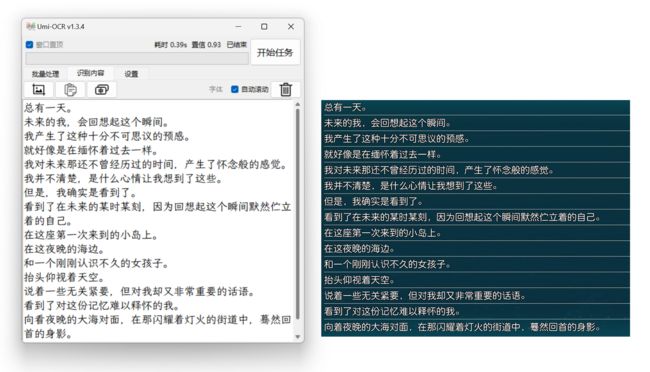
免费,开源,可批量的离线图片文字提取软件OCR
Umi-OCR 文字识别工具
适用于 Windows7 x64 及以上
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 批量:可批量导入处理图片,结果保存到本地 txt / md / jsonl 多种格式文件。也可以即时截屏识别。
- 高效:采用 PaddleOCR-json C++ 识别引擎。只要电脑性能足够,通常比在线OCR服务更快。
- 精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。

说明目录
- 简单上手 截图、批量识别~
- 排版优化 如何合并一个自然段内的文字?
- 忽略区域 如何排除截图水印处的文字?
- 多国语言 添加更多PP-OCR支持的语言模型库!
- 命令行调用 用命令行或第三方工具来调用Umi-OCR!
- 联动翻译软件 截图OCR后发送指定按键,触发翻译软件进行翻译
- 更多小技巧
- 问题排除 无法启动引擎 / 多屏幕截图异常 ?
下载
Win7/8 用户 及 凌动、赛扬、奔腾处理器用户:
兼容低版本Windows和无AVX指令集的CPU的新识别引擎正在测试阶段,详情见这儿 。
Win10/11 用户:
Github下载:Release v1.3.5
蓝奏云下载:https://hiroi-sora.lanzoul.com/s/umi-ocr
Umi-OCR 软件本体含 简体中文&英文 通用识别库。
配套 多国语言识别扩展包 可导入繁中,英,日,韩,俄,德,法识别库,请按需下载。
使用源代码
展开- main分支可能含有开发中的新功能。若您想使用稳定版本,建议切换到最新的Release分支。
- 安装依赖库:
pip install -r requirements.txt - 运行
main.py启动程序。测试无异常后,运行to_exe.py一键打包。 - 打包后,请将引擎组件 PaddleOCR-json 整个文件夹 放置于exe同目录下!
- 打包后,请将引擎组件 PaddleOCR-json 整个文件夹 放置于exe同目录下!!
- 打包后,请将引擎组件 PaddleOCR-json 整个文件夹 放置于exe同目录下!!!
兼容性(Paddle引擎版本)
- 系统仅支持 Win10 x64 及以上版本。
- CPU必须具有AVX指令集。(凌动、安腾、赛扬和奔腾处理器可能不兼容)
- 若您的软硬件不符合以上条件,可使用 Rapid引擎版本 。
前言
关于忽略指定区域的特殊功能:
类似含水印的视频截图、含有UI/按钮的游戏截图等,往往只需要提取字幕区域的文本,而避免提取到水印和UI文本。本软件可设置忽略某些区域内的文字,来实现这一目的。
当有大量的影视和游戏截图需要整理归档,或者想翻找包含某一段台词/字幕的截图;将这些图片提取出文字、然后Ctrl+F是一个很有效的方法。这是开发本软件的初衷。
关于离线OCR引擎 PaddleOCR-json :
对 PaddleOCR 2.6 cpu_avx_mkl C++ 的封装。效率高于Python版本PPOCR及部分Python编写的OCR引擎,通常比在线OCR服务更快(省去网络传输的时间)。支持更换Paddle官方模型(兼容v2和v3版本)或自己训练的模型,支持修改PPOCR各项参数。通过添加不同的语言模型,软件可识别多国语言。
简单上手
准备
下载压缩包并解压全部文件即可。
截图识别
点击截图按钮或自定义快捷键,唤起截图识别。

v1.3.4 还可以设置截图后生成一个预览窗口。预览窗口可以被钉在屏幕顶层,或调为半透明,方便对比查看。
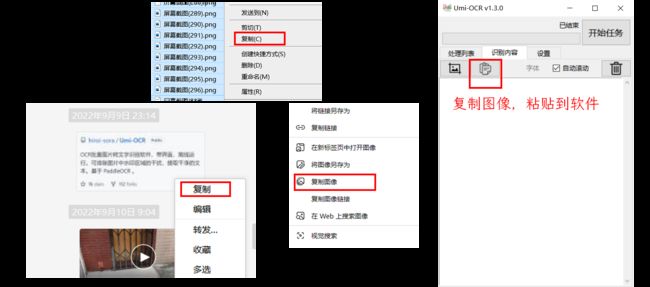
粘贴图片到软件
在任何地方(如文件管理器,网页,微信)复制图片,软件上点击粘贴按钮或快捷键,自动识别。
批量识别本地图片文件
将图片或文件夹拖进软件,批量转换文字。也可以点击按钮打开浏览窗口导入。
识别结果将保存到本地。可选生成纯文本txt文件、带链接Markdown文件、原始信息jsonl文件等不同格式。可配置任务完成后执行关机/待机。

文本块后处理(排版优化)
OCR识别出的文本是按“块”划分的,通常一行文字分为一块,有时还会将一行误划分为多块,这给阅读带来了不便。文本块后处理就是对文本块进行再加工的过程,合并同一行或同一段落内的文字,按正确的顺序排序。
下图表示不同排版应该选用何种处理方案:

所有排版方案一览:
展开横排-优化单行
将误划分为多块的同一行文字合并到一行。
横排-合并多行-左对齐
将多个左对齐的行视为同一段落,合并文字。左侧未对齐或行距过大的行视为下一段落。
横排-合并多行-自然段
将多个左对齐的行视为同一段落,且第一行的开头允许多空出两个全角空格的宽度。
横排-合并多行-模糊匹配
只要垂直投影有重叠,行高一致,距离较近的文本块,视为同一段落。
竖排-从左到右-单行 / 竖排-从右至左-单行
优化竖排识别,合并同一行文字,按从左到右或从右到左的顺序输出每一行。
注意,必须搭配支持竖排识别的模型库(识别语言)一起使用。
可视化预览:
可以在忽略区域编辑器内预览文本块后处理的效果。编辑器中以虚线框标出识别到、经过后处理的文字块。
这里仅仅是借用了编辑器来展示后处理的效果,实际运行任务时 忽略区域机制 早于 后处理机制 执行,不受后处理的影响。
忽略区域功能
忽略区域是本软件特色功能,可用于排除图片中水印的干扰,让识别结果只留下所需的文本。
展开“忽略区域”是指图片上指定位置与大小的矩形区域,完全处于这些区域内的文字块,将被排除。
- 点击 设置 选项卡中的 打开忽略区域编辑器 ,进入编辑器窗口。
- 将任意图片 拖入 该窗口,可预览该图片。将新图片拖入窗口可切换预览,但已绘制的忽略区域不会消失;可切换不同图片来仔细调整忽略区域。
- 绘制 忽略区域 :拖入图片后,点击选中左起第一按钮 +忽略区域 A ,然后在图片上按住左键拖拽,绘制矩形区域。可 撤销 步骤。
- 绘制完后,点击 完成 返回软件主窗口。若不想应用此次绘制,则右上角X,取消。
简单案例见下。
简单排除视频截图中的水印:
- 打开忽略区域设置窗口,拖入任一张截图。
稍等约1秒,面板上会显示出图片,识别到的文字区域会被虚线框起来。发现右上角的水印也被识别到了。
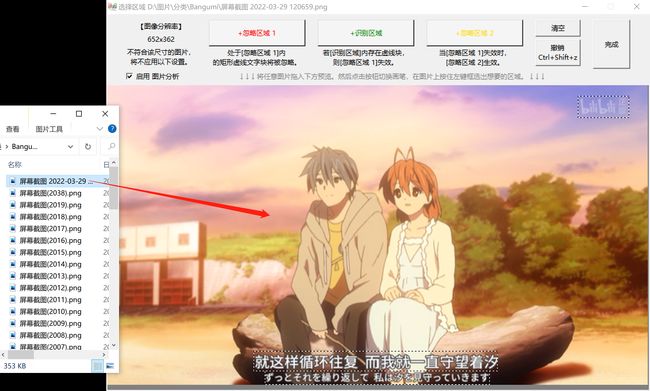
- 点击选择 +忽略区域 A 。在画面上按住左键拖拽,绘制方框完全包裹住水印区域,范围可以大一些。可绘制多个方框。
- 点击 完成 。返回主窗口, 开始任务 。
排除游戏截图中的两种UI:
- 假设有一组游戏截图,主要分为两类图片,这两类图片的文字位置和UI位置不太相同:
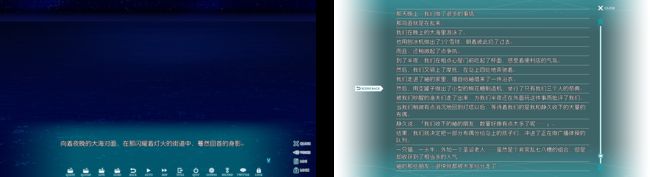
- 甲类(上图左)为对话模式,字数少,要保留的台词文本在画面下方,要排除的UI分布于底端。
- 乙类(上图右)为历史文本模式,字数多,从上到下都有要保留的文本(与甲类UI位置有重合),要排除的UI分布在两侧。
- 拖入一张甲类图片。选择 +忽略区域 A ,绘制方框包裹住要排除的 底端UI 。可绘制多个方框。
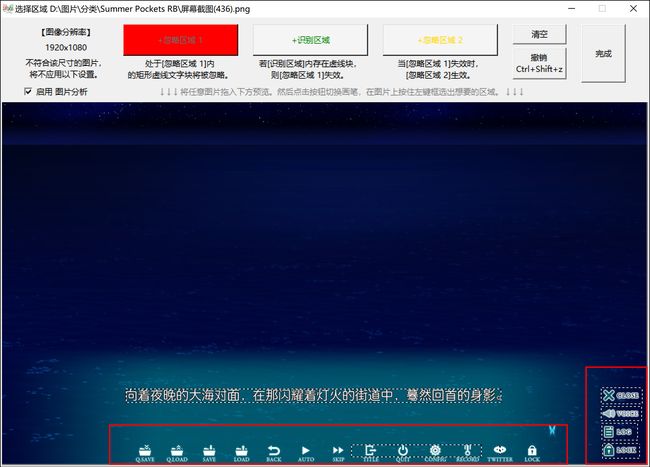
- 拖入一张乙类图片。选择 +识别区域 ,绘制方框包裹住 小部分要保留的文本 。注意只要该区域内含有任意保留文本即可,不需要画得很大,不需要包裹住所有保留文本;不能与甲类图中 可能存在的任何文本 重合。

- 然后选择 +忽略区域 B ,绘制方框包裹住乙类图要排除的 两侧UI 。可绘制多个方框。
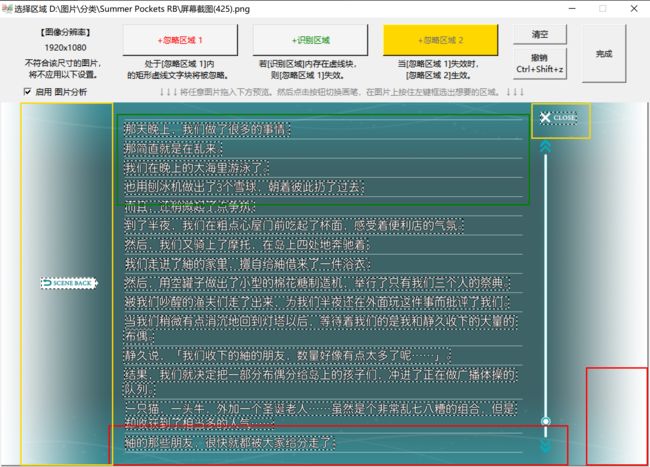
- 点击 完成 。返回主窗口, 开始任务 。
忽略区域处理逻辑:
-
忽略区域A :正常情况下,处于 忽略区域A 内的文字 不会 输出。
-
识别区域 :当识别区域内存在文本时,忽略区域A失效 ;即处于忽略区域A内的文字也 会 被输出。
-
忽略区域B :当 忽略区域A失效 时,忽略区域B才生效;即处于区域A内的文字 会 输出、区域B内的文字 不会 输出。
识别区域 忽略区域A 忽略区域B × 不存在文字 √ 生效 × 失效 √ 存在文字 × 失效 √ 生效 -
“忽略区域配置”只针对一种分辨率生效。假如配置的分辨率是1920x1080,那么批量识别图片时,只有符合1920x1080的图片才会排除干扰文本;1920x1081的图片中的文字会全部输出。
-
拖入预览的图片必须分辨率相同。假如先拖入1920x1080的图片,再拖入其它分辨率的图片;软件会弹窗警告。只有点击 清空 删除当前已配置的忽略区域,才能拖入其他分辨率图片,并应用此分辨率。
添加多国语言
展开方法一:下载 [Umi-OCR 多国语言识别扩展包] ,拷贝到软件目录即可。
点此跳转下载位置
扩展包内置语言:繁中,英,日,韩,俄,德,法
方法二:手动下载添加 PP-OCR 模型库
- 模型分为三种:det检测,cls方向分类,rec识别。其中det和cls是多语言通用的,只需下载新语言的rec识别模型即可。
- 前往 PP-OCR系列 V3多语言识别模型列表 ,下载一组rec识别模型。
- 若V3模型列表里没有找到目标语言,可以去支持语言列表查看PPOCR有没有提供这种语言。若有,则可能它暂未推出V3模型,可以先使用旧版V2模型。(V3模型网址中的2.x一路换成更小的数字可以查看旧版页面)
- 前往 PP-OCR系列 字典列表 ,下载对应语言的字典文件。(但V3英文字典
en_dict.txt不是本目录下的那个,而是在上一级目录) - 将下载好的文件解压放进软件目录的
PaddleOCR-json文件夹中。 - 复制一份
PaddleOCR_json_config_[模板].txt,改一下名。(文件名不允许有非英文字符!) - 打开复制好的
PaddleOCR_json_config_XX.txt,将 rec路径rec_model_dir和 字典路径rec_char_dict_path改成目标语言的文件(夹)的名称。若模型库是v2版本,还必须加上一行rec_img_h 32。 - 回到上一层目录
Umi-OCR,打开Umi-OCR_config.json,在"ocrConfig"中添加新语言的信息。键为语言名称,值的path为config txt文件的名称。保持json格式,注意逗号。(修改config.json文件时,请确保未打开软件,否则配置可能被覆盖。) - 打开软件,检查设置页的
识别语言下拉框是否已经能选择该语言。
进阶操作 & 小技巧
命令行调用
展开v1.3.3 后支持通过命令行调用Umi-OCR,执行部分识图任务。
若软件未在运行,则命令行会启动软件并执行任务。若软件已在后台运行,则命令行会直接调用后台的软件执行任务。这样多次调用时可以节省初始化的时间。
注意命令行调用入口是程序目录的extra中的umiocr.exe,而不是软件常规入口(Umi-OCR 文字识别.exe)。
⚠︎ umiocr.exe在程序目录的extra文件夹中。 ⚠︎
命令行语法按照谷歌gflags规则:
-命令或-命令=参数或-命令 参数
指令0:启动软件
若软件尚未启动,则任意指令均会启动软件主程序。
指令1:显示窗口
umiocr.exe
或
umiocr.exe -show
无论主窗口处于什么状态(最小化、收到托盘、被别的窗口覆盖),该指令都会让主窗口弹到最上层。
指令2:隐藏窗口
umiocr.exe -hide
将窗口收到托盘区或最小化。
show和hide这两个指令可以与其它指令混用,如 umiocr.exe -clipboard -show
指令3:关闭软件
umiocr.exe -exit
指令4:本地图片识别
umiocr.exe -img=图片.png
支持图片/文件夹;多个路径以逗号,分隔;含空格的路径加双引号""。如:
umiocr.exe -img="D:/图库,E:/my img/图片.png"
若路径含中文,请务必加双引号。
指令5:剪贴板识图
umiocr.exe -clipboard
指令6:截屏识图
umiocr.exe -screenshot
指令7:切换识别语言
umiocr.exe -language=序号
“序号”为软件设置里各个语言的排序,从0开始。从上往下数,比如简中排第一,那么是-language=0。繁中排第二,那么是-language=1。英文排第四,-language=3。以此类推。
复制后发送按键 & 联动翻译软件
展开发送指定按键
v1.3.5 起,支持快捷识图完成并将结果写入剪贴板后,发送一组指定按键,触发翻译软件进行翻译。当然也可以用于触发你的AHK脚本等,实现更多奇奇怪怪的功能。
这是一个隐藏高级功能,请先勾选设置页底部的高级选项,重启软件。设置页的快捷识图板块会多出一个项目:自动复制后发送按键 。可以录制一组快捷键并修改重复次数(支持单击、双击等)。当截图OCR完成后,会发送该按键组合。注意,必须同时勾选自动复制结果才能让该功能生效。
经过测试,Umi-OCR可以顺利地与 CopyTranslator 及 沙拉查词 联动触发翻译,以下是配置方法。
联动 CopyTranslator
-
下载 CopyTranslator。这里示例所用的版本是
v11。 -
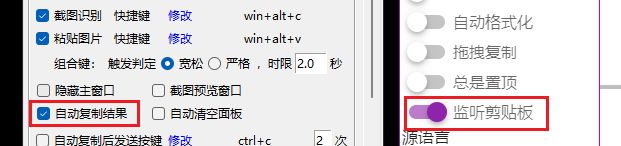
如果不介意CopyTranslator监听剪贴板(每次剪贴板变动都尝试翻译),那么勾选Umi-OCR的
自动复制结果和CopyTranslator的监听剪贴板即可。
-
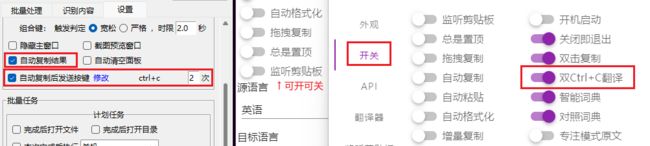
如果不一定始终开启监听剪贴板,又希望Umi-OCR在任何情况下能唤起CopyTranslator,可以这样处理:CopyTranslator在设置里勾选
双Ctrl+C翻译;Umi-OCR的自动复制后发送按键录制为ctrl+c,2次。
联动 沙拉查词
- 沙拉查词 是一款浏览器插件,支持Chrome、Edge等浏览器,这是下载页面。下面以Edge浏览器为例讲解配置方法。其他浏览器大同小异。(Firefox支持不完善,不推荐。)
- 打开沙拉查词的插件设置页面,左边栏选择
基本选项,右边栏勾选后台保持运行。(如果不勾选也能使用,但必须保持浏览器开启。) - 左边栏点击
隐私设置,右边栏点击设置快捷键。

- 在弹出的新页面中,将沙拉查词的
在独立窗口中搜索剪贴板内容设置任意一组快捷键,然后右边改为全局。Umi-OCR的自动复制后发送按键录制为相同快捷键,1次。

- 回到沙拉查词的设置页,左边栏点击
权限管理,勾选读取剪贴板。

自定义计划任务
展开- 除了默认的自动关机/待机外,您还可创建自己的计划任务,让软件在完成一次批量识别后执行自定义cmd命令。
- 在软件关闭的情况下,打开配置文件
Umi-OCR_config.json。也可以先打开软件,点击设置页最底部的 打开设置文件 ,然后退出软件。 - 在
okMission中添加一项元素。 - 键为任务名称,值为字典,其中
code为cmd命令。多条命令可用&分隔。例:"我的任务": {"code": "cmd命令1 & 命令2"}
内存清理
展开本功能默认关闭。
供内存占用十分敏感的用户使用,会有偶尔阻慢任务速度的副作用。 一般用户无需开启。
若有需要开启,请在设置页拉到底部,勾选高级选项,重启软件,然后:OCR识别引擎设置 → 自动清理内存 → 将任一参数改成>0的值 。
原理是满足任一条件(内存占用超限,或者一段时间没有执行任务)则重启引擎组件,释放当前引擎占用的所有内存。

添加到运行(Win+R快捷键)
展开- 在任何地方创建一个文件夹,名字随意,将该文件夹的路径加入系统环境变量。
- 软件创建一个快捷方式,改一个简短的名字,如
umi。 - 将快捷方式扔进第1步的文件夹中。
- 任何时候按下
Win+R,在弹窗中输入umi,即可打开软件。
- 提示:请不要起名为
ocr,因为系统可能存在同名的注册路径,无法用此指令唤起第三方软件。
问题排除
无法启动引擎
展开PaddleOCR引擎暂不支持在没有AVX指令集的CPU上运行,遇到该问题可尝试换用RapidOCR引擎。
下图指示如何判断该问题是否由缺失AVX引起。

常见的家用CPU一般都支持AVX指令集,如下:
| AVX | 支持的产品系列 | 不支持 |
|---|---|---|
| Intel | 酷睿Core,至强Xeon,11代及以后的赛扬Celeron和奔腾Pentium | 凌动Atom,安腾Itanium,10代及以前的赛扬Celeron和奔腾Pentium |
| AMD | 推土机架构及之后的产品,如锐龙Ryzen、速龙Athlon、FX 等 | K10架构及之前的产品 |
可通过 CPU-Z 软件查看自己CPU的指令集信息。
多屏幕截图不正常
展开由于windows缩放对屏幕坐标系带来的影响,若外接多块屏幕,且缩放比例不一致时,可能导致Umi-OCR内置截图模块异常,如画面不完整、窗口变形、识别不出文字等。
若出现这种情况,以下提供三种可替代的解决方案,您可选择一种使用。
- 在系统设置里的【更改文本、应用等项目的大小】将所有屏幕调到相同数值。见下图左。

-
软件附带了第二套截图方案:调用windows内置的“截图和草图”来完成截图并唤起OCR。可在软件设置里切换。(若系统截图后不能唤起OCR,请确保系统能通过
win+shift+S触发截图,且自动复制到剪贴板的开关不能关闭(默认是打开的)。见上图右。)
-
禁用软件的DPI缩放。对
Umi-OCR 文字识别.exe,右键 → 属性 → 兼容性 → 更改更高DPI设置 → 勾选替代高DPI缩放行为。
未找到引擎组件
请将引擎组件 PaddleOCR-json 文件夹 放置于程序入口(main.py或exe)同目录下。
效率测试
展开测试机器:
| CPU | TDP | RAM | 是否兼容mkldnn |
|---|---|---|---|
| r5 4600u | 15w | 16g | 无报错 |
测试集:
| 图片张数 | 测试条件 | 分辨率 | 平均字块数量 | 平均字符数量 | 文字语言 |
|---|---|---|---|---|---|
| 100 | 环境相同,多次测量取平均值 | 1920x1080 | 15 | 250 | 简体中文 |
测试结果:
| Umi-OCR版本 | 1.2.5 | 1.2.5 | 1.2.6 | 1.2.6 | 1.2.6 | 1.2.6 |
|---|---|---|---|---|---|---|
| PaddleOCR-json版本 | 1.1.1 | 1.1.1 | 1.2.0 | 1.2.0 | 1.2.0 | 1.2.0 |
| PP-OCR C++版本 | 2.1 | 2.1 | 2.6 | 2.6 | 2.6 | 2.6 |
| 是否开启mkldnn | ✅ | ✅ | ✅ | ✅ | ||
| PP-OCR模型库版本 | v2 | v2 | v2 | v3 | v3 slim | v3 |
| 总耗时(秒) | 90 | 120 | 65 | 63 | 170 | 400 |
| 平均单张耗时(秒) | 0.9 | 1.2 | 0.65 | 0.63 | 1.7 | 4.0 |
| 内存占用峰值(MB) | 1000 | 350 | 1200 | 1700 | 5800 | 500 |
结论:
- 在启用mkldnn情况下,
v1.2.6及之后的版本,比前代的效率具有显著优势。新版调教倾向于榨干硬件的性能,内存占用高于旧版。 - 不启用mkldnn时,新版本效率不如前代。故您的CPU若不支持mkldnn(极早期AMD型号),可尝试使用
v1.2.5的旧版本Umi-OCR。 - 虽然Paddle官方文档中说经过压缩剪枝蒸馏量化的slim版模型的性能指标会超过传统算法,但实测 v3 slim 模型的性能远不如原始版本,还可能伴随着内存泄漏的问题。也许是 PP-OCR C++ 引擎不适配。在该问题解决之前,Umi-OCR发行版提供原始版本模型。
开发说明
展开开发者滴碎碎念
- 如果想用接口调用OCR,可试试 PaddleOCR-json 图片转文字程序 。
- PPOCR v2.6 (PaddleOCR-json v1.2.0) 版本提高了批量处理的平均速度,但代价是需要花费更长时间进行初始化。提高了启用mkldnn加速时的识别速度,但代价时不开启加速时效率更低。(CPU只要不是特别早期的AMD,一般都能使用mkldnn,但加速幅度可能不如同档次的Intel。)
- 未来将增加 openblas 版识别引擎,进一步优化AMD的效率。(有 生 之 年)
- 使用
pyinstaller打包。可以运行根目录下的 to_exe.py 一键打包。 - 配置文件
Umi-OCR_config.json在第一次运行程序时生成。若想自定义引擎组件的路径,可以修改其中的ocrToolPath属性。支持绝对/相对路径。可以实现多个前端共用一套引擎组件。 v1.3.0几乎重写了整个项目框架,将业务逻辑与UI代码解耦,划分出多个子模块。这些子模块我认为是比较方便拓展的:- 文件输出模块
ocr/output_*.py - 文本块后处理模块
ocr/tbou/*.py
- 文件输出模块
- 添加一个新子模块的一般方法是:
- 在
utils/config.py里添加需要的配置项。在_ConfigDict里编写配置项参数后,可以自动生成tk.var变量,读、写本地配置文件。程序运行过程中,参数发生更改就会自动写入本地。 - 在
ui/win_main.py里添加需要的UI。需要tk.var动态变量时,直接Config.getTK()拿来绑定。 - 继承模块父类,写业务逻辑。初始化时读入配置,事件方法里写对应的处理。
- 模块尽量不要有过多对外接口,传参越多越容易乱。要什么去
Config里拿就是了,比如要调用主窗口类的方法就用Config.main,要参数就Config.get()。
- 在
- 反正
Config就是中枢,是各个模块之间、模块与配置之间交流的全局接口。尽量不要跨线程同时读写。我是设计在执行任务时能修改到配置项的UI都给锁定,以免影响任务线程读取。 - 个人喜欢小而美,所以尽量不使用体积大的包。一直用tkinter而不用功能强大的QT也是这个原因,PYQT的体积近50m,几乎是整个项目打包后(不含引擎)的两倍大了。
- 注释超级多,不怕看不懂~ 不过有些代码写得比较丑,请见谅。
TODO
已完成- 输出内容可选为markdown风格并嵌入图片路径。
- 设置项能保存。
- 自动打开输出文件or文件夹。
- 识别剪贴板中的图片。
- 任务进行时,禁用部分设置项。
- 计划任务:完成后自动关机/休眠等。
- 递归导入文件夹。
- 优化适配PaddleOCR v3模型。
- 增加OCR引擎进程常驻后台的模式,大幅缩短剪贴板识图等零碎任务动时间。
- 监控OCR引擎进程内存占用,并可随时强制停止该进程。
- 内置截图。
- 可最小化至系统托盘。
- 优化UI:以图标代替文字按钮。设置项悬停有气泡提示框。
- 自动检测Windows语言是否兼容
- 解决引擎Opencv对不同地区语言Windows的兼容性。
- 优化引擎参数设置。
- 排版后处理:匹配/合并同段落文本,支持横/竖排。
- 可设置窗口弹出模式(锁定置顶)。
- 重新快捷键模块,解决失效和录制不正确的Bug。
- 设置开机自启。
- 创建快捷方式到开始菜单、桌面。
- 多开提示。
- 截图时隐藏窗口。
- 结构输出到每个图片同名的单独txt文件
- 创建开机启动项时,可选
不显示主窗口。 - OCR结果输出到每个图片同名的单独txt文件。
- 增加独立的设置语言窗口,可在多处点开,便于切换语言。
- 合并段落添加
合并自然段-西文模式,可在英文段落换行时补充空格。 - 快捷识图可选
自动清空面板,只显示本次识别结果,且隐藏时间信息。 - 通过命令行控制Umi-OCR。
- 弹出悬浮的识别成功与否的提示。
- 定时或超过限度时自动清理引擎内存占用。
- 文本纠错。
- 多国语言。
- 高分屏支持。
- PDF文档识别。
- 对图片重命名。
- 提高初始化速度。
- 忽略区域能保存预设。
- 缩减离线OCR模块的体积。
- 自动检测CPU指令集是否兼容。
- 优化界面设计,分离功能模块到不同标签页。
- 离线OCR模块增加
no_avx和openblas版本。
更新日志
点击版本号链接可前往对应备份分支。
v1.3.5 2023.6.20
- 新功能:复制识别结果后,可发送指定按键,以便联动唤起翻译器等工具。
- 新功能:命令行增加切换识别语言的指令。
- 修Bug:低配置机器上有概率误报
OCR init timeout: 5s。#154 , #156。 - 调整:默认停止任务30秒后释放一次内存。
v1.3.4 2023.4.26
- 新功能:截图预览窗口。
- 新功能:可用方向键微调截图框位置。
- 修Bug:拖入图片时有几率卡退主窗口 issue #126 。
- 优化了一些处理流程。
v1.3.3 2023.3.19
- 新功能:命令行模式。
- 新功能:识图完成的通知悬浮窗。
- 新功能:自动清理引擎内存。
- 修复了一些BUG,优化了一些UI表现。
v1.3.2 2022.12.1
- 新功能:创建开机启动项时,可选
不显示主窗口。 - 新功能:OCR结果输出到每个图片同名的单独txt文件。
- 新功能:增加独立的设置语言窗口,可在多处点开,便于切换语言。
- 新功能:合并段落添加
合并自然段-西文模式,可在英文段落换行时补充空格。 - 新功能:快捷识图可选
自动清空面板,只显示本次识别结果,且隐藏时间信息。 - 修复了一些BUG。
v1.3.1 2022.11.4
- 修Bug:快捷键模块重写,引入pynput库,舍弃keyboard库,解决几率失效、录制不正确等Bug。
- 新功能:添加开机自启,桌面快捷方式,开始菜单快捷方式。
- 新功能:多开软件时提示。
- 新功能:截图时隐藏窗口。
- 调整UI:使用频率极低的设置项设为隐藏的高级选项。
- 优化:检查引擎组件是否存在。
- 优化:
横排-合并多行-自然段优化逻辑,支持0~2全角空格首行缩进。
v1.3.0 2022.9.29
- 新功能:框选截屏。
- 新功能:系统托盘图标。
- 新功能:引擎进程常驻。
- 新功能:文本块后处理模块。
- 新功能:自定义主输出栏字体。
- 新功能:设置窗口弹出模式(保持置顶)。
- 调整UI:自适应Win风格组件。
- 修正了Bug:系统语言兼容性问题 issue #16 。
- 修正了Bug:微信图片粘贴问题 issue #22 。
- 更新PaddleOCR-json模块至
v1.2.1,提供剪贴板支持。快捷识图通过剪贴板中转,无需再保存临时文件到硬盘。
v1.2.6 2022.9.1
- 更新PaddleOCR-json模块至
v1.2.0,提高识别速度、准确度。 - 调整UI:更方便地用下拉框切换识别语言。
- 调整UI:可以从主窗口任意位置/任意选项卡拖入图片。
- 修正了Bug:提高程序健壮性,增加启动子进程时的更多异常处理情况。
- 修正了Bug:彻底解决了对边缘过窄的图片,识别结果不准确的问题 issue #7 。
- 优化适配PP-OCRv3模型,彻底解决了v3版模型比v2慢、不准的问题 issue #4 。
v1.2.5 2022.7.22
- 新功能:计划任务。识图完成后执行自动关机等任务。
- 新功能:可选拖入文件夹时递归导入子文件夹中所有图片。
- 调整UI:添加一些配置文件的快捷入口。
v1.2.4 2022.6.4
- 新功能:可选识别剪贴板图片后自动复制识别的文本。
- 补充功能:快捷键调用剪贴板识图时,若程序窗口被最小化,则恢复前台状态并挪到最前位置。
v1.2.3 2022.5.31
- 新功能:读取剪贴板图片。配置全局快捷键调用该功能。
v1.2.2 2022.4.30
- 新功能:可选任务完成后自动打开输出文件或目录。
v1.2.1 2022.4.16
- 更新PaddleOCR-json模块至
v1.1.1,修正了可能得到错误包围盒的漏洞。
v1.2.0 2022.4.8
- 可选生成图文链接.md文件,作为索引使用有更佳的观感。
- 修改设置面板的样式,改为滚动面板以容纳更多设置选项。
- 用户修改配置项后可自动保存。
v1.1.1 2022.3.30
- 修正了Bug:退出忽略区域窗口时,OCR子进程未关闭。
v1.1.0 2022.3.30
- 新功能:忽略区域窗口以虚线框 展示识别出的文字块。
v1.0.0 2022.3.28
- “梦开始的地方”
感谢
本项目核心引擎组件源自 PaddlePaddle/PaddleOCR:
Awesome multilingual OCR toolkits based on PaddlePaddle
本项目中所使用的库:
google/python-gflags
Python implementation of the Google commandline flags module.
moses-palmer/pynput
This library allows you to control and monitor input devices.
Infinidat/infi.systray
A Windows system tray icon with a right-click context menu.
Pwm
Pmw is a toolkit for building high-level compound widgets in Python using the Tkinter module.
Umi-系列图片处理软件
Umi-OCR 批量图片转文字软件 ◁
Umi-CUT 批量图片去黑边/裁剪/压缩软件