R语言CalibrationCurves包绘制带可信区间的校准曲线
校准曲线图表示的是预测值和实际值的差距,作为预测模型的重要部分,目前很多函数能绘制校准曲线。 一般分为两种,一种是通过Hosmer-Lemeshow检验,把P值分为10等分,求出每等分的预测值和实际值的差距。一种是绘制连续的校准曲线。
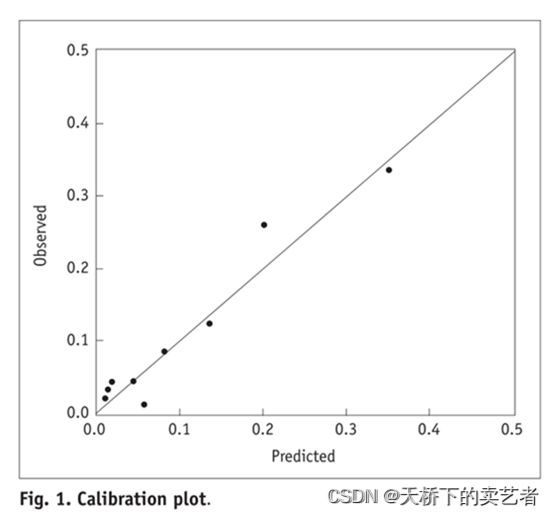

我们既往已经通过多篇文章介绍了校准曲线绘制,连续的和等分的都有介绍,今天咱们来介绍一下CalibrationCurves包,看名字就知道它是个绘制校准曲线的R包,它的特点是可以绘制带可信区间的校准曲线,下面咱们来操作一下。
library(CalibrationCurves)
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
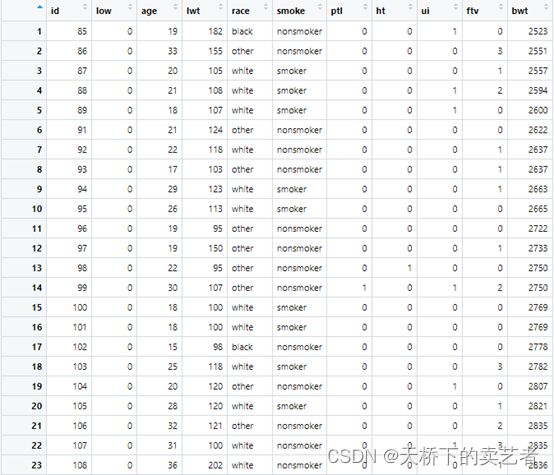
这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数,bwt 新生儿体重数值。 我们先把分类变量转成因子
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
对数据进行比例划分
set.seed(123)
tr1<- sample(nrow(bc),0.6*nrow(bc))##随机无放抽取
bc_train <- bc[tr1,]#60%数据集
bc_test<- bc[-tr1,]#40%数据集
使用建模集数据来建立模型
fit<-glm(low ~ age + lwt + race + smoke + ptl + ht + ui + ftv,
family = binomial("logit"),
data = bc_train )
校准曲线主要比较的是预测值和实际值的关系,所以咱们要生成预测概率和实际值。咱们线生成预测值
pr1<- predict(fit,type = c("response"))
生成了预测概率外,咱们还要生成一个实际的结局Y值
yval<-bc_train$low
绘制校准曲线其实很简单,就一句话代码,前面填概率后面填结局
valProbggplot(pr1, yval)


还可以对图形进行修饰,包括颜色和线条的形状
valProbggplot(pr1, yval, CL.smooth = TRUE, logistic.cal = TRUE, lty.log = 2,
col.log = "red", lwd.log = 1.5)

valProbggplot(pr1, yval, CL.smooth = TRUE, logistic.cal = TRUE, lty.log = 9,
col.log = "red", lwd.log = 1.5, col.ideal = colors()[10], lwd.ideal = 0.5)
