关于时空数据的培训 GAN:实用指南(第 01/3 部分)
第 1 部分:深入了解 GAN 训练中最臭名昭著的不稳定性。

一、说明
GAN 是迄今为止最受欢迎的深度生成模型,主要是因为它们最近在图像生成任务上产生了令人难以置信的结果。然而,GAN并不容易训练,因为它们的基本设计引入了无数的不稳定性。如果你尝试过用MNIST以外的任何东西训练GAN,你很快就会意识到,所有关于训练他们的痛苦(以及试图解决这个问题的相关研究领域)的说法并没有把问题放大。
二、GAN的不稳定性
我们将系统地解决这些臭名昭著的不稳定性的原因和解决方案,我们在广泛尝试了书中的几乎所有技巧后,在我们的实验中发现这些不稳定性在经验上运作良好。这个由三部分组成的系列文章是关于训练 GAN 的实用指南,重点是时空数据生成,结构如下:
1. 第 1 部分:深入了解 GAN 训练中最臭名昭著的不稳定性。
2. 第 2 部分:第 1 部分中讨论的常见陷阱的可能解决方案。
3. 第 3 部分:在时空数据上训练 GAN 的特殊情况——要跟踪的指标、独特的复杂性及其解决方案
本系列中讨论的不稳定性和解决方案与模型和用例无关,也与时空情况相关。它们是任何GAN训练练习的良好起点。在本文中,我们将通过详细介绍 GAN 训练中最臭名昭著的不稳定性来讨论为什么训练 GAN 如此难以捉摸。我们将研究 a) 鉴别器 (D) 和生成器 (G) 训练之间的不平衡如何导致模式崩溃和由于梯度消失而导致的静音学习;b) GAN 对超参数的敏感性,以及 c) 在模型性能方面误导性 GAN 损失。
[注意:我们假设本文的读者具备 GAN 基础知识的先决条件,并且在某些时候也有一些训练 GAN 的经验。为此,我们将跳过“什么是 GAN?”请读者阅读本文以快速回顾一下。]
三、为什么训练 GAN 如此难以捉摸?
在本节中,我们详细介绍了GAN训练中一些最臭名昭著的不稳定性,并详细介绍了在我们的实验中在实践中运作良好的每个可能的解决方案。话虽如此,建议在原版设置下运行前几次迭代,以探测在手头的架构和任务中观察到以下哪些陷阱。随后,您可以迭代地实现上述解决方案(根据解决方案的复杂性及其根据我们的经验的有效性进行排序)以进一步稳定训练。请注意,这些提示仅用作方向起点,而不是一次性解决方案的详尽列表。建议读者进一步探索其架构和训练动态,以获得最佳结果。
3.1. 生成器和鉴别器之间的不平衡
判断一幅画是否是梵高很容易,但要真正制作一幅画却非常困难。因此,人们认为G的任务比D的任务更困难。同时,G 学习生成现实输出的能力取决于 D 的训练程度。最优 D 将给 G 丰富的信号,以学习并改进其生成。因此,重要的是要平衡G和D的训练以获得最佳学习条件。
GAN基于零和非合作博弈,试图实现纳什均衡。然而,众所周知,某些成本函数不能收敛于梯度下降,特别是对于非凸博弈。这在GAN训练中引入了许多不稳定性,因为G和D训练步骤在最小-最大游戏中不平衡,导致学习梯度欠佳。这些不稳定性将在下面讨论:
1. 渐变消失:
对于最佳GAN训练,D是否应该优于G,反之亦然,需要通过查看以下参数来回答-
a) 如果 D 变得太好太快,G 的梯度就会消失,它永远无法赶上。
b) 另一方面,如果 D 是次优的,那么由于 D 的预测性能很差,G 很容易用胡言乱语来愚弄它。这再次导致没有梯度可供学习,导致G输出没有改善。
因此,在理想情况下,G和D应该以周期性的方式比另一个更好。如果您看到其中一个损失单调地向任何方向移动,那么您的 GAN 训练很可能已经崩溃。
2. 模式崩溃:如果 G 被不成比例地训练得更多,它会收敛到重复产生相同的输出,从而很好地愚弄 D,而没有任何动力专注于样本的多样性。
3.2 渐变消失原因
原始GAN目标的生成器(Ian Goodfellow,2014)优化了非饱和JS发散,如下所示:
![]()
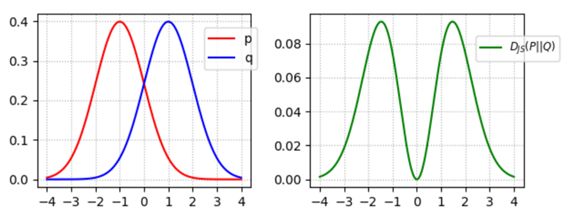
在这种情况下,很容易看出,如果生成器错过了某些分布模式(即,当 p(x) > 0 但 q(x) → 0 时,惩罚很高),以及如果生成的数据看起来不真实(即,如果 p(x) → 0 但 q(x) > 0,则惩罚很高)。这促使发生器产生更高质量的输出,同时保持多样性。
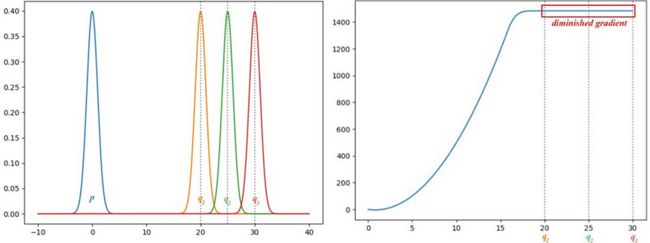
然而,当鉴别器达到最优时,该公式会导致生成器的梯度消失。从下面的例子中可以明显看出这一点,其中 p 和 q 是高斯分布的,p 的平均值为零。右图显示 JS-背离的梯度从 q1 到 q3 消失。这将导致GAN生成器在这些区域的损失饱和时学习非常缓慢(甚至根本不学习)。这种情况在GAN训练的早期就表现出来了,当时p和q非常不同,并且D的任务更容易,因为G的近似与实际分布相去甚远。
3.3 模式折叠常识
模式崩溃是迄今为止训练 GAN 时最困难、最不平凡的问题。虽然对模式崩溃有很多直观的解释,但在实践中我们对它的理解仍然非常有限。到目前为止,一个关键的直观解释已经帮助了从业者,那就是在D上没有足够的更新的情况下,G被训练得不成比例。生成器最终收敛到找到最愚弄D的最佳图像x*,即从鉴别器角度看最真实的图像。在这种情况下,x* 变得独立于 z,这意味着对于每个 z,它都会生成相同的图像。

最终,D(再次训练时)学会了丢弃该模式的图像作为假图像。这反过来又迫使生成器寻找下一个脆弱点并开始生成该漏洞点。D和G之间的猫捉老鼠追逐仍在继续,G过于专注于“作弊”,以至于它甚至失去了检测其他模式的能力。这在上图中可以看到,其中顶行显示了 G 应该遵循的理想学习过程。底行演示了模式折叠的情况,其中 G 专注于很好地产生一种模式,而忽略其他模式。
3.4 对超参数的敏感性
GAN对超参数非常敏感,周期。如果没有良好的超参数,任何成本函数都不起作用,因此建议首先广泛调整超参数,而不是在开始时尝试不同的损失函数。调整超参数需要时间和耐心,在开始使用高级损失函数之前,了解架构的基本训练动态非常重要,这些函数将引入自己的超参数集。
四、GAN损失与生成质量的相关性
在通常的分类任务中,成本函数与模型的准确性相关(较低的损失意味着较低的误差意味着更高的准确性)。然而,GAN的损失衡量了一个参与者在最小-最大博弈(生成器与鉴别器)中与另一个参与者的表现。发生器损耗增加,但图像质量却在改善是很常见的。因此,在训练GAN时,损失“收敛”与生成质量之间的相关性很小,因为不稳定的GAN损失通常具有误导性。图像生成任务中使用的一种非常有效且被广泛接受的技术是通过在不同训练阶段对生成的图像进行目视检查来跟踪训练进度。但这随后使模型比较更加困难,并使调优过程进一步复杂化,因为很难从这种主观评估中选择最佳模型。然而,在我们的实验中,我们很快意识到GAN训练的这个非常关键的方面 - 通过正确的指标跟踪生成进度 - 也是人们谈论训练GAN时最容易被忽视的方面之一。此外,与图像不同,我们无法“直观地”有效地评估时空数据的训练进度。因此,设计和跟踪与时空数据相关的指标变得至关重要,这些指标客观地指示模型性能。
现在我们已经详细介绍了一些突出的GAN训练陷阱,接下来出现的问题是我们如何检测和解决它们?我们将在本系列的下一篇博客中详细讨论这个主题,在广泛尝试了书中的每个技巧后,我们为每个解决方案提供了多种解决方案。我们按照其易于实施及其各自影响的顺序编制列表,以就GAN培训的迭代增强功能提出建议。尚塔努·钱德拉