十四、流式编程(1)
本章概要
- 流支持
- 流创建
- 随机数流
- int 类型的范围
- generate()
- iterate()
- 流的建造者模式
- Arrays
- 正则表达式
集合优化了对象的存储,而流(Streams)则是关于一组组对象的处理。
流(Streams)是与任何特定存储机制无关的元素序列——实际上,我们说流是 "没有存储 "的。
取代了在集合中迭代元素的做法,使用流即可从管道中提取元素并对其操作。这些管道通常被串联在一起形成一整套的管线,来对流进行操作。
在大多数情况下,将对象存储在集合中就是为了处理它们,因此你会发现你把编程的主要焦点从集合转移到了流上。
流的一个核心好处是,它使得程序更加短小并且更易理解。当 Lambda 表达式和方法引用(method references)和流一起使用的时候会让人感觉自成一体。流使得 Java 8 更具吸引力。
举个例子,假如你要随机展示 5 至 20 之间不重复的整数并进行排序。你要对它们进行排序的事实,会使你首先关注选用哪个有序集合,然后围绕这个集合进行后续的操作。但是使用流式编程,你就可以简单陈述你要做什么:
public class Randoms {
public static void main(String[] args) {
new Random(47)
.ints(5, 20)
.distinct()
.limit(7)
.sorted()
.forEach(System.out::println);
}
}
输出结果:
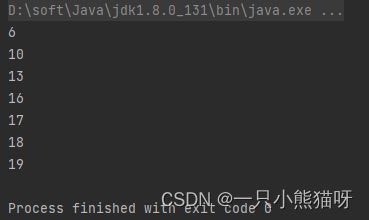
首先,我们给 Random 对象一个种子值47(以便程序再次运行时产生相同的输出)。ints() 方法产生一个流并且 ints() 方法有多种方式的重载 —— 两个参数限定了产生的数值的边界。这将生成一个随机整数流。我们用 流的中间操作(intermediate stream operation) distinct() 使流中的整数不重复,然后使用 limit() 方法获取前 7 个元素。接下来使用 sorted() 方法排序。最终使用 forEach() 方法遍历输出,它根据传递给它的函数对流中的每个对象执行操作。在这里,我们传递了一个可以在控制台显示每个元素的方法引用:System.out::println 。
注意 Randoms.java 中没有声明任何变量。流可以在不曾使用赋值或可变数据的情况下,对有状态的系统建模,这非常有用。
声明式编程(Declarative programming)是一种编程风格——它声明了要做什么,而不是指明(每一步)如何做。而这正是我们在函数式编程中所看到的(编程风格)。你会注意到,命令式(Imperative)编程的形式(指明每一步如何做)会更难理解:
import java.util.*;
public class ImperativeRandoms {
public static void main(String[] args) {
Random rand = new Random(47);
SortedSet<Integer> rints = new TreeSet<>();
while (rints.size() < 7) {
int r = rand.nextInt(20);
if (r < 5) {
continue;
}
rints.add(r);
}
System.out.println(rints);
}
}
输出结果:
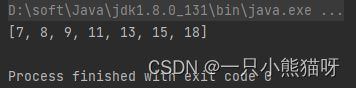
在 Randoms.java 中,我们无需定义任何变量,但在这里我们定义了 3 个变量: rand,rints 和 r。由于 nextInt() 方法没有下限的原因(其内置的下限永远为 0),这段代码实现起来更复杂。所以我们要生成额外的值来过滤小于 5 的结果。
注意,你必须研究代码才能搞清楚ImperativeRandoms.java程序在做什么。而在 Randoms.java 中,代码会直接告诉你它在做什么。这种语义的清晰性是使用Java 8 流式编程的重要原因之一。
像在 ImperativeRandoms.java 中那样显式地编写迭代过程的方式称为_外部迭代(external iteration)。而在 Randoms.java 中,你看不到任何上述的迭代过程,所以它被称为_内部迭代(internal iteration),这是流式编程的一个核心特征。内部迭代产生的代码可读性更强,而且能更简单的使用多核处理器。通过放弃对迭代过程的控制,可以把控制权交给并行化机制。
另一个重要方面,流是懒加载的。这代表着它只在绝对必要时才计算。你可以将流看作“延迟列表”。由于计算延迟,流使我们能够表示非常大(甚至无限)的序列,而不需要考虑内存问题。
流支持
Java 设计者面临着这样一个难题:现存的大量类库不仅为 Java 所用,同时也被应用在整个 Java 生态圈数百万行的代码中。如何将一个全新的流的概念融入到现有类库中呢?
比如在 Random 中添加更多的方法。只要不改变原有的方法,现有代码就不会受到干扰。
一个大的挑战来自于使用接口的库。集合类是其中关键的一部分,因为你想把集合转为流。但是如果你将一个新方法添加到接口,那就破坏了每一个实现接口的类,因为这些类都没有实现你添加的新方法。
Java 8 采用的解决方案是:在接口中添加被 default(默认)修饰的方法。通过这种方案,设计者们可以将流式(stream)方法平滑地嵌入到现有类中。流方法预置的操作几乎已满足了我们平常所有的需求。流操作的类型有三种:创建流,修改流元素(中间操作, Intermediate Operations),消费流元素(终端操作, Terminal Operations)。最后一种类型通常意味着收集流元素(通常是汇入一个集合)。
下面我们来看下每种类型的流操作。
流创建
你可以通过 Stream.of() 很容易地将一组元素转化成为流(Bubble 类在本章的后面定义):
StreamOf.java
import java.util.stream.*;
public class StreamOf {
public static void main(String[] args) {
Stream.of(new Bubble(1), new Bubble(2), new Bubble(3))
.forEach(System.out::println);
Stream.of("It's ", "a ", "wonderful ", "day ", "for ", "pie!")
.forEach(System.out::print);
System.out.println();
Stream.of(3.14159, 2.718, 1.618)
.forEach(System.out::println);
}
}
Bubble.java
public class Bubble {
public final int i;
public Bubble(int n) {
i = n;
}
@Override
public String toString() {
return "Bubble(" + i + ")";
}
private static int count = 0;
public static Bubble bubbler() {
return new Bubble(count++);
}
}
输出结果:
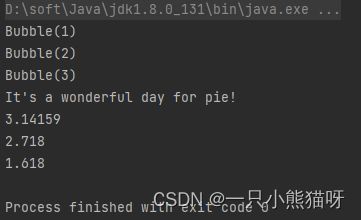
除此之外,每个集合都可以通过调用 stream() 方法来产生一个流。代码示例:
import java.util.*;
public class CollectionToStream {
public static void main(String[] args) {
List<Bubble> bubbles = Arrays.asList(new Bubble(1), new Bubble(2), new Bubble(3));
System.out.println(bubbles.stream()
.mapToInt(b -> b.i)
.sum());
Set<String> w = new HashSet<>(Arrays.asList("It's a wonderful day for pie!".split(" ")));
w.stream()
.map(x -> x + " ")
.forEach(System.out::print);
System.out.println();
Map<String, Double> m = new HashMap<>();
m.put("pi", 3.14159);
m.put("e", 2.718);
m.put("phi", 1.618);
m.entrySet().stream()
.map(e -> e.getKey() + ": " + e.getValue())
.forEach(System.out::println);
}
}
输出结果:
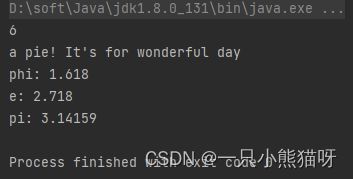
在创建 List 对象之后,我们只需要简单地调用所有集合中都有的 stream()。中间操作 map() 会获取流中的所有元素,并且对流中元素应用操作从而产生新的元素,并将其传递到后续的流中。通常 map() 会获取对象并产生新的对象,但在这里产生了特殊的用于数值类型的流。例如,mapToInt() 方法将一个对象流(object stream)转换成为包含整型数字的 IntStream。同样,针对 Float 和 Double 也有类似名字的操作。
我们通过调用字符串的 split()(该方法会根据参数来拆分字符串)来获取元素用于定义变量 w。稍后你会知道 split() 参数可以是十分复杂,但在这里我们只是根据空格来分割字符串。
为了从 Map 集合中产生流数据,我们首先调用 entrySet() 产生一个对象流,每个对象都包含一个 key 键以及与其相关联的 value 值。然后分别调用 getKey() 和 getValue() 获取值。
随机数流
Random 类被一组生成流的方法增强了。代码示例:
import java.util.*;
import java.util.stream.*;
public class RandomGenerators {
public static <T> void show(Stream<T> stream) {
stream.limit(4).forEach(System.out::println);
System.out.println("++++++++");
}
public static void main(String[] args) {
Random rand = new Random(47);
show(rand.ints().boxed());
show(rand.longs().boxed());
show(rand.doubles().boxed());
// 控制上限和下限:
show(rand.ints(10, 20).boxed());
show(rand.longs(50, 100).boxed());
show(rand.doubles(20, 30).boxed());
// 控制流大小:
show(rand.ints(2).boxed());
show(rand.longs(2).boxed());
show(rand.doubles(2).boxed());
// 控制流的大小和界限
show(rand.ints(3, 3, 9).boxed());
show(rand.longs(3, 12, 22).boxed());
show(rand.doubles(3, 11.5, 12.3).boxed());
}
}
输出结果:
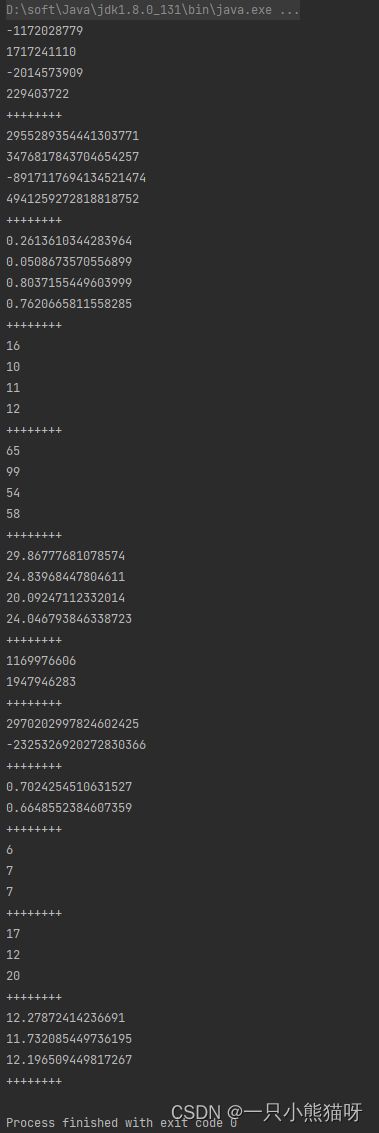
为了消除冗余代码,我创建了一个泛型方法 show(Stream (在讲解泛型之前就使用这个特性,确实有点作弊,但是回报是值得的)。类型参数 T 可以是任何类型,所以这个方法对 Integer、Long 和 Double 类型都生效。但是 Random 类只能生成基本类型 int, long, double 的流。幸运的是, boxed() 流操作将会自动地把基本类型包装成为对应的装箱类型,从而使得 show() 能够接受流。
我们可以使用 Random 为任意对象集合创建 Supplier。从文本文件提供字符串对象的例子如下。
Cheese.dat 文件内容:
// streams/Cheese.dat
Not much of a cheese shop really, is it?
Finest in the district, sir.
And what leads you to that conclusion?
Well, it's so clean.
It's certainly uncontaminated by cheese.
我们通过 File 类将 Cheese.dat 文件的所有行读取到 List 中。代码示例:
import java.util.*;
import java.util.stream.*;
import java.util.function.*;
import java.io.*;
import java.nio.file.*;
public class RandomWords implements Supplier<String> {
List<String> words = new ArrayList<>();
Random rand = new Random(47);
RandomWords(String fname) throws IOException {
List<String> lines = Files.readAllLines(Paths.get(fname));
// 略过第一行
for (String line : lines.subList(1, lines.size())) {
for (String word : line.split("[ .?,]+"))
words.add(word.toLowerCase());
}
}
@Override
public String get() {
return words.get(rand.nextInt(words.size()));
}
@Override
public String toString() {
return words.stream()
.collect(Collectors.joining(" "));
}
public static void main(String[] args) throws Exception {
System.out.println(
Stream.generate(new RandomWords("Cheese.dat"))
.limit(10)
.collect(Collectors.joining(" ")));
}
}
输出结果:
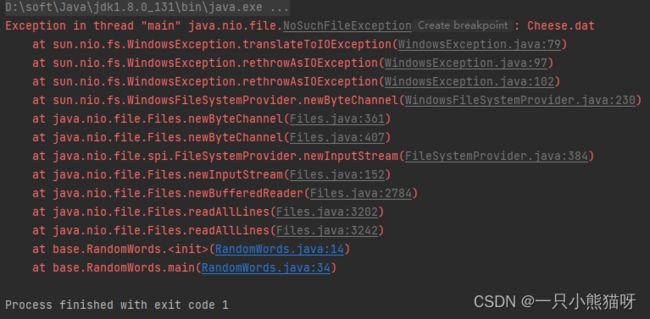
报错了,文件地址使用绝对路径:
public static void main(String[] args) throws Exception {
System.out.println(
Stream.generate(new RandomWords("D:\\onJava\\myTest\\base\\Cheese.dat"))
.limit(10)
.collect(Collectors.joining(" ")));
}
输出结果:
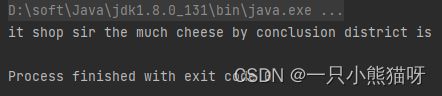
在这里可以看到 split() 更复杂的运用。在构造器里,每一行都被 split() 通过方括号内的空格或其它标点符号分割。在方括号后面的 + 表示 + 前面的东西可以出现一次或者多次(正则表达式)。
你会发现构造函数使用命令式编程(外部迭代)进行循环。在以后的例子中,你会看到我们是如何去除命令式编程。这种旧的形式虽不是特别糟糕,但使用流会让人感觉更好。
在toString() 和main()方法中你看到了 collect() 操作,它根据参数来结合所有的流元素。当你用 Collectors.joining()作为 collect() 的参数时,将得到一个String 类型的结果,该结果是流中的所有元素被joining()的参数隔开。还有很多不同的 Collectors 用于产生不同的结果。
在主方法中,我们提前看到了 Stream.generate() 的用法,它可以把任意 Supplier 用于生成 T 类型的流。
int 类型的范围
IntStream 类提供了 range() 方法用于生成整型序列的流。编写循环时,这个方法会更加便利:
import static java.util.stream.IntStream.*;
public class Ranges {
public static void main(String[] args) {
// 传统方法:
int result = 0;
for (int i = 10; i < 20; i++) {
result += i;
}
System.out.println(result);
// for-in 循环:
result = 0;
for (int i : range(10, 20).toArray()) {
result += i;
}
System.out.println(result);
// 使用流:
System.out.println(range(10, 20).sum());
}
}
输出结果:
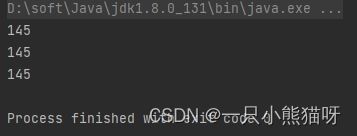
在主方法中的第一种方式是我们传统编写 for 循环的方式;第二种方式,我们使用 range() 创建了流并将其转化为数组,然后在 for-in 代码块中使用。但是,如果你能像第三种方法那样全程使用流是更好的。我们对范围中的数字进行求和。在流中可以很方便的使用 sum() 操作求和。
注意 IntStream.range() 相比 onjava.Range.range() 受更多限制。这是由于其可选的第三个参数,后者允许步长大于 1,并且可以从大到小来生成。
实用小功能 repeat() 可以用来替换简单的 for 循环。代码示例:
import static java.util.stream.IntStream.*;
public class Repeat {
public static void repeat(int n, Runnable action) {
range(0, n).forEach(i -> action.run());
}
}
其产生的循环更加清晰:
import static base.Repeat.repeat;
public class Looping {
static void hi() {
System.out.println("Hi!");
}
public static void main(String[] args) {
repeat(3, () -> System.out.println("Looping!"));
repeat(2, Looping::hi);
}
}
输出结果:
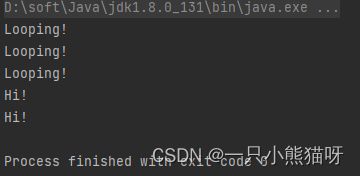
原则上,在代码中包含和解释 repeat() 并不值得。诚然它是一个相当透明的工具,但这取决于你的团队和公司的运作方式。
generate()
参照 RandomWords.java 中 Stream.generate() 搭配 Supplier 使用的例子。代码示例:
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
public class Generator implements Supplier<String> {
Random rand = new Random(47);
char[] letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
@Override
public String get() {
return "" + letters[rand.nextInt(letters.length)];
}
public static void main(String[] args) {
String word = Stream.generate(new Generator())
.limit(30)
.collect(Collectors.joining());
System.out.println(word);
}
}
输出结果:
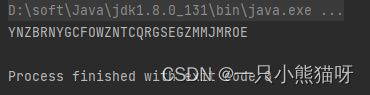
使用 Random.nextInt() 方法来挑选字母表中的大写字母。Random.nextInt() 的参数代表可以接受的最大的随机数范围,所以使用数组边界是经过慎重考虑的。
如果要创建包含相同对象的流,只需要传递一个生成那些对象的 lambda 到 generate() 中:
import java.util.stream.*;
public class Duplicator {
public static void main(String[] args) {
Stream.generate(() -> "duplicate")
.limit(3)
.forEach(System.out::println);
}
}
输出结果:
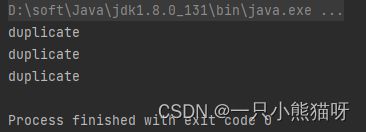
如下是在本章之前例子中使用过的 Bubble 类。注意它包含了自己的静态生成器(Static generator)方法。
public class Bubble {
public final int i;
public Bubble(int n) {
i = n;
}
@Override
public String toString() {
return "Bubble(" + i + ")";
}
private static int count = 0;
public static Bubble bubbler() {
return new Bubble(count++);
}
}
由于 bubbler() 与 Supplier 是接口兼容的,我们可以将其方法引用直接传递给 Stream.generate():
import java.util.stream.*;
public class Bubbles {
public static void main(String[] args) {
Stream.generate(Bubble::bubbler)
.limit(5)
.forEach(System.out::println);
}
}
输出结果:
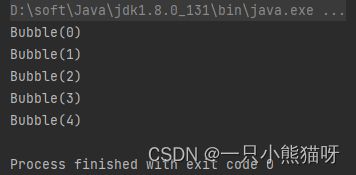
这是创建单独工厂类(Separate Factory class)的另一种方式。在很多方面它更加整洁,但是这是一个关于代码组织和品味的问题——你总是可以创建一个完全不同的工厂类。
iterate()
Stream.iterate() 产生的流的第一个元素是种子(iterate方法的第一个参数),然后将种子传递给方法(iterate方法的第二个参数)。方法运行的结果被添加到流(作为流的下一个元素),并被存储起来,作为下次调用 iterate()方法时的第一个参数,以此类推。我们可以利用 iterate() 生成一个斐波那契数列(上一章已经遇到过Fibonacci)。代码示例:
import java.util.stream.*;
public class Fibonacci {
int x = 1;
Stream<Integer> numbers() {
return Stream.iterate(0, i -> {
int result = x + i;
x = i;
return result;
});
}
public static void main(String[] args) {
new Fibonacci().numbers()
.skip(20) // 过滤前 20 个
.limit(10) // 然后取 10 个
.forEach(System.out::println);
}
}
输出结果:
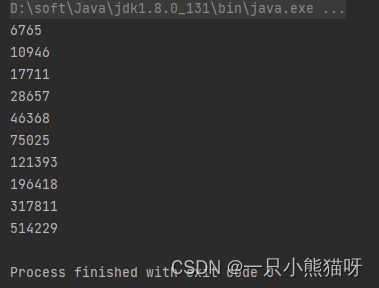
斐波那契数列将数列中最后两个元素进行求和以产生下一个元素。iterate() 只能记忆结果,因此我们需要利用一个变量 x 追踪另外一个元素。
在主方法中,我们使用了一个之前没有见过的 skip() 操作。它根据参数丢弃指定数量的流元素。在这里,我们丢弃了前 20 个元素。
流的建造者模式
在_建造者模式_(Builder design pattern)中,首先创建一个 builder 对象,然后将创建流所需的多个信息传递给它,最后builder 对象执行”创建“流的操作。Stream 库提供了这样的 Builder。在这里,我们重新审视文件读取并将其转换成为单词流的过程。代码示例:
import java.nio.file.*;
import java.util.stream.*;
public class FileToWordsBuilder {
Stream.Builder<String> builder = Stream.builder();
public FileToWordsBuilder(String filePath) throws Exception {
Files.lines(Paths.get(filePath))
.skip(1) // 略过开头的注释行
.forEach(line -> {
for (String w : line.split("[ .?,]+")) {
builder.add(w);
}
});
}
Stream<String> stream() {
return builder.build();
}
public static void main(String[] args) throws Exception {
new FileToWordsBuilder("Cheese.dat")
.stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
}
}
输出结果:
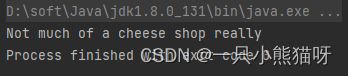
注意,构造器会添加文件中的所有单词(除了第一行,它是包含文件路径信息的注释),但是其并没有调用 build()。只要你不调用 stream() 方法,就可以继续向 builder 对象中添加单词。
在该类的更完整形式中,你可以添加一个标志位用于查看 build() 是否被调用,并且可能的话增加一个可以添加更多单词的方法。在 Stream.Builder 调用 build() 方法后继续尝试添加单词会产生一个异常。
Arrays
Arrays 类中含有一个名为 stream() 的静态方法用于把数组转换成为流。我们可以重写 interfaces/Machine.java 中的主方法用于创建一个流,并将 execute() 应用于每一个元素。代码示例:
MetalWork2.java
import java.util.Arrays;
public class MetalWork2 {
public static void main(String[] args) {
Arrays.stream(new Operation[]{
() -> Operation.show("Heat"),
() -> Operation.show("Hammer"),
() -> Operation.show("Twist"),
() -> Operation.show("Anneal")
}).forEach(Operation::execute);
}
}
Operation.java
public interface Operation {
void execute();
static void runOps(Operation... ops) {
for (Operation op : ops) {
op.execute();
}
}
static void show(String msg) {
System.out.println(msg);
}
}
输出结果:
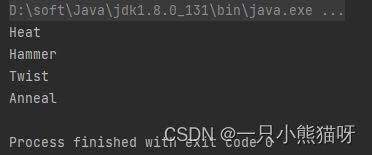
new Operation[] 表达式动态创建了 Operation 对象的数组。
stream() 同样可以产生 IntStream,LongStream 和 DoubleStream。
import java.util.*;
public class ArrayStreams {
public static void main(String[] args) {
Arrays.stream(new double[]{3.14159, 2.718, 1.618})
.forEach(n -> System.out.format("%f ", n));
System.out.println();
Arrays.stream(new int[]{1, 3, 5})
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Arrays.stream(new long[]{11, 22, 44, 66})
.forEach(n -> System.out.format("%d ", n));
System.out.println();
// 选择一个子域:
Arrays.stream(new int[]{1, 3, 5, 7, 15, 28, 37}, 3, 6)
.forEach(n -> System.out.format("%d ", n));
}
}
输出结果:
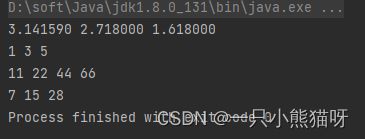
最后一次 stream() 的调用有两个额外的参数。第一个参数告诉 stream() 从数组的哪个位置开始选择元素,第二个参数用于告知在哪里停止。每种不同类型的 stream() 都有类似的操作。
正则表达式
Java 8 在 java.util.regex.Pattern 中增加了一个新的方法 splitAsStream()。这个方法可以根据传入的公式将字符序列转化为流。但是有一个限制,输入只能是 CharSequence,因此不能将流作为 splitAsStream() 的参数。
我们再一次查看将文件转换为单词的过程。这一次,我们使用流将文件转换为一个字符串,接着使用正则表达式将字符串转化为单词流。
import java.nio.file.*;
import java.util.stream.*;
import java.util.regex.Pattern;
public class FileToWordsRegexp {
private String all;
public FileToWordsRegexp(String filePath) throws Exception {
all = Files.lines(Paths.get(filePath))
.skip(1) // First (comment) line
.collect(Collectors.joining(" "));
}
public Stream<String> stream() {
return Pattern.compile("[ .,?]+").splitAsStream(all);
}
public static void
main(String[] args) throws Exception {
FileToWordsRegexp fw = new FileToWordsRegexp("D:\\onJava\\myTest\\base\\Cheese.dat");
fw.stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
fw.stream()
.skip(7)
.limit(2)
.map(w -> w + " ")
.forEach(System.out::print);
}
}
输出结果:
在构造器中我们读取了文件中的所有内容(跳过第一行注释,并将其转化成为单行字符串)。现在,当你调用 stream() 的时候,可以像往常一样获取一个流,但这回你可以多次调用 stream() ,每次从已存储的字符串中创建一个新的流。这里有个限制,整个文件必须存储在内存中;在大多数情况下这并不是什么问题,但是这丢掉了流操作非常重要的优势:
- “不需要把流存储起来。”当然,流确实需要一些内部存储,但存储的只是序列的一小部分,和存储整个序列不同。
- 它们是懒加载计算的。
幸运的是,我们稍后就会知道如何解决这个问题。