Python爬虫简单入门——urllib库
Py-urllib库爬页面简单流程
-
- 一、网页编码解码
- 二、urllib标准库
- 三、数据筛选
一、网页编码解码
解码原理,将二进制编码转换为正常文本
str = "hello"
str1 = str.encode("gbk") #国标编码
str2 = str1.decode("gbk") #用decode解码
print(str2)
二、urllib标准库
官方文档:https://docs.python.org/zh-cn/3/library/urllib.html#module-urllib
urllib.request 模块定义了适用于在各种复杂情况下打开 URL(主要为 HTTP)的函数和类 — 例如基本认证、摘要认证、重定向、cookies 及其它。
urllib.request.urlopen函数总会返回一个对象,该对象可作为 context manager 使用。 对外提供面向文件 API 以使用下层资源的对象(带有 read() 或 write() 这样的方法)。
*以baidu为例
import urllib.request #导入urllib
response = urllib.request.urlopen("http://www.baidu.com/").read().decode()
print(response)
#或者写为
# response = urllib.request.urlopen("http://www.baidu.com/")
# print(response.read().decode('utf-8'))
三、数据筛选
数据筛选清洗常用用正则表达式
例如,我们需要标题文本:
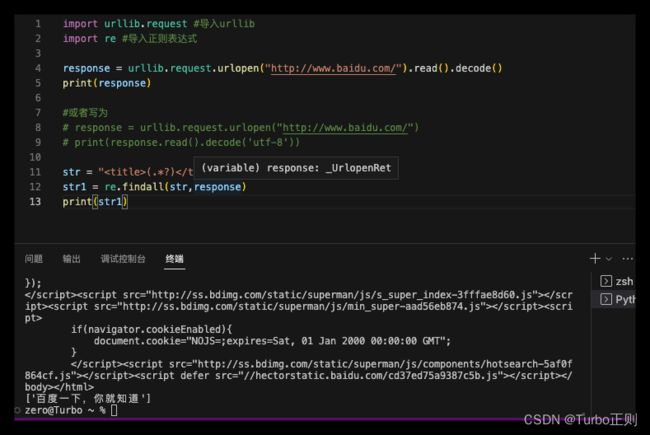
import urllib.request #导入urllib
import re #导入正则表达式
response = urllib.request.urlopen("http://www.baidu.com/").read().decode()
print(response)
#筛选标题文本
str = "(.*?) "
str1 = re.findall(str,response)
print(str1)
运行后,返回一个列表