.call(obj, '新的元素');
console.log(arr, obj)
Array.prototype.push = function (target) {
this[this.length] = target;
this.length ++;
}
let obj = {
"0": 'a',
"1": 'b',
"2": 'c',
length: 3,
push: Array.prototype.push,
splice: Array.prototype.splice
}
- 如何将类数组转化为数组
//ES6+
//现成的API
// [undefined, undefined, undefined]
Array.from({ length: 3 })
// 适用于 iterable 对象
//... 扩展运算符,不过它只能作用于 iterable 对象,即拥有 Symbol(Symbol.iterator) 属性值
[...document.querySelectorAll('div')]
//但是严格意义上来说,它不能把类数组转化为数组,如 { length: 3 }。它将会抛出异常
// Uncaught TypeError: object is not iterable (cannot read property Symbol(Symbol.iterator))
[...{length: 3}]
//ES5
const arrayLike = {
0: 3,
1: 4,
2: 5,
length: 3
}
//在 ES5 中可以借用 Array API 通过 call/apply 改变 this 或者 arguments 来完成转化。最常见的转换是 Array.prototype.slice
//(借用 arguments)
Array.apply(null, arrayLike)
//(借用 arguments)
Array.prototype.concat.apply([], arrayLike)
//(借用 this)
Array.prototype.slice.call(arrayLike)
Array.prototype.map.call(arrayLike, x => x)
Array.prototype.filter.call(arrayLike, x => 1)
//总结
//最靠谱的
Array.from(arrayLike)
Array.apply(null, arrayLike)
Array.prototype.concat.apply([], arrayLike)
//需要考虑稀疏数组的转化
Array.prototype.filter.call(divs, x => 1)
Array.prototype.map.call(arrayLike, x => x)
Array.prototype.filter.call(arrayLike, x => 1)
//以下方法要注意是否是 iterable object
[...arrayLike]
set map 特点,weakSet weakMap
- Set
1.Set 是一种叫做集合的数据结构,类似于数组,但成员是唯一且无序的,没有重复的值。
2.Set本身是一个构造函数,用来生成 Set 数据结构。
- WeakSet
WeakSet跟Set区别:
1.WeakSet 的成员只能是对象,而不能是其他类型的值,而 Set 对象都可以
2.WeakSet 中的对象都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于 WeakSet 之中。
- Map
1.Map 是一种叫做字典的数据结构,类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
- WeakMap
WeakMap跟Map区别:
1.WeakMap只接受对象作为键名(null除外),不接受其他类型的值作为键名
2.WeakMap的键名所指向的对象,不计入垃圾回收机制
扁平化(flatten)数组
- JS扁平化分类
1.对象扁平化(深度很深的对象,经过扁平化编程深度为 1 的对象)
2.数组扁平化(降维过程,多维数组经过扁平化变成一维数组)。
数组的扁平化,是将一个嵌套多层的数组 array (嵌套可以是任何层数)转换为只有一层的数组。
- 方法1
递归实现,取出数组中的值然后递归判断
function flatten(arr) {
// 判断参数是否是数组,检测数组元素是否是整数或者数组
var result = [];
if (!Array.isArray(arr)) {
// 不是数组, 判断是否是整数
if (arr % 1 == 0) {
result.push(arr);
} else {
throw Error('The parameter contains NaN or contains not Integer!');
}
} else {
// 是数组,遍历
for (let i = 0; i < arr.length; i++) {
result = result.concat(flatten(arr[i]));
}
}
return result;
}
- 方法2
改进方法一
//利用reduce实现
function flatten(arr) {
return arr.reduce(function (prev, next) {
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}
- 方法三
不使用递归,使用扩展运算符展开数组实现
//利用扩展运算符
function flatten(arr) {
var arr;
while (arr.some(v => Array.isArray(v))) {
arr = [].concat(...arr);
}
return arr;
}
- 方法四
不使用递归也不使用循环,使用字符串利用正则去掉中括号,这样实现最简单且消耗最小
//扁平化数组(不使用循环,使用字符串)
function flatten(arr) {
let str = JSON.stringify(arr).replace(/\[|\]/g, '');
return JSON.parse(Array.of('[' + str + ']')[0]);
}
系统提供
- flat(返回一个新数组, depth指定嵌套数组中的结构深度,默认值为1,不管多少层则可以用Infinity关键字作为参数。有兼容性问题, 不建议使用)
[1, 2, [3]].flat(1) // [1, 2, 3]
[1, 2, [3, [4]]].flat(2) // [1, 2, 3, 4]
[1, 2, [3, [4, [5]]]].flat(Infinity) // [1, 2, 3, 4, 5]
- reduce
function flatten(arr) {
return arr.reduce((a, b) => {
// return Array.isArray(b) ? a.concat(flatten(b)) : a.concat(b);
return a.concat(Array.isArray(b) ? flatten(b) : b);
}, []);
};
// es6
const flatten = arr =>
arr.reduce((a, b) => a.concat(Array.isArray(b) ? flatten(b) : b), []);
flatten([1,[2,3],4,[[5,6],7]]) // [1, 2, 3, 4, 5, 6, 7]
- toString(只适于数组的元素都是数字)
function flatten(arr) {
return arr.toString().split(",").map(item => +item);
};
flatten([1,[2,3],4,[[5,6],7]]) // [1, 2, 3, 4, 5, 6, 7]
- [].concat(…arr)
function flatten(arr) {
return !Array.isArray(arr) ? arr : [].concat.apply([], arr.map(flatten));
}
flatten([1,[2,3],4,[[5,6],7]]) // [1, 2, 3, 4, 5, 6, 7]
- generator
function* flatten(arr) {
if (!Array.isArray(arr)) yield arr;
else for (let el of arr) yield* flatten(el);
}
let flattened = [...flatten([1,[2,[3,[4]]]])]; // [1, 2, 3, 4]
- 字符串过滤
const flatten = arr => JSON.parse(`[${JSON.stringify(arr).replace(/\[|]/g,'')}]`);
- undercore or lodash 库
_.flatten([1, [2], [3, [[4]]]]);
=> [1, 2, 3, 4];
setTimout模拟setInterval
var timer;
var i = 1;
timer = function () {
i++;
console.log(i);
if (i == 10) {
timer = function () {
console.log("终止运行");
}
}
setTimeout(timer, 500);
};
console.log(timer);
setTimeout(timer, 500);
迭代器 生成器
- 迭代器
迭代器是一个对象,是确使用户可在容器对象(container,例如链表或数组)上遍访的对象,使用该接口无需关心对象的内部实现细节。迭代器有next属性,其对应的方法有如下的要求:一个无参数或者一个参数的函数,返回一个应当拥有以下两个属性的对象:done(boolean) ü 如果迭代器可以产生序列中的下一个值,则为 false。(这等价于没有指定 done 这个属性。)如果迭代器已将序列迭代完毕,则为 true。这种情况下,value 是可选的,如果它依然存在,即为迭代结束之后的默认返回值。value迭代器返回的任何 JavaScript 值。done 为 true 时可省略。
const friends = ['lilei', 'kobe', 'james'];
let index = 0
const friendsIterator = {
next: function() {
if (index < friends.length)
return { done: false, value: friends[index++] }
} else {
return { done: true, value: friends[index++] }
}
}
console.log(friendsIterator.next().value);
console.log(friendsIterator.next().value);
console.log(friendsIterator.next().value);
//可迭代对象
//当一个对象实现了iterable protocol协议时,它就是一个可迭代对象;它和迭代器是不一样的。这个对象的要求是必须实现 @@iterator 方法,在代码中我们使用 Symbol.iterator 访问该属性;
// 可迭代对象
const iteratorObj = {
names: ['leilei', 'tom', 'mark'],
index: 0,
[Symbol.iterator]: function() {
return {
// 这边使用箭头函数,以使this指向iteratorObj
next: () => {
if (this.index < this.names.length) {
return { done: false, value: this.names[this.index++] }
} else {
return { done: true, value: 'no name' }
}
}
}
}
}
// 获取迭代器
const iterator1 = iteratorObj[Symbol.iterator]()
console.log(iterator1.next());
console.log(iterator1.next());
console.log(iterator1.next());
console.log(iterator1.next());
//事实上我们平时创建的很多原生对象已经实现了可迭代协议,会生成一个迭代器对象的:String、Array、Map、Set、arguments对象、NodeList集合;
- 生成器
生成器是ES6中新增的一种函数控制、使用的方案,它可以让我们更加灵活的控制函数什么时候继续执行、暂停执行等。生成器函数也是一个函数,但是和普通的函数有一些区别:首先,生成器函数需要在function的后面加一个符号*:其次,生成器函数可以通过yield关键字来控制函数的执行流程:最后,生成器函数的返回值是一个Generator(生成器):生成器事实上是一种特殊的迭代器;
yield表示每次会在这儿停止。其中,yield可以返回值。
function* getName() {
console.log('函数开始执行');
const value1 = 'tom'
console.log(value1)
yield value1
const value2 = 'mary'
console.log(value2);
yield value2
console.log('函数执行结束')
}
// 返回生成器
const iterator = getName()
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
// 函数开始执行
// tom
// { value: 'tom', done: false }
// mary
// { value: 'mary', done: false }
// '函数执行结束'
// { value: undefined, done: true }
//{ value: undefined, done: true }
//next()传递参数
function* sum() {
const value1 = 10;
const n1 = yield value1; // 刚到这是10,则打印的10,然后执行下一句next把5传给这个n1
const value2 = 20 * n1
/**
* 注意此处的n接收的是next()传来的值,和上面的value2的值没有必然关联,当然我们也可以把第一
* 次的结果当作参数传入,视实际情况而定
*/
const n2 = yield value2 // 这个n2的值为10
const value3 = 30 * n2
yield value3
}
const iterator = sum()
console.log('第一次的值:', iterator.next());
console.log('第二次的值:', iterator.next(5)); // 传给第一次yield的返回值
console.log('第三次的值:', iterator.next(10)); // 传给第二次yield的返回值
// 第一次的值: {value: 10, done: false}
// 第二次的值: {value: 100, done: false}
// 第三次的值: {value: 300, done: false}
//生成器提前结束 - return函数
function* sum() {
const value1 = 10;
const n1 = yield value1;
// 相当与在这执行了以下代码
// return 5
const value2 = 20 * n1
const n2 = yield value2
const value3 = 30 * n2
yield value3
}
const iterator = sum()
console.log('第一次的值:', iterator.next());
console.log('第二次的值:', iterator.return(5));
// 第一次的值: {value: 10, done: false}
// 第二次的值: {value: 5, done: true}
//生成器抛出异常 - throw函数
function* sum() {
const value1 = 10;
yield value1;
try {
const value2 = 20
yield 20
} catch (error) {
console.log(error);
yield '哈哈,错了'
}
const value3 = 30
yield value3
}
const iterator2 = sum()
console.log('第一次的值:', iterator2.next());
console.log('第二次的值:', iterator2.next());
// 注意:throw紧跟着上个next()执行异常处理,所以要看好应该进行异常处理的位置
console.log('第三次的值:', iterator2.throw('有错误'));
console.log('第四次的值:', iterator2.next());
// 结果:
// 第一次的值: {value: 10, done: false}
// 第二次的值: {value: 20, done: false}
// 有错误
// 第三次的值: {value: '哈哈,错了', done: false}
// 第四次的值: {value: 30, done: true}
event loop
- 为什么出现 Event Loop
JavaScript是一种单线程语言,所有任务都在一个线程上完成。一旦遇到大量任务或者遇到一个耗时的任务,比如加载一个高清图片,网页就会出现"假死",因为JavaScript停不下来,也就无法响应用户的行为。为了防止主线程的阻塞,JavaScript 有了 同步 和 异步 的概念。
- 同步
如果在一个函数返回的时候,调用者就能够得到预期结果,那么这个函数就是同步的。也就是说同步方法调用一旦开始,调用者必须等到该函数调用返回后,才能继续后续的行为。下面这段段代码首先会弹出 alert 框,如果你不点击 确定 按钮,所有的页面交互都被锁死,并且后续的 console 语句不会被打印出来。
- 异步
如果在函数返回的时候,调用者还不能够得到预期结果,而是需要在将来通过一定的手段得到,那么这个函数就是异步的。比如说发一个网络请求,我们告诉主程序等到接收到数据后再通知我,然后我们就可以去做其他的事情了。当异步完成后,会通知到我们,但是此时可能程序正在做其他的事情,所以即使异步完成了也需要在一旁等待,等到程序空闲下来才有时间去看哪些异步已经完成了,再去执行。
//这里需要等到 for 循环完成才会执行 settimeout,所以时间远远超过1000毫秒
setTimeout(() => {
console.log('yancey');
}, 1000);
for (let i = 0; i < 100000000; i += 1) {
// todo
}
- 事件循环机制 Event Loop
我们注意到,在异步代码完成后仍有可能要在一旁等待,因为此时程序可能在做其他的事情,等到程序空闲下来才有时间去看哪些异步已经完成了。所以 JavaScript 有一套机制去处理同步和异步操作,那就是事件循环 (Event Loop)。
用文字描述的话,大致是这样的:
1.所有同步任务都在主线程上执行,形成一个执行栈 (Execution Context Stack)。
2.而异步任务会被放置到 Task Table,也就是上图中的异步处理模块,当异步任务有了运行结果,就将该函数移入任务队列。
3.一旦执行栈中的所有同步任务执行完毕,引擎就会读取任务队列,然后将任务队列中的第一个任务压入执行栈中运行。
主线程不断重复第三步,也就是 只要主线程空了,就会去读取任务队列,该过程不断重复,这就是所谓的 事件循环。

js错误怎么处理?Window.error
- 错误处理方案
return存在很大的弊端:调用者不知道是因为函数内部没有正常执行,还是执行结果就是一个undefined
- throw关键字
当遇到throw语句时,当前的函数执行会被停止(throw后面的语句不会执行)
function sum(num1, num2) {
// 当传入的参数的类型不正确时, 应该告知调用者一个错误
if (typeof num1 !== "number" || typeof num2 !== "number") {
// return undefined
throw "parameters is error type~"
}
return num1 + num2
}
// 调用者(如果没有对错误进行处理, 那么程序会直接终止)
console.log(sum({ name: "swh" }, true))
// console.log(sum(20, 30))
console.log("后续的代码会继续运行~")
//parameters is error type~
- Error类型
JavaScript已经给我们提供了一个Error类,我们可以直接创建这个类的对象
Error包含三个属性:
1.pmesssage:创建Error对象时传入的message
2.name:Error的名称,通常和类的名称一致
3.pstack:整个Error的错误信息,包括函数的调用栈,当我们直接打印Error对象时,打印的就是stack
Error有一些自己的子类:
1.RangeError:下标值越界时使用的错误类型
2.SyntaxError:解析语法错误时使用的错误类型
3.TypeError:出现类型错误时,使用的错误类型
const err = new TypeError("当前type类型是错误的~")
//TypeError: 当前type类型是错误的~
- 异常的处理
如果我们在调用一个函数时,这个函数抛出了异常,但是我们并没有对这个异常进行处理,那么这个异常会继续传 递到上一个函数调用中.而如果到了最顶层(全局)的代码中依然没有对这个异常的处理代码,这个时候就会报错并且终止程序的运行
- 异常的捕获
function foo() {
console.log(swh); //swh未定义会抛出错误
}
function bar() {
try {
foo() //正常代码逻辑
} catch (error) {
console.log(error); //拿到错误,处理
} finally{
console.log('始终都会执行'); //无论有没有错误都会执行
}
}
function test() {
bar() //上面处理错误,代码正常执行
}
test() //拿到错误,处理,后面代码执行
console.log('错误后执行代码...');
es6中的proxy
- 概述
proxy在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截
//new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为
var proxy = new Proxy(target, handler);
//简单的例子
var target = {
name: 'poetries'
};
var logHandler = {
get: function(target, key) {
console.log(`${key} 被读取`);
return target[key];
},
set: function(target, key, value) {
console.log(`${key} 被设置为 ${value}`);
target[key] = value;
}
}
var targetWithLog = new Proxy(target, logHandler);
targetWithLog.name; // 控制台输出:name 被读取
targetWithLog.name = 'others'; // 控制台输出:name 被设置为 others
console.log(target.name); // 控制台输出: others
// 由于拦截函数总是返回35,所以访问任何属性都得到35
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35
//Proxy 实例也可以作为其他对象的原型对象
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
let obj = Object.create(proxy);
obj.time // 35
Proxy的作用
1.拦截和监视外部对对象的访问
2.降低函数或类的复杂度
3.在复杂操作前对操作进行校验或对所需资源进行管理
- Proxy所能代理的范围–handler
实际上 handler 本身就是ES6所新设计的一个对象.它的作用就是用来 自定义代理对象的各种可代理操作 。它本身一共有13中方法,每种方法都可以代理一种操作.其13种方法如下
// 在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.getPrototypeOf()
// 在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.setPrototypeOf()
// 在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.isExtensible()
// 在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.preventExtensions()
// 在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.getOwnPropertyDescriptor()
// 在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {}) 时。
andler.defineProperty()
// 在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.has()
// 在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.get()
// 在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.set()
// 在删除代理对象的某个属性时触发该操作,比如在执行 delete proxy.foo 时。
handler.deleteProperty()
// 在获取代理对象的所有属性键时触发该操作,比如在执行 Object.getOwnPropertyNames(proxy) 时。
handler.ownKeys()
// 在调用一个目标对象为函数的代理对象时触发该操作,比如在执行 proxy() 时。
handler.apply()
// 在给一个目标对象为构造函数的代理对象构造实例时触发该操作,比如在执行new proxy() 时。
handler.construct()
- Proxy场景
实现私有变量
var target = {
name: 'poetries',
_age: 22
}
var logHandler = {
get: function(target,key){
if(key.startsWith('_')){
console.log('私有变量age不能被访问')
return false
}
return target[key];
},
set: function(target, key, value) {
if(key.startsWith('_')){
console.log('私有变量age不能被修改')
return false
}
target[key] = value;
}
}
var targetWithLog = new Proxy(target, logHandler);
// 私有变量age不能被访问
targetWithLog.name;
// 私有变量age不能被修改
targetWithLog.name = 'others';
//在下面的代码中,我们声明了一个私有的 apiKey,便于 api 这个对象内部的方法调用,但不希望从外部也能够访问 api._apiKey
var api = {
_apiKey: '123abc456def',
/* mock methods that use this._apiKey */
getUsers: function(){},
getUser: function(userId){},
setUser: function(userId, config){}
};
// logs '123abc456def';
console.log("An apiKey we want to keep private", api._apiKey);
// get and mutate _apiKeys as desired
var apiKey = api._apiKey;
api._apiKey = '987654321';
//很显然,约定俗成是没有束缚力的。使用 ES6 Proxy 我们就可以实现真实的私有变量了,下面针对不同的读取方式演示两个不同的私有化方法。第一种方法是使用 set / get 拦截读写请求并返回 undefined:
let api = {
_apiKey: '123abc456def',
getUsers: function(){ },
getUser: function(userId){ },
setUser: function(userId, config){ }
};
const RESTRICTED = ['_apiKey'];
api = new Proxy(api, {
get(target, key, proxy) {
if(RESTRICTED.indexOf(key) > -1) {
throw Error(`${key} is restricted. Please see api documentation for further info.`);
}
return Reflect.get(target, key, proxy);
},
set(target, key, value, proxy) {
if(RESTRICTED.indexOf(key) > -1) {
throw Error(`${key} is restricted. Please see api documentation for further info.`);
}
return Reflect.get(target, key, value, proxy);
}
});
// 以下操作都会抛出错误
console.log(api._apiKey);
api._apiKey = '987654321';
//第二种方法是使用 has 拦截 in 操作
var api = {
_apiKey: '123abc456def',
getUsers: function(){ },
getUser: function(userId){ },
setUser: function(userId, config){ }
};
const RESTRICTED = ['_apiKey'];
api = new Proxy(api, {
has(target, key) {
return (RESTRICTED.indexOf(key) > -1) ?
false :
Reflect.has(target, key);
}
});
// these log false, and `for in` iterators will ignore _apiKey
console.log("_apiKey" in api);
for (var key in api) {
if (api.hasOwnProperty(key) && key === "_apiKey") {
console.log("This will never be logged because the proxy obscures _apiKey...")
}
}
抽离校验模块
//如何使用 Proxy 保障数据类型的准确性
let numericDataStore = {
count: 0,
amount: 1234,
total: 14
};
numericDataStore = new Proxy(numericDataStore, {
set(target, key, value, proxy) {
if (typeof value !== 'number') {
throw Error("Properties in numericDataStore can only be numbers");
}
return Reflect.set(target, key, value, proxy);
}
});
// 抛出错误,因为 "foo" 不是数值
numericDataStore.count = "foo";
// 赋值成功
numericDataStore.count = 333;
//使用 Proxy 则可以将校验器从核心逻辑分离出来自成一体
function createValidator(target, validator) {
return new Proxy(target, {
_validator: validator,
set(target, key, value, proxy) {
if (target.hasOwnProperty(key)) {
let validator = this._validator[key];
if (!!validator(value)) {
return Reflect.set(target, key, value, proxy);
} else {
throw Error(`Cannot set ${key} to ${value}. Invalid.`);
}
} else {
throw Error(`${key} is not a valid property`)
}
}
});
}
const personValidators = {
name(val) {
return typeof val === 'string';
},
age(val) {
return typeof age === 'number' && val > 18;
}
}
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
return createValidator(this, personValidators);
}
}
const bill = new Person('Bill', 25);
// 以下操作都会报错
bill.name = 0;
bill.age = 'Bill';
bill.age = 15;
访问日志
//对于那些调用频繁、运行缓慢或占用执行环境资源较多的属性或接口,开发者会希望记录它们的使用情况或性能表现,这个时候就可以使用 Proxy 充当中间件的角色,轻而易举实现日志功能
let api = {
_apiKey: '123abc456def',
getUsers: function() { /* ... */ },
getUser: function(userId) { /* ... */ },
setUser: function(userId, config) { /* ... */ }
};
function logMethodAsync(timestamp, method) {
setTimeout(function() {
console.log(`${timestamp} - Logging ${method} request asynchronously.`);
}, 0)
}
api = new Proxy(api, {
get: function(target, key, proxy) {
var value = target[key];
return function(...arguments) {
logMethodAsync(new Date(), key);
return Reflect.apply(value, target, arguments);
};
}
});
api.getUsers();
预警和拦截
//假设你不想让其他开发者删除 noDelete 属性,还想让调用 oldMethod 的开发者了解到这个方法已经被废弃了,或者告诉开发者不要修改 doNotChange 属性,那么就可以使用 Proxy 来实现
let dataStore = {
noDelete: 1235,
oldMethod: function() {/*...*/ },
doNotChange: "tried and true"
};
const NODELETE = ['noDelete'];
const NOCHANGE = ['doNotChange'];
const DEPRECATED = ['oldMethod'];
dataStore = new Proxy(dataStore, {
set(target, key, value, proxy) {
if (NOCHANGE.includes(key)) {
throw Error(`Error! ${key} is immutable.`);
}
return Reflect.set(target, key, value, proxy);
},
deleteProperty(target, key) {
if (NODELETE.includes(key)) {
throw Error(`Error! ${key} cannot be deleted.`);
}
return Reflect.deleteProperty(target, key);
},
get(target, key, proxy) {
if (DEPRECATED.includes(key)) {
console.warn(`Warning! ${key} is deprecated.`);
}
var val = target[key];
return typeof val === 'function' ?
function(...args) {
Reflect.apply(target[key], target, args);
} :
val;
}
});
// these will throw errors or log warnings, respectively
dataStore.doNotChange = "foo";
delete dataStore.noDelete;
dataStore.oldMethod();
过滤操作
//某些操作会非常占用资源,比如传输大文件,这个时候如果文件已经在分块发送了,就不需要在对新的请求作出相应(非绝对),这个时候就可以使用 Proxy 对当请求进行特征检测,并根据特征过滤出哪些是不需要响应的,哪些是需要响应的。下面的代码简单演示了过滤特征的方式
let obj = {
getGiantFile: function(fileId) {/*...*/ }
};
obj = new Proxy(obj, {
get(target, key, proxy) {
return function(...args) {
const id = args[0];
let isEnroute = checkEnroute(id);
let isDownloading = checkStatus(id);
let cached = getCached(id);
if (isEnroute || isDownloading) {
return false;
}
if (cached) {
return cached;
}
return Reflect.apply(target[key], target, args);
}
}
});
中断代理
//Proxy 支持随时取消对 target 的代理,这一操作常用于完全封闭对数据或接口的访问。在下面的示例中,我们使用了 Proxy.revocable 方法创建了可撤销代理的代理对象:
let sensitiveData = { username: 'devbryce' };
const {sensitiveData, revokeAccess} = Proxy.revocable(sensitiveData, handler);
function handleSuspectedHack(){
revokeAccess();
}
// logs 'devbryce'
console.log(sensitiveData.username);
handleSuspectedHack();
// TypeError: Revoked
console.log(sensitiveData.username);
ES6中的let
- let 不存在变量提升
var命令会发生“变量提升”现象,即变量可以在声明之前使用,值为undefined
- 暂时性死区
只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。总之,在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”(temporal dead zone,简称 TDZ)。隐蔽的死区问题
// 不报错
var x = x;
// 报错
let x = x;
// ReferenceError: x is not defined
- 不允许重复申明
function func(arg) {
let arg;
}
func() // 报错
function func(arg) {
{
let arg;
}
}
func() // 不报错
- 块级作用域与函数声明
ES6 引入了块级作用域,明确允许在块级作用域之中声明函数,块级作用域之中,函数声明语句的行为类似于let,在块级作用域之外不可引用。ES6 的块级作用域必须有大括号,如果没有大括号,JavaScript 引擎就认为不存在块级作用域。
function f() { console.log('I am outside!'); }
(function () {
if (false) {
// 重复声明一次函数f
function f() { console.log('I am inside!'); }
}
f();
}());
1.允许在块级作用域内声明函数。
2.函数声明类似于var,即会提升到全局作用域或函数作用域的头部。
3.同时,函数声明还会提升到所在的块级作用域的头部。
let var const 区别 以及为什么?
- var 关键词
- var声明作用域
var定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问
function test() {
var message = "hello world"; // 局部变量
}
test();
console.log(message); // 报错
//函数test()调用时会创建变量message并给它赋值,调用之后变量随即被销毁。因此,在函数test()之外调用变量message会报错
//在函数内定义变量时省略var操作符,可以创建一个全局变量
function test() {
message = "hello world"; // 局部变量
}
test();
console.log(message); // hello world
//省略掉var操作符之后,message就变成了全局变量。只要调用一次函数test(),就会定义这个变量,并且可以在函数外部访问到。在局部作用域中定义的全局变量很难维护,不推荐这么做。在严格模式下,如果像这样给未声明的变量赋值,则会导致抛出ReferenceError。
- var声明提升
var在js中是支持预解析的,如下代码不会报错。这是因为使用var声明的变量会自动提升到函数作用域顶部:
function foo() {
console.log(age);
var age = 26;
}
foo(); // undefined
//javaScript引擎,在代码预编译时,javaScript引擎会自动将所有代码里面的var关键字声明的语句都会提升到当前作用域的顶端,如下代码:
function foo() {
var age;
console.log(age);
age = 26;
}
foo(); // undefined
3.全局声明
var name = 'Matt';
console.log(window.name); // 'Matt'
let age = 26;
console.log(window.age); // undefined
ES6变量和函数提升
- Hoisting(变量提升)
概念的字面意义上说,变量提升 意味着变量和函数的声明会在物理层面移动到代码的最前面,但这么说并不准确。实际上变量和函数声明在代码里的位置是不会动的,而是在编译阶段被放入内存中时变动。
- 函数和变量相比,会被优先提升。这意味着函数会被提升到更靠前的位置。
// Example 1 - 变量 y 被提升了,但是它的初始化没有
var x = 1; // 声明 + 初始化 x
console.log(x + " " + y); // 输出:'1 undefined'
var y = 2; // 声明 + 初始化 y
// Example 2 - 先赋值后声明也能连名带值被提升
var num1 = 3; // Declare and initialize num1
num2 = 4; // Initialize num2
console.log(num1 + " " + num2); // 输出:'3 4'
var num2; // Declare num2 for hoisting
// Example 3 - 同理
a = 'Cran'; // Initialize a
b = 'berry'; // Initialize b
console.log(a + " " + b); // 输出:'Cranberry'
var a, b; // Declare both a & b for hoisting
事件模型
JS的事件模型主要分为三种DOM0级事件模型(原始事件模型)、DOM2事件模型、IE事件模型
- DOM0级事件模型
这种事件模型就是直接在dom对象上注册事件名称,在对应标签上注册了一个onclick事件,在这个事件函数内部输出点击的目标,而解除事件则将null复制给事件函数。但对于原始事件模型,一个dom对象只能注册一个同类型的函数,注册多个同类型的函数就会发生覆盖,之前注册的函数就会无效。无法通过事件的冒泡、委托等机制完成更多事情。
var click = document.getElementById('click');
click.onclick = function(){
alert('you click the first function');
};
click.onclick = function(){
alert('you click the second function')
}
- DOM2事件模型(addEventListener removeEventListene)
DOM2事件模型也被称作标准模型一次事件的发生包含三个过程:事件捕获阶段、事件目标阶段、事件冒泡阶段。事件捕获阶段:当某个元素触发某个事件,顶层对象document就会发出一个事件流,随着DOM树的节点向目标元素节点流去,直到到达事件真正发生的目标元素。事件目标阶段:当到达目标元素之后,执行目标元素该事件相应的处理函数。如果没有绑定监听函数,那就不执行。事件冒泡阶段:目标元素开始,往顶层元素传播。第三个参数true表示捕获、false表示冒泡,默认为false,为true时捕获阶段依次检查经过的节点是否绑定了事件监听函数,如果有则执行。为false时冒泡依次检查经过的节点是否绑定了事件监听函数,如果有则执行。
- IE事件模型
事件处理阶段:事件到达目标元素, 触发目标元素的监听函数。事件冒泡阶段:事件从目标元素冒泡到document, 依次检查经过的节点是否绑定了事件监听函数,如果有则执行。
//为了兼容IE
var demo = document.getElementById('demo');
if(demo.attachEvent){
demo.attachEvent('onclick',fun);
}else{
demo.addEventListener('click',fun,false);
}
//如果在开发过程中不需要出发捕获或者冒泡机制的话可以组织捕获或者冒泡
//(1) 阻止默认事件
function(e){
if(e && e.preventDefault){
e.preventDefault();
}else{ //IE
window.event.returnValue = false;
}
}
//(2) 阻止冒泡事件
function(e){
if(e && e.stopPropagation){
e.stopPropagation();
}else{ //IE
window.event.cancleBubble = true;
}
}
on和addEventListener的区别
- 使用on会发生后一次绑定将前一次的绑定给覆盖掉了
window.onload = function(){
var box = document.getElementById("box");
box.onclick = function(){
console.log("我是box1");
}
box.onclick = function(){
box.style.fontSize = "18px";
console.log("我是box2");
}
}
- addEventListener可以多次绑定同一个事件并且不会覆盖上一个事件
window.onload = function(){
var box = document.getElementById("box");
box.addEventListener("click",function(){
console.log("我是box1");
})
box.addEventListener("click",function(){
console.log("我是box2");
})
}
//运行结果:我是box1 我是box2
第三个参数是指在冒泡阶段还是捕获阶段处理事件处理程序,如果为true代表捕获阶段处理,如果是false代表冒泡阶段处理,第三个参数可以省略,大多数情况也不需要用到第三个参数,不写第三个参数默认false(即冒泡)
- 冒泡与捕获阶段
box.addEventListener("click",function(){
console.log("box");
})
child.addEventListener("click",function(){
console.log("child");
})
//执行的结果:child box
box.addEventListener("click",function(){
console.log("box");
},true)
child.addEventListener("click",function(){
console.log("child");
})
//执行的结果:box child
一个ul里面有很多li,点击li会弹出li的内容,怎么给li绑定事件
若直接在html中使用js拼接元素时,通过以上事件绑定方法能够实现点击事件,但在Ajax中拼接时不行。Ajax为异步方法,未执行完拼接就执行绑定,此时元素未找到,故事件绑定失败。
解决:使用以下方法绑定,可以实现事件绑定。
$(".class").find("li").unbind("click").live("click",function(){
alert("success");
});
原理:通过 live() 方法附加的事件处理程序适用于匹配选择器的当前及未来的元素(比如由脚本创建的新元素,或在绑定时元素未添加上)。
跨域以及处理方法
- 同源策略
是指同协议,同域名,同端口号,只要有一个不同,就会产生跨域问题
- CORS跨域资源共享(主流解决方案)
CORS (Cross-Origin Resource Sharing,跨域资源共享)由一系列 HTTP 响应头组成,这些 HTTP 响应头决定浏览器是否阻止前端 JS 代码跨域获取资源。浏览器的同源安全策略默认会阻止网页“跨域”获取资源。但如果接口服务器配置了 CORS 相关的 HTTP 响应头,就可以解除浏览器端的跨域访问限制。
使用步骤分为如下 3 步:
1.运行 npm install cors 安装中间件
2.使用 const cors = require(‘cors’) 导入中间件
3.在路由之前调用 app.use(cors()) 配置中间件
// 导入express模块
const express = require('express')
// 创建express的服务器实例
const app = express()
//配置解析表单数据的中间件
app.use(express.urlencoded({extended: false}))
// 一定要在路由之前,配置cors这个中间件,从而解决接口跨域问题
const cors = require('cors')
app.use(cors())
//导入路由模块
const router = require('./16.apiRouter')
//把路由模块,注册到app上
app.use('/api', router)
// 调用app.listen方法,指定端口号并启动web服务器
app.listen(80, () => {
console.log('http://127.0.0.1')
})
注意事项:CORS 主要在服务器端进行配置。客户端浏览器无须做任何额外的配置,即可请求开启了 CORS 的接口。CORS 在浏览器中有兼容性。只有支持 XMLHttpRequest Level2 的浏览器,才能正常访问开启了 CORS 的服务端接口(例如:IE10+、Chrome4+、FireFox3.5+)。
CORS 响应头部 - Access-Control-Allow-Origin
//origin 参数的值指定了允许访问该资源的外域 URL。
Access-Control-Allow-Origin: | *
//只允许来自 http://duanxiaoxiao.cn 的请求:
res.setHeader('Access-Control-Allow-Origin','http://duanxiaoxiao.cn')
//字段的值为通配符 *,表示允许来自任何域的请求
res.setHeader('Access-Control-Allow-Origin','*')
CORS 响应头部 - Access-Control-Allow-Headers
//如果客户端向服务器发送了额外的请求头信息,则需要在服务器端,通过 Access-Control-Allow-Headers 对额外的请求头进行声明,否则这次请求会失败!
// 注意:多个请求头之间使用英文逗号进行分割
res.setHeader('Access-Control-Allow-Headers','Content-Type,X-Custom-Header');
CORS 响应头部 - Access-Control-Allow-Methods
// 只允许 POST、GET、DELETE、HEAD 请求方法
res.setHeader('Access-Control-Alow-Methods','POST,GET,DELETE,HEAD');
// 允许所有的 HTTP 请求方法
res.setHeader('Access-Control-Alow-Methods','*');
- jsonp
原理:动态生成script标签,通过src属性加载。src属性是不受同源策略的影响的,可以把我们需要跨域的资源放在src上面,就可以解决跨域的问题了。
缺点:只能使用get请求,不支持post请求,应用场景及其有限。
应用场景:有些第三方数据接口可能会使用jsonp解决跨域问题,用来请求一些公共信息。如:全球有多少城市,请求中国天气网的天气信息等等
- 中间代理服务器
原理:我们上面说到跨域的产生是因为不满足同源策略,浏览器进行的一个拦截限制,而服务器之间是不会产生跨域的,所以就用到了中间代理服务器的技术,来解决跨域请求的问题。中间代理服务器又被称为转发代理服务器,顾名思义就是在A与B之间,添加一个中间代理服务器,起到一个中介的作用,来进行数据的请求和访问。搭建一个与前端同源的代理服务器,前端将请求传递给代理服务器,代理服务器再把请求发送给目标服务器,目标服务器把响应的数据传递给代理服务器,代理服务器再发送给前端。
- 反向代理
基于Vue,原理跟中间代理服务器是一样的。在根目录下创建一个vue.config.js,内容如下,Vue会自动的帮你生成一个代理服务器
module.exports = {
devServer:{
//设置代理
proxy:{
'/api':{
// 目标对象
target:'http://localhost:3000',//要跳转的位置
pathRewrite:{
'^/api':''
}
}
}
}
}
正向代理与反向代理
- 代理
代理其实就是一个中介,A和B本来可以直连,中间插入一个C,C就是中介。刚开始的时候,代理多数是帮助内网client访问外网server用的后来出现了反向代理,"反向"这个词在这儿的意思其实是指方向相反,即代理将来自外网客户端的请求转发到内网服务器,从外到内
正向代理的用途:
(1)访问原来无法访问的资源,如google
(2) 可以做缓存,加速访问资源
(3)对客户端访问授权,上网进行认证
(4)代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
- 反向代理(Reverse Proxy)
实际运行方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器
反向代理的作用:
(1)保证内网的安全,阻止web攻击,大型网站,通常将反向代理作为公网访问地址,Web服务器是内网
(2)负载均衡,通过反向代理服务器来优化网站的负载
- 总结
1.正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端.
2.反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端
1.正向代理中,proxy和client同属一个LAN,对server透明;
2.反向代理中,proxy和server同属一个LAN,对client透明。
3.实际上proxy在两种代理中做的事都是代为收发请求和响应,不过从结构上来看正好左右互换了下,所以把后出现的那种代理方式叫成了反向代理
ES6新语法
- let
- 解构赋值
对象结构
let obj = {
name: "波波",
age: 38,
gender: "男",
score: 88,
};
//定义变量名
let { name: name2, age: age2, gender: gender2, score: score2 } = obj;
console.log(name2, age2, gender2, score2);
//变量名可以与属性名一致
let { name: name, age: age, gender: gender, score: score } = obj;
console.log(name, age, gender, score);
//一致时可以省略变量名
let { name, age, gender, score } = obj;
console.log(name, age, gender, score);
//也可以一起用
let { name, age, gender, score: fenshu } = obj;
console.log(name, age, gender, fenshu);
//赋值除了某个属性的对象
let obj = {
name: "波波",
age: 38,
gender: "男",
score: 100,
};
// obj2相当于是obj对象里面除了name属性之外的属性组成的一个对象
let { name, ...obj2 } = obj;
console.log(obj2); // { age: 38, gender: '男', score: 100 }
数组解构
// 声明一个数组
let arr = [10, 20, 30, 40];
//基础写法
let [num1, num2, num3, num4] = arr;
console.log(num1, num2, num3, num4);
//其他的与对象的一致
let [num1, num2, num3, num4, num5] = arr;
console.log(num1, num2, num3, num4, num5); // num5为undefined
let [num1, num2, num3, num4, num5=5] = arr;
console.log(num1, num2, num3, num4, num5); // num5为5
结合函数声明
function test2({ name, age, gender, height = 180 }) {
console.log(name, age, gender, height);
}
test2({
name: "波波",
age: 38,
gender: "男",
});
test2({
name: "波波",
age: 38,
gender: "男",
height: 160,
});
- 箭头函数
简单来说,箭头函数就是匿名函数的一个简写。
// 1. 普通的匿名函数
let fn = function (name) {
console.log("my name is ", name);
};
fn("波波");
// 2. 箭头函数
let fn1 = (name) => console.log("my name is ", name);
fn1("波波");
简写规则
1.function改成=>,=>可以读成goes to
2.如果只有一个形参,那就可以省略形参小括号
3.如果不是一个形参(0个或多个),那就不能省略形参小括号
4.如果函数体只有一句话,那就可以省略函数体的大括号
5.如果函数体只有一句话,并且这一句话是return返回值,那return也要省略
let fn1 = function (name) {
return name + "你好吗?";
};
let fn1 = (name) => name + "你好吗?";
//对象成员简写
let name = "千里";
let age = 18;
let gender = "man";
let score = 10;
// es6
let obj = {
name,
age,
gender,
score,
//在这种写法中,如果传入一个没有赋值的变量,那么就会报错
//test,
sayHi() {
console.log("哈哈");
},
};
console.log(obj);
obj.sayHi();
- 拓展(展开)运算符
对象展开
// 声明一个对象
let chinese = {
skin: "yellow",
hair: "black",
sayHi() {
console.log("Are you eat?");
},
};
let CXK = {
slill: "jump sing rap and play basketball",
song: "啊哈哈哈",
};
let linge = {
// skin: "yellow",
// hair: "black",
// sayHi() {
// console.log("Are you eat?");
// },
// slill: "jump sing rap and play basketball",
// song: "啊哈哈哈",
// 展开语法 等同于上方写法
...chinese,
...CXK,
};
console.log(linge);
//当新增属性时,直接添加即可。如果重新定义已经存在的,那么覆盖原来的。
let linge = {
...chinese,
...CXK,
gender: "Man",
hair: "白发苍苍",
};
数组展开
//类似于对象展开
let arr1 = [10, 20, 30];
let arr2 = [40, 50, 60];
let arr3 = [...arr1, ...arr2, 70];
console.log(arr3);
- 数据类型set
作用和数组类型类似,和数组不同的是set不能存放重复的元素。
let set1 = new Set([10, 20, 30, 40, 10, 20, 30, 40, 50]);
console.log(set1);
//结果是{10,20,30,40,50}
//数组去重
let arr = [10, 20, 30, 10, 20, 30, 20, 10, 33, 200];
let arrNew = [...new Set(arr)];
console.log(arrNew);
- 模板字符串
模板字符串会保留原样字符串格式,以及可以占位。其语法为反引号
let author = "波波";
let str1 = `
静夜思
${author}
哈哈哈
`;
console.log(str1);
//输出的格式也是这样带有回车的这种
- 补充数组的方法
forEach(无返回值)
let arr = [10, 20, 30, 40];
arr.forEach(function (item, index) {
// item 遍历出的每一项
// index 遍历出来的每一项对应的索引
console.log(item, index);
});
map(有返回值)
let arr = [10, 20, 30, 40];
let arrNew = arr.map(function (item, index) {
// item 遍历出的每一项
// index 遍历出来的每一项对应的索引
// console.log(item, index);
return item * item;
});
console.log(arrNew);
filter
let arr = [10, 20, 11, 21, 30, 31, 23, 43];
let arrNew = arr.filter((item, index) => {
console.log(item, index);
// 如果条件成立,返回当前项
return item % 2 == 0;
});
console.log(arrNew); //[ 10, 20, 30 ]
其他应用
//数组降维
// 将二维数组将为一维数组
var arr = [[10, 20], [30, 40, 50], [60, 79, 80]]
var arrNew = []
arr.forEach(v => {
arrNew.push(...v)
})
console.log(arrNew); // [10, 20, 30, 40, 50, 60, 79, 80]
//数组升维
var arr = [
{ type: "电子产品", name: "iPhone", price: 8888 },
{ type: "家具", name: "桌子", price: 100 },
{ type: "食品", name: "瓜子", price: 10 },
{ type: "家具", name: "椅子", price: 380 },
{ type: "电子产品", name: "小米手机", price: 1380 },
{ type: "食品", name: "辣条", price: 5 },
{ type: "食品", name: "咖啡", price: 50 },
];
//1.
var obj = {}; //将测type有没有重复的
var arrNew = []; // 升级后的二维数组
// 1. 将type去重,找出所有的产品类型
// 遍历这个arr一维数组
arr.forEach((v) => {
if (obj[v.type] == undefined) {
obj[v.type] = 1;
// 把这个数组放到arrNew中
arrNew.push({
type: v.type,
data: [v],
});
} else {
// 判断当前v输入arrNew中的哪一类
arrNew.forEach((v2, j) => {
if (v.type == v2.type) {
arrNew[j].data.push(v);
}
});
}
});
console.log(arrNew);
//2.
var obj = {}; //将测type有没有重复的
var arrNew = []; // 升级后的二维数组
var index = 0; // 用于记录索引
arr.forEach((v) => {
if (obj[v.type] == undefined) {
obj[v.type] = index++;
// 把这个数组放到arrNew中
arrNew.push({
type: v.type,
data: [v],
});
} else {
var _index = obj[v.type];
arrNew[_index].data.push(v);
}
});
console.log(arrNew);
//数组去重(排序法)
var arr = [10, 20, 30, 23, 4, 512, 20, 10];
var arrNew = [];
arr.sort((a, b) => {
return a - b;
});
console.log(arr); // [4, 10, 10, 20, 20, 23, 30, 512];
arr.forEach((v, i) => {
if (v != arr[i + 1]) {
arrNew.push(v);
}
});
console.log(arrNew); // [ 4, 10, 20, 23, 30, 512 ]
//数组去重(对象法即对象属性不能同名)
// 使用对象法
var obj = {};
var arrNew = [];
// 遍历要去重的数组
arrNew.forEach((v) => {
if (obj[v] == undefined) {
arrNew.push(v); // 不存在九江这个v存起来
obj[v] = 1; // 随意写,作为属性的值(避免undefined)
}
});
js垃圾回收机制
- 垃圾回收方式
通常有两种方式
1.标记清除(mark and sweep)
这是JavaScript中最常用的垃圾回收方式。
(1)当变量进入执行环境时(函数中声明变量),就标记这个变量为“进入环境”,当变量离开环境时(函数执行结束),则将其标记为“离开环境”,离开环境之后还有的变量则是需要被删除的变量。
(2)垃圾回收器在运行的时候会给存储在内存中的所有变量都加上标记。
(3)去掉环境中的变量以及被环境中变量引用的变量的标记。
(4)之后再被加上标记的变量即是需要回收的变量(因为环境中的变量已经无法访问到这些变量)
(5)最后,垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
2.引用计数(reference counting)
这种方式常常会引起内存泄漏,低版本的IE使用这种方式。机制就是跟踪一个值的引用次数,当声明一个变量并将一个引用类型赋值给该变量时该值引用次数加1,当这个变量指向其他一个时该值的引用次数便减一。当该值引用次数为0时,则说明没有办法再访问这个值了,被视为准备回收的对象,每当过一段时间开始垃圾回收的时候,就把被引用数为0的变量回收。引用计数方法可能导致循环引用,类似死锁,导致内存泄露。
//objA和objB相互引用,两个对象的引用次数都是2。函数执行完成之后,objA和objB还将会继续存在,因为他们的引用次数永远不会是0。这样的相互引用如果说很大量的存在就会导致大量的内存泄露。
function problem() {
var objA = new Object();
var objB = new Object();
objA.someOtherObject = objB;
objB.anotherObject = objA;
}
- 常见内存泄漏的原因
(1)全局变量引起的内存泄露
(2)闭包引起的内存泄露:慎用闭包
(3)dom清空或删除时,事件未清除导致的内存泄漏
(4)循环引用带来的内存泄露