线段树总结
线段树
一、线段树概念
线段树是一种二叉搜索树,常用于统计区间上的信息;
其每个节点存储的是一个区间的信息,每个节点包含三个元素:
- 区间左端点;
- 区间右端点;
- 区间内维护的信息;
二、线段树思想
线段树的思想就是将数组内所有元素看作是一个区间,将每个区间递归的进行分解,直到区间内只剩下一个元素为止;

三、线段树的性质
- 线段树的每个节点都代表一个区间;
- 线段树具有唯一的根节点,代表整个 [ 1 , n ] [1, n] [1,n] 区间的统计范围;
- 线段树的每一个叶节点都代表一个长度为 1 1 1 的区间 [ x , x ] [x, x] [x,x] ;
- 对于每个内部节点 [ l , r ] [l, r] [l,r] 它的左节点是 [ l , m i d ] [l, mid] [l,mid] ,右节点是 [ m i d + 1 , r ] [mid + 1, r] [mid+1,r] ,其中 m i d = ⌊ ( l + r ) 2 ⌋ mid = \lfloor \frac{(l + r)}{2} \rfloor mid=⌊2(l+r)⌋ ;
- 若线段树去掉最后一层,一定是一个满二叉树;
按照二叉树的标号方法对线段树进行编号,如图所示:
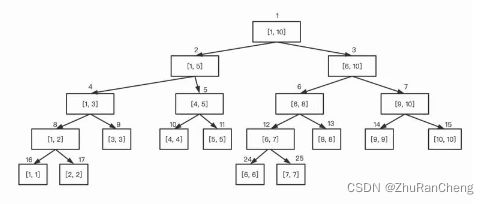
根节点编号为 1 1 1 ,编号为 x x x 的节点的左节点为 x ∗ 2 x * 2 x∗2 ,右节点为 x ∗ 2 + 1 x * 2 + 1 x∗2+1 ;
可以使用二叉树的顺序结构来存储来存储线段树,即将节点编号当作下表存储到数组中;
但可以发现树的最后一层节点在数组中存储的位置不是连续的,直接空出数组中保存的位置即可。理想情况下, n n n 个节点的满二叉树有 2 ∗ n − 1 2 * n - 1 2∗n−1 个节点。最后还有一层产生了空余,所以要保证数组长度要不小于 4 ∗ n 4 * n 4∗n 才不会越界;
四、线段的作用
线段树将区间递归分为多个小区间,可以用来解决区间问题;
其最基本的作用有:
- 维护区间信息;
- 合并区间信息;
- 对序列进行维护,支持查询与修改操作;
五、线段树建树
在建立线段树时,建树方式如下:
- 从根节点即存储 [ 1 , n ] [1, n] [1,n] 的情况时开始建立;
- 递归二分每个区间,将 [ l , r ] [l, r] [l,r] 区间分解为 [ l , m i d ] [l, mid] [l,mid] 和 [ m i d + 1 , r ] [mid + 1, r] [mid+1,r] 两个区间,其中 m i d = ( l + r ) / 2 mid = (l + r) / 2 mid=(l+r)/2 ;
- 当递归结束时,分解到的叶结点 [ i , i ] [i,i] [i,i] 存储 a i a_i ai 的值;
- 递归回溯时,从下往上更新信息,即 v a l ( l , r ) = v a l ( l , m i d ) + v a l ( m i d + 1 , r ) val(l, r) = val(l, mid) + val(mid + 1, r) val(l,r)=val(l,mid)+val(mid+1,r) ;
时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n) ;
代码如下:
int n, a[MAXN];
struct segment_tree {
int l, r, tot; // 建立存储线段树的的结构体,l表示左端点,r表示右端点,tot表示线段树维护的值
} t[4 * MAXN];
void build(int p, int l, int r) { // p 当前 [l, r] 的区间编号
t[p].l = l, t[p].r = r; // 存储当前区间的左右端点
if (l == r) {
t[p].tot = a[l]; // 当递归回到叶节点时在存储值
return;
}
int lc = p * 2, rc = p * 2 + 1, mid = (l + r) / 2;
build(lc, l, mid); // 递归建立左子树
build(rc, mid + 1, r); // 递归建立右子树
t[p].tot = t[lc].tot + t[rc].tot; // 左右子树建立完后,从下往上更新信息
return;
}
build(1, 1, n); // 调用入口
六、线段树的单点修改
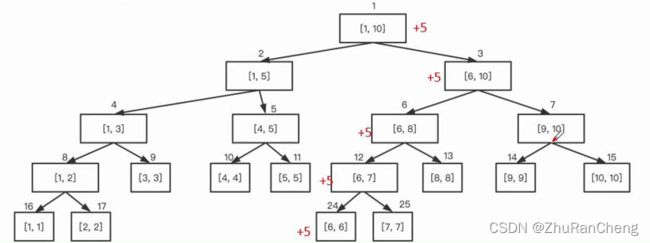
若要将 a i a_i ai 的值增加 x x x ,过程如下:
- 从根节点代表的区间 [ 1 , n ] [1, n] [1,n] 出发,递归找到存储区间 [ i , i ] [i, i] [i,i] 的叶节点。对 a [ i ] + = y a[i] += y a[i]+=y ;
- 再从下往上更新存储区间 [ i , i ] [i,i] [i,i] 的叶节点以及其到根节点路径上的所有区间信息;
如图所示:
时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n) ;
代码如下:
void add(int p, int i, int x) { // 将 a[i] 的值增加 x
if (t[p].l == t[p].r) {
t[p].tot += x; // 找到存储 [i, i] 信息的节点,跟新其的值
return;
}
int lc = p * 2, rc = p * 2 + 1, mid = (t[p].l + t[p].r) / 2;
if (i <= mid) add(lc, i, x); // 当 i 在当前点左子树时,更新左子树
else add(rc, i, x); // 当 i 在当前点右子树时,更新右子树
t[p].tot = t[lc].tot + t[rc].tot; // 从下往上更新信息
return;
}
add(1, i, x); // 调用入口
七、线段树的区间查询
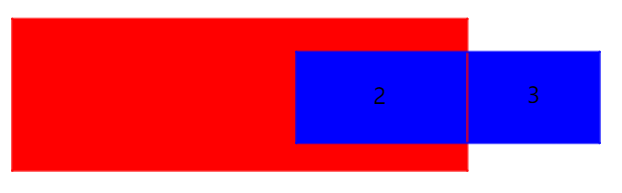
要查询在区间 [ l , r ] [l, r] [l,r] 上的和,则从根节点开始,递归时会遇到三种情况:
-
若当前的节点 p p p 所表示的节点区间 [ l , r ] [l, r] [l,r] 完全覆盖了查询空间,则立即回溯,并且该节点 t o t [ p ] tot[p] tot[p] 为查询答案的一部分;
如图:红色表示查询的区间 [ l , r ] [l, r] [l,r] ,蓝色表示节点 p p p 表示的区间;

-
若当前的节点 p p p 所表示的节点区间 [ l , r ] [l, r] [l,r] 只覆盖了一部分查询空间,则递归访问左右子节点:
- 若左子节点与查询部分 [ l , r ] [l,r] [l,r] 有重合部分,则递归访问左子节点;
- 若右子节点与查询部分 [ l , r ] [l,r] [l,r] 有重合部分,则递归访问右子节点;
如图:红色表示查询的区间 [ l , r ] [l, r] [l,r] ,蓝色表示节点 p p p 表示的区间;
时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n) ;
代码如下:
int query(int p, int l, int r) {
if (l <= t[p].l && t[p].r <= r) { // 情况1
return t[p].tot;
}
int lc = p * 2, rc = p * 2 + 1, mid = (t[p].l + t[p].r) / 2, sum = 0;
if (l <= mid) sum += query(lc, l, r); // 情况2
if (r > mid) sum += query(rc, l, r); // 情况3
return sum;
}
printf("%d\n", query(1, l, r)); // 调用出口
八、线段树的区间修改
在区间修改中,如果某个节点代表的区间被修改区间 [ l , r ] [l,r] [l,r] 完全覆盖,那么以该节点为根节点的整棵子树中的所有节点存储的信息都需要发生变化,若逐一进行更新,将使得一次区间修改指令的时间复杂度增加到 O ( n ) O(n) O(n) ;
所以如果再修改中发现某个节点 p p p 代表的区间 [ p l , p r ] [p_l, p_r] [pl,pr] 被修改区间 [ l , r ] [l,r] [l,r] 完全覆盖,并且逐一更新了子树 p p p 中的所有节点,但是在之后的查询指令中却没有用到 [ l , r ] [l, r] [l,r] 的子区间作为候选答案,那么更新 p p p 的整棵字数是无用的;
只需要在执行修改指令时,只修改到满足 l ≤ p l ≤ p r ≤ r l \leq p_l \leq p_r \leq r l≤pl≤pr≤r 的节点后停止递归修改,但在回溯之前型节点 p p p 增加一个标记,表示“该节点曾经被修改,但其子节点尚未被修改”。该标记的作用如下:
- 若多个修改指令都可以满足同一个节点 p p p , l ≤ p l ≤ p r ≤ r l \leq p_l \leq p_r \leq r l≤pl≤pr≤r 成立,则可以将多次修改影响值累积到 p p p 节点标记中;
- 若在后续多个指令中,节点 p p p 不能够满足 l ≤ p l ≤ p r ≤ r l \leq p_l \leq p_r \leq r l≤pl≤pr≤r ,需要从节点 p p p 乡下递归,再检查 p p p 是否有标记。若有,根据标记信息更新 p p p 的两个子节点,同时为 p p p 的两个子节点增加标记,然后清除 p p p 的标记;
所以,对任意节点的修改都延迟到“在后续操作中递归进入它的父节点时”在执行。这样,每条区间修改的时间复杂度降低到了 O ( l o g 2 n ) O(log_2n) O(log2n) 。这些标记则为“延迟标记”;
向下传递延迟标记:
void down(int p) {
if (t[p].target) { // 节点 p 有延迟标记
int lc = 2 * p, rc = 2 * p + 1;
t[lc].target += t[p].target; // 更新左子节点的信息
t[rc].target += t[p].target; // 更新右子节点的信息
t[lc].tot += (t[lc].r - t[lc].l + 1) * t[p].target; // 左左子节点打上延迟标记
t[rc].tot += (t[rc].r - t[rc].l + 1) * t[p].target; // 右子节点打上延迟标记
t[p].target = 0; // 清除 p 的标记
}
return ;
}
区间修改:
void add(int p, int l, int r, int x) {
if (l <= t[p].l && t[p].r <= r) { // 完全包含
t[p].tot += x * (t[p].r - t[p].l + 1); // 更新节点信息
t[p].target += x; // 更新延迟标记
return;
}
down(p); // 需要递归向下时就传递延迟标记
int lc = p * 2, rc = p * 2 + 1, mid = (t[p].l + t[p].r) / 2;
if (l <= mid) add(lc, l, r, x); // 当 i 在当前点左子树时,更新左子树
if (r > mid) add(rc, l, r, x); // 当 i 在当前点右子树时,更新右子树
t[p].tot = t[lc].tot + t[rc].tot; // 从下往上更新信息
return;
}
区间查询:
int query(int p, int l, int r) {
if (l <= t[p].l && t[p].r <= r) return t[p].tot; // 完全包含
down(p); // 需要递归向下时就传递延迟标记
int lc = p * 2, rc = p * 2 + 1, mid = (t[p].l + t[p].r) / 2, sum = 0;
if (l <= mid) sum += query(lc, l, r); // 左子节点有重叠
if (r > mid) sum += query(rc, l, r); // 右子节点有重叠
return sum;
}