6.3、Flink数据写入到MySQL
目录
1、添加POM依赖
2、这一个完整的案例
3、何时批量写入MySQL呢?
4、容错性的保证(精确一次&至少一次)
4.1、 至少一次
4.2、精确一次
1、添加POM依赖
Apache Flink 集成了通用的 JDBC 连接器,使用时需要根据生产环境的版本引入相应的依赖
官网链接:官网
org.apache.flink
flink-connector-jdbc
1.17-SNAPSHOT
mysql
mysql-connector-java
5.1.47
2、这一个完整的案例
开发语言:java1.8
flink版本:flink1.17.0
package com.baidu.datastream.sink;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.sql.PreparedStatement;
import java.sql.SQLException;
// 将 Flink数据写入到 MySQL
/*
* TODO Step1、在 开启socket服务,输入下列数据
* 1,红楼梦,曹雪芹,19.8,1
* 1,红楼梦,曹雪芹,19.8,2
* 1,红楼梦,曹雪芹,19.8,3
* 1,红楼梦,曹雪芹,19.8,4
* 1,红楼梦,曹雪芹,19.8,5
* 1,红楼梦,曹雪芹,19.8,6
*
* TODO Step2、MySQL book表DDL
* create table books(id int, title varchar(99), author varchar(99), price double, qty int);
*
* */
public class SinkMySQL {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启checkpoint后,会触发 数据写入MySQL操作
//env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 2.将socket作为数据源(开启socket端口: nc -lk 9999)
DataStreamSource streamSource = env.socketTextStream("localhost", 9999);
// 3.初始化 JdbcSink实例
SinkFunction jdbcSink = JdbcSink.sink(
// TODO 1、指定要执行的SQL
"insert into books (id, title, author, price, qty) values (?,?,?,?,?)",
// TODO 2、指定 将 dataStream数据 封装到 SQL的占位符中
new JdbcStatementBuilder() {
@Override
public void accept(PreparedStatement preparedStatement, String s) throws SQLException {
int id = Integer.parseInt(s.split(",")[0]);
String title = s.split(",")[1];
String author = s.split(",")[2];
double price = Double.parseDouble(s.split(",")[3]);
int qty = Integer.parseInt(s.split(",")[4]);
preparedStatement.setInt(1, id);
preparedStatement.setString(2, title);
preparedStatement.setString(3, author);
preparedStatement.setDouble(4, price);
preparedStatement.setInt(5, qty);
}
},
// TODO 3、指定 批量写入MySQL大小和频率 (当满足 设置的批次或者提交时间时 会触发写入MySQL)
// 重要:这里的设置非常重要,它控制着flink写入MySQL的延迟程度
// 当不设置 JdbcExecutionOptions 时,将使用默认配置 (缓存5000条数据后触发写入操作)
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 插入发生异常重试次数 注意:只支持SQL Exception 异常及其子类异常重试(默认值为3)
.withBatchSize(1) // 批量的大小:条数(默认值为5000)
.withBatchIntervalMs(2000) // 批次的时间间隔 (默认值0L,表示无限长的时间间隔)
.build(),
// TODO 4、指定 MySQL的连接信息
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("gaocun123")
.withConnectionCheckTimeoutSeconds(60) // 重试的超时时间
.build()
);
streamSource.addSink(jdbcSink);
// 3.触发程序执行
env.execute();
}
}
3、何时批量写入MySQL呢?
可以通过 JdbcExecutionOptions 来控制写入MySQL的数据量和时间频率,这也决定了Flink写入MySQL的延迟程度。
JdbcExecutionOptions 三个常用的参数:
- withMaxRetries(3) :插入操作发生异常时的重试次数
- 注意:只支持SQL Exception 异常及其子类异常重试(默认值为3)
- withBatchSize(100) : 批量写入数据的条数(默认值为5000)
- withBatchIntervalMs(2000) : 批量写入的时间间隔 (默认值0L,表示关闭定时写入)
实时写入MySQL应该如何配置:
// TODO 实时写入MySQL
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 插入发生异常重试次数 注意:只支持SQL Exception 异常及其子类异常重试(默认值为3)
.withBatchSize(1) // 批量的大小设置为1,表示产生一条数据就会被写入MySQL
.withBatchIntervalMs(0) // 批次的时间间隔为0,表示关闭定时写入
.build()4、容错性的保证(精确一次&至少一次)
4.1、 至少一次
使用Flink提供的 JDBC Sink 能够保证至少一次的语义
注意:
这里的至少一次的保证指的是 MySQL故障后,数据不会丢失
4.2、精确一次
对于 JDBC Sink,例如 MySQL,要实现故障时的精确一次的保证通过 upsert 语句或幂等更新实现
MySQL 中常用的 upsert 语句:
在MySQL中,"upsert"是指一种操作,它根据一定的条件在表中插入新的行,或者如果已经存在满足条件的行,则更新这些行的数据
使用 upset语句的前提是:
表具有唯一键(UNIQUE KEY)或主键(PRIMARY KEY),以便在插入行时进行冲突检测
DDL:
-- TODO 要想使用 upsert语句,表必须具有 PRIMARY KEY 或者 UNIQUE约束
create table books
(
id int PRIMARY KEY,
title varchar(99) UNIQUE,
author varchar(99),
price double,
qty int
);insert into 语句
功能:向 表中写入数据,如果 主键字段(id)或UNIQUE字段(title) 存在时,则插入数据失败
示例:
insert into books (id, title, author, price, qty) values (1,'红楼梦','红楼梦',19.9,1);

insert ignore 语句
功能: 向 表中写入数据,如果 主键字段(id)或UNIQUE字段(title) 存在时,则忽略这次插入行为
示例:
-- insert ignore 语句
insert ignore books (id, title, author, price, qty) values (1,'红楼梦','曹雪芹1',19.9,1);
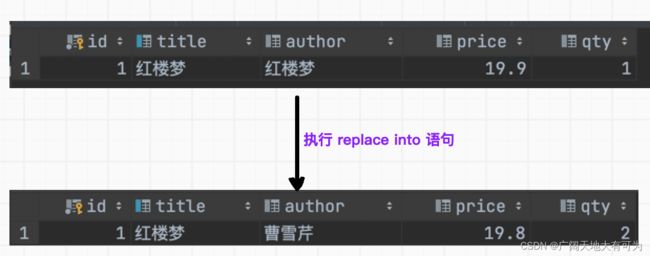
replace into 语句 (更新所有字段)
功能:向 表中写入数据,如果 主键字段(id)或UNIQUE字段(title) 存在时,会删除原有数据,再将这次插入数据写入
示例:
-- replace into 语句
replace into books (id, title, author, price, qty) values (1,'红楼梦','曹雪芹',19.8,2);
insert on duplicate key update 语句 (更新局部字段)
功能:向 表中写入数据,如果 主键字段(id)或UNIQUE字段(title) 存在时,只会对 on duplicate key update 后指定的字段进行更新
示例:
-- insert on duplicate key update 语句
insert ignore books (id, title, author, price, qty) values (1,'红楼梦','曹雪芹?',8.8,3)
on duplicate key update author = 'XueQinCao';
;