基于VM与Hadoop的完全分布式安装
基于VM虚拟机的ubuntu18.04的Hadoop的完全分布式安装,所有的指令都是在超级用户下做的,其中完全分布式模式环境的配置需要在三台虚拟机上都做一次,本人也是第一次做,有很多不会的地方查了很多资料也走了很多弯路
文章目录
- 基于VM与Hadoop的完全分布式安装
-
- 完全分布式运行模式环境配置
- 配置JDK与Hadoop
- 集群配置
-
- 部署规划
- 配置核心文件
- 配置HDFS文件
- Yarn配置文件
- 配置Mapreduce文件
- 分发配置文件并查看分发情况
- 单点启动
- 集群启动
基于VM与Hadoop的完全分布式安装
完全分布式运行模式环境配置
这里是对三台进行配置,每一台机器都需要做
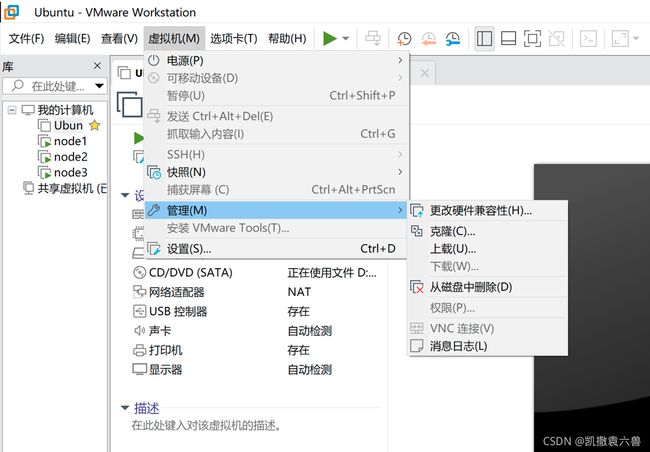
1 准备三台主机
准备三台主机直接在VM的虚拟机选项中的管理中直接全部克隆即可,我使用node1,2,3作为我的三个主机节点,在克隆以后会自动顺序增加ip地址
2.关闭防火墙,重启后生效
#查看防火墙状态
ufw status
#关闭防火墙
ufw disable
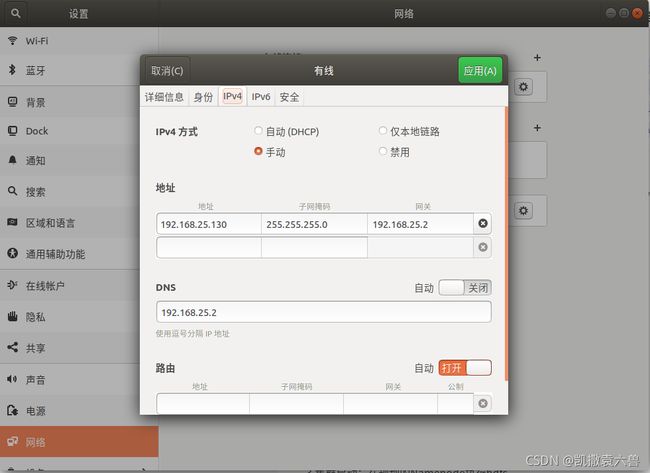
3.设置静态ip,重启后生效
#使用ifconifg查看ip与子网掩码
ifconifg
#使用nmcli dev show查看网关和DNS
nmcli dev show
在设置的网络中设置静态ip
4.更改主机名称,重启后生效
#编辑hostname文件
vim /etc/hostname
#查看主机名称
echo $HOSTNAME
5.配置ssh免密登陆,方便之后用xsync脚本进行集群分发
# 首先安装ssh服务
apt-get install openssh-server
#编辑/etc/hosts文件
vim /etc/hosts
# 将你的三台虚拟机的ip和名称加入到hosts文件中
127.0.0.1 localhost
# 127.0.1.1 kaiser-virtual-machine
#注释掉这一行
192.168.25.129 node1
192.168.25.130 node2
192.168.25.131 node3
#下面ipv6的内容保持不变
#编辑/etc/ssh/sshd_config文件
vim /etc/ssh/sshd_config
# 找到PermitRootLogin取消注释并改成yes,剩下的的保持不变
#LoginGraceTime 2m
PermitRootLogin yes
#StrictModes yes
#MaxAuthTries 6
#MaxSessions 10
# 重启ss服务
service ssh restart
#创建ssh公钥与私钥
ssh-keygen -t rsa
#对三台虚拟机传公钥,输入的密码是主机密码,忘了可以用passwd改一下
ssh-copy-id root@node1
ssh-copy-id root@node2
ssh-copy-id root@node3
#登陆node2虚拟机检验是否配置成功
ssh root@node2
#出现Welcome to Ubuntu 18.04.6 LTS (GNU/Linux 5.4.0-87-generic x86_64)等等没有erro的字应该就是成功的
#退出登陆
exit
6.编写集群分发脚本xsync
#编辑/usr/local/bin/xsync文件
vim /usr/local/bin/xsync
#编辑文件内容
#!/bin/bash
if [[ -x $(command -v rsync) ]]; then
echo yes > /dev/null
else
echo no rsync found!
exit 1
fi
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args!
exit;
fi
#2 获取文件名称
p1=$1
fname=$(basename $p1)
echo fname=$fname
#3 获取文件绝对路径
pdir=$(cd -P $(dirname $p1); pwd)
echo pdir=$pdir
#4 获取当前用户名称
user=$(whoami)
#5 循环,注意把这个里面的两个node改称你相应的主机名称
for((host=2; host<4; host++)); do
echo --- node$host ---
rsync -rvl $pdir/$fname $user@node$host:$pdir
done
#退出文件并进入文件夹更改权限
cd /usr/local/bin
chmod +x xsync
配置JDK与Hadoop
一台一台的配置的教程可以看我之前配置本地JDK与Hadoop的博客基于Windows下的Linux的Hadoop安装指南,即可以先配置一台本地的再克隆三个node,在这里我介绍另一种方法,使用分布式分发的方法解决JDK与Hadoop的配置,在node1主机中安装Hadoop并配置相应文件,同时用xsync同步文件到其他主机
#先将node1的JDK和Hadoop配置好,具体看之前的博客
#进入/opt文件夹,并使用xsync向剩下两个节点传JDK与Hadoop文件
cd /home/opt
#使用xsync传JDK与Hadoop文件夹
xsync jdk1.8.0_144
xsync hadoop-2.7.2
#使用xsync传送存放路径的.sh文件
cd home
cd /etc/profile.d/
xsync java.sh
xsync hadoop.sh
#然后再在每一台主机上source /etc/profile使环境变量生效
cd /home
source /etc/profile
#查看是否安装成功
java -version
hadoop
集群配置
部署规划

配置核心文件
1 .编辑core-site.xml文件
#编辑core-site.xml文件
vim core-site.xml
#加入下列内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/data/tmp</value>
</property>
配置HDFS文件
1 .编辑hadoop-env.sh文件,加入JAVA_HOME路径
#查看JAVA路径
echo $JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_144
#将JAVA_HOME这一栏取消注释并添加JAVA路径
2 .编辑hdfs-site.xml文件
#编辑hdfs-site.xml文件
vim hdfs-site.xml
#编辑内容如下
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50090</value>
</property>
Yarn配置文件
1.配置yarn-env.sh,增加JAVA路径
#将JAVA_HOME取消注释并增加路径
export JAVA_HOME=/opt/jdk1.8.0_144
2.配置yarn-site.xml文件
#编辑yarn-site.xml文件
vim yarn-site.xml
#增加以下内容
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcenamager.webapp.address</name>
<value>192.168.25.130:8088</value>
</property>
#第三个标签的标签中的ip换成自己node2的ip
配置Mapreduce文件
1.配置mapred-env.sh文件,增加JAVA路径
vim mapred-env.sh
#取消这一行的注释并增加JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_144
2.配置mapred-site.xml文件
#编辑mapred-site.xml文件
vim mapred-site.xml
#增加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
分发配置文件并查看分发情况
#在/opt/hadoop-2.7.2/etc文件夹中分发文件
xsync hadoop
#除了该节点以外的任意节点检查一下相关文件即可
单点启动
这里对每个node进行操作之前需要source etc/profile文件,否则jps无法运行
node1虚拟机如果克隆的是伪分布式的虚拟机,则需要在/opt/hadoop-2.7.2文件夹中删除data和logs文件夹,再格式化,如果不是则直接格式化就行
#删除两个文件夹
rm -rf logs/
rm -rf data/
#格式化
bin/hdfs namenode -format
#启动namenode
sbin/hadoop-daemon.sh start namenode
#启动datanode
sbin/hadoop-daemon.sh start datanode
node2和node3虚拟机如果克隆的是伪分布式的虚拟机,则需要在/opt/hadoop-2.7.2文件夹中删除data和logs文件夹,再格式化,如果不是则直接格式化就行
#删除两个文件夹
rm -rf logs/
rm -rf data/
#格式化
bin/hdfs namenode -format
#启动datanode
sbin/hadoop-daemon.sh start datanode
集群启动
1.配置slaves
#进入/opt/hadoop-2.7.2/etc/hadoop文件夹
#编辑slaves
node1
node2
node3
#注意不要增加额外的空行或者空格
2.同步slaves
xsync slaves
3.集群启动:在规划的Namenode执行hdfs
在node1,node2,node3如果之前启动过则需要关闭
#回到/opt/hadoop-2.7.2文件夹并关闭节点
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode
回到node1中启动集群
#回到/opt/hadoop-2.7.2并启动集群
sbin/start-dfs.sh
#node1出现以下内容
Starting namenodes on [node1]
node1: starting namenode, logging to /opt/hadoop-2.7.2/logs/hadoop-root-namenode-node1.out
node1: starting datanode, logging to /opt/hadoop-2.7.2/logs/hadoop-root-datanode-node1.out
node3: starting datanode, logging to /opt/hadoop-2.7.2/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to /opt/hadoop-2.7.2/logs/hadoop-root-datanode-node2.out
Starting secondary namenodes [node3]
node3: starting secondarynamenode, logging to /opt/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-node3.out
#在node3中还有一个secondarynamenode
4.集群启动:在规划的ResourceMan执行yarn
到node2节点运行start-yarn.sh
sbin/start-yarn.sh
#出现以下字样
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.2/logs/yarn-root-resourcemanager-node2.out
node3: starting nodemanager, logging to /opt/hadoop-2.7.2/logs/yarn-root-nodemanager-node3.out
node2: starting nodemanager, logging to /opt/hadoop-2.7.2/logs/yarn-root-nodemanager-node2.out
node1: starting nodemanager, logging to /opt/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
#说明都启动了nodemanager
5.集群启动检查及测试
经过上述步骤以后三个节点启动情况如下
node1:NameNode,NodeManager,DataNode,Jps
node2:ResourceManager,NodeManager,DataNode,Jps
node3:SecondaryNameNode,NodeManager,DataNode,Jps
登陆三个ui网址可以正常登陆
http://node1:50070/explorer.html#/
http://node2:8088/cluster
http://node3:50090/status.html