PostgreSQL 事务&并发&锁
文章目录
- PostgreSQL 事务
-
- 大家都知道的 ACID
- 事务的基本使用
- 保存点
- PostgreSQL 并发
-
- 并发问题
- MVCC
- PostgreSQL 锁机制
-
- 表锁
- 行锁
- 总结
PostgreSQL 事务
大家都知道的 ACID
在日常操作中,对于一组相关操作,通常要求要么都成功,要么都失败。在关系型数据库中,称这一组操作为事务。为了保证整体事务的安全性,有ACID这一说:
- 原子性A:事务是一个最小的执行单位,一次事务中的操作要么都成功,要么都失败。
- 一致性C:在事务完成时,所有数据必须保持在一致的状态。(事务完成后吗,最终结果和预期结果是一致的)
- 隔离性I:一次事务操作,要么是其他事务操作前的状态,要么是其他事务操作后的状态,不存在中间状态。
- 持久性D:事务提交后,数据会落到本地磁盘,修改是永久性的。
PostgreSQL相比于其他数据库,有一个比较大的优化,DDL也可以包含在一个事务中。比如集群中的操作,一个事务可以保证多个节点都构建出一个表,才算成功。
事务的基本使用
PostgreSQL跟MySQL一样,是自动提交事务的。
可以基于关闭PostgreSQL的自动提交事务来进行操作。
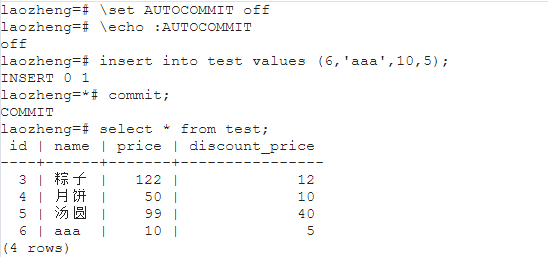
但是上述方式比较麻烦,传统的方式。
也可以根据命令处理一个事务:
- begin:开始事务
- commit:提交事务
- rollback:回滚事务
-- 开启事务
begin;
-- 操作
insert into test values (7,'bbb',12,5);
-- 提交事务
commit;
保存点
在PostgreSQL中,保存点(savepoint)用于在事务中创建中间状态,点允许在事务过程中设置临时的“检查点”,以便在必要时回滚事务的一部分。
比如项目中有一个大事务操作超时,回滚成本太高。针对大事务,可以拆分成几个部分,每个部分完成后,构建一个保存点,如果后面操作超时了,回滚到保存点,继续重试。
-- savepoint操作
-- 开启事务
begin;
-- 插入一条数据
insert into test values (8,'铃铛',55,11);
-- 添加一个保存点
savepoint ok1;
-- 再插入数据,比如出了一场
insert into test values (9,'大唐官府',66,22);
-- 回滚到之前的提交点
rollback to savepoint ok1;
-- 就可以开始重试操作,重试成功,commit,失败可以rollback;
commit;
PostgreSQL 并发
并发问题
在不考虑隔离性的前提下,事务的并发可能会出现的问题:
- 脏读:读到了其他事务未提交的数据。(必须避免这种情况)
- 不可重复读:同一事务中,多次查询同一数据,结果不一致,因为其他事务修改造成的。(一些业务中这种不可重复读不是问题)
- 幻读:同一事务中,在修改某个数据后,再次查询还是之前的数据,因为其他事务对数据进行了更新,这种现象为幻读。
针对这些并发问题,关系型数据库有一些事务的隔离级别,一般用4种。
- READ UNCOMMITTED:读未提交
- READ COMMITTED:读已提交,可以解决脏读(PGSQL默认隔离级别)
- REPEATABLE READ:可重复读,可以解决脏读和不可重复读(MySQL默认是这个隔离级别,PGSQL也提供了,但是设置为可重复读,效果还是串行化)
- SERIALIZABLE:串行化
PGSQL在老版本中,只有两个隔离级别,读已提交和串行化,在PGSQL中不存在脏读问题。
MVCC
PostgreSQL中,在事务的并发问题里,也是基于MVCC多版本并发控制去维护数据的一致性。详细内容见多版本并发控制MVCC
首先要清楚,为啥要有MVCC?
如果一个数据库,频繁的进行读写操作,为了保证安全,采用锁的机制。但是如果采用锁机制,如果一些事务在写数据,另外一个事务就无法读数据,会造成读写之间相互阻塞。 所以大多数的数据库都会采用一个机制 多版本并发控制 MVCC 来解决这个问题。
MVCC是一种并发控制的方法,它通过保存数据的多个版本来实现并发访问。在MVCC中,每个事务在开始时获取一个唯一的版本号,然后读取和修改数据时都会带上这个版本号。这样,每个事务只能看到自己的版本号小于或等于自己的数据版本,从而实现了并发访问。
PGSQL中,每张表都会自带两个字段
- xmin:给当前事务分配的数据版本。如果有其他事务做了写操作,并且提交事务了,就给xmin分配新的版本。
- xmax:当前事务没有存在新版本,xmax就是0。如果有其他事务做了写操作,未提交事务,将写操作的版本放到xmax中。提交事务后,xmax会分配到xmin中,然后xmax归0。
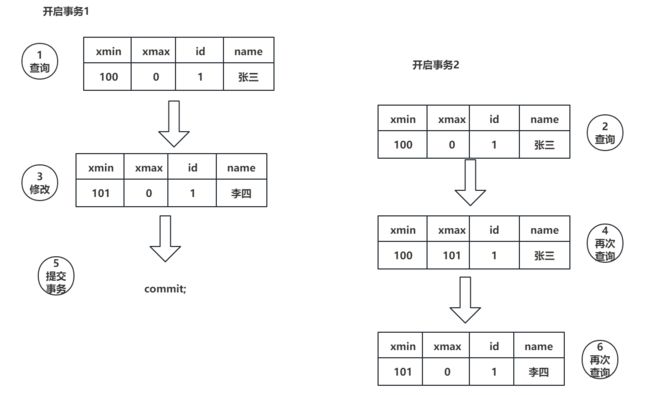
基于上图的操作查看效果
事务A
-- 左,事务A
--1、开启事务
begin;
--2、查询某一行数据, xmin = 630,xmax = 0
select xmin,xmax,* from test where id = 8;
--3、每次开启事务后,会分配一个事务ID 事务id=631
select txid_current();
--7、修改id为8的数据,然后在本事务中查询 xmin = 631, xmax = 0
update test set name = '铃铛' where id = 8;
select xmin,xmax,* from test where id = 8;
--9、提交事务
commit;
事务B
-- 右,事务B
--4、开启事务
begin;
--5、查询某一行数据, xmin = 630,xmax = 0
select xmin,xmax,* from test where id = 8;
--6、每次开启事务后,会分配一个事务ID 事务id=632
select txid_current();
--8、事务A修改完,事务B再查询 xmin = 630 xmax = 631
select xmin,xmax,* from test where id = 8;
--10、事务A提交后,事务B再查询 xmin = 631 xmax = 0
select xmin,xmax,* from test where id = 8;
PostgreSQL 锁机制
当然,PostgreSQL也支持表锁和行锁,来控制并发访问。PostgreSQL中主要有两种锁,一个表锁一个行锁。
表锁
表锁就是锁住整张表,也分为很多中模式,其中最核心的两个:
- ACCESS SHARE:共享锁(读锁),读读操作不阻塞,但是不允许出现写操作并行
- ACCESS EXCLUSIVE:互斥锁(写锁),无论什么操作进来,都阻塞。
具体的可以查看官网文档。
PostgreSQL中表锁的实现:

基于LOCK开启表锁,指定表的名字name,其次在MODE中指定锁的模式,NOWAIT可以指定是否在没有拿到锁时,一致等待。
-- 事务1
-- 基于互斥锁,锁住test表
-- 先开启事务
begin;
-- 基于默认的ACCESS EXCLUSIVE锁住test表
lock test in ACCESS SHARE mode;
-- 操作
select * from test;
-- 提交事务,锁释放
commit;
当事务1开启锁住当前表之后,如果使用默认的ACCESS EXCLUSIVE,其他连接操作表时,会直接阻塞住。
如果事务1是基于ACCESS SHARE共享锁时,其他事务是可以查询当前表的。
行锁
PostgreSQL的行锁和MySQL的基本是一模一样的,基于select for update就可以指定行锁。
MySQL中有一个概念,for update时,如果select的查询没有命中索引,可能会锁表。
PostgerSQL有个特点,for update时,如果select的查询没有命中索引,不一定会锁表,依然会实现行锁。
-- 先开启事务
begin;
-- 基于for update 锁住id为3的数据
select * from test where id = 3 for update;
update test set name = 'v1' where id = 3;
-- 提交事务,锁释放
commit;
其他的事务要锁住当前行,会阻塞住。
总结
事务、MVCC和锁是三个相互关联的概念,它们共同保证了数据库的一致性和并发性。
- 事务和MVCC是互相配合的,事务通过MVCC来实现并发控制,保证数据的一致性。
- 锁是事务实现并发控制的一种手段,通过加锁来保证数据的一致性。