数据结构与算法(二)时间复杂度分析
一、前言
上篇文章我们自定义了动态数组,尤其是后面扩容,很多朋友会担心每次扩容都要进行for循环,是否会非常影响效率,那么这次我们就通过歇息并分析时间复杂度来分析扩容的效率问题。我们本章也只是对时间复杂度做一个简单的了解和分析
二、时间复杂度
我们经常会看到O(1),O(n),O(lgn),O(nlogn),O(n^2)去描述时间复杂度
- 大O描述的是算法的运行时间和输入数据之间的关系
什么是运行时间和输入数据之间的关系,我们可以看下面一段代码:
public static int sum(int[] sums){
int sum = 0;
for (int num : sums) {
sum += num;
}
return sum;
}
上面代码逻辑很简单,就是对一个数组里的数字求和,其中输入的数据就是sums这个int数组,通常呢我们将这个算法定义为O(n),这里的n是nums中的元素个数,而O(n)指的是算法的运行时间的多少是和nums中的元素个数成线性关系的。我们Nums元素个数越多,那么我们算法的执行时间会越慢一点。
- 为什么要用大O,叫作O(n)
忽略常数。例如上述方法我的实际时间公式其实为T=c1*n + c2,这样的表达式才是线性的,c1代表我算法的所有指令条数所需的时间,n就是元素个数,例如上面的方法,我要将数组里面的每一个数取出来,然后用sum和这些数相加,相加后还要把这个值赋值给sum,且这样的程序我要执行n次。我们把核心算法的指令执行条数称为C1,n个元素个数执行n次称为c1n,而c2代表除算法之外,例如我一开始int sum = 0我将0赋值给sum,还有我开辟int这样一个空间所需的时间,我们将这个和执行算法之外所用到的时间称为C2.
而为什么要忽略掉常数,如果我们要将c1,c2每次都仔细分析出来,一个是必要性不大,另一个是某些情况下也是不可能的。这是因为这些常数(指令所需的具体时间)其实和不用的语言,CPU,环境等多种因素影响。所以基于这个原因,我们很难准确判断出这个c1,c2具体是多少。正因为如此,我们在分析时间复杂度的时候是忽略掉这些常数的
①例如c1,c2均等于2,
T=2n+2,但是时间复杂度我们称为O(n)
②例如c1=2000,c2=10000
T=2000*n+10000,哪怕常数很大但是时间复杂度我们仍称为O(n)
③再例如c1=1,c2=0,
但是假设现在T=1*n*n + 0,哪怕常数很小,此时时间复杂度我们却称为O(n^2),运行时间的多少是和nums中的元素个数成指数关系的。宏观上我们认为第三个算法是要比第二个慢的,因为第三个是O(n^2).
可能很多人觉得这样不合理,假设对于②③,如果我的n=10.最终②花费的时间要比③多得多,实际上这也是符合事实的。如果我们说一个算法是O(n)的,另一个算法是O(n^2)的,并不代表我任意输入,前者都要快于后者,具体的确实要看n前面的常数,但是这个O的表示翻译为中文叫作渐进复杂度。它表示的是当n->无穷的情况这两个算法谁快谁慢。那这样的情况下②肯定是远远快于③的。
不过在实际工程中,有的时候我们是会利用对于n比较小的时候有可能高阶算法由于常数比较低反而会快于一个常数比较高的低阶算法,最典型的例子就是通过插入排序去取代优化对于比较小的数组的归并排序或者快排算法。通常性能可以优化10%~15%.核心原理利用的就是插入排序它的常数相较于快排或者归并排序要小的。
而如果出现类似T=2*n*n + 300n +10 这样的时间消耗,我们仍然认为它的时间复杂度是O(n^2)。这是因为n->无穷的时候,低阶项是可以忽略不计的。
三、分析动态数组相关操作的时间复杂度
那么上一节我们自己实现了一个动态数组,当时对扩容相关操作的效率问题埋了个伏笔,下面我们就对动态数组的相关操作的时间复杂度进行分析:
- 添加操作
addLast(e): 这个我们只需在数组末尾添加一个元素,这个是可以在常数时间内完成,所以时间复杂度是O(1)
addFirst(e):由于我在数组首部添加一个元素,我剩余的n个元素都得往后挪一个空间,所以时间复杂度是O(n)
add(index,e):当index=0时,时间复杂度相当于addFirst的O(n),当index=size的时候,时间复杂度相当于addLast的O(1),由于index=[0.size],严格计算需要一些概率论知识,因为index取到0-size范围中的每一个值概率都是相等的,就需要去计算时间复杂度的这个期望。但是这里我们不做复杂的计算,平均来看,我们的时间复杂度应该是O(n/2)=O(n)的。
所以整体来看,添加操作的时间复杂度是O(n),哪怕addLast()是O(1),因为通常我们观察时间复杂度通常观察的是最坏情况,而且加上如果数组满了的话,我们还需要进行resize(),对于resize()时间复杂度明显是O(n),所以综上我们认为添加操作时间复杂度就是O(n).
- 删除操作
那么删除操作本质上和添加操作是差不多的
removeLast(e):同addLst(e),时间复杂度为O(1)
removeFirst(e):同removeFirst(e),因为我剩余的每个元素需要往前挪,时间复杂度为O(n)
remove(index,e):同add(index,e),时间复杂度是O(n/2)=O(n),且同样也需要进行resize操作,时间复杂度为O(n),所以综上我们认为添加操作时间复杂度就是O(n).
- 查询操作
get(index):如果我知道Index是多少,直接取出即可,此时时间复杂度是O(1)
contains(e):如果不知道Index,就需要遍历寻找,此时时间复杂度为O(n)
find(e):同上,时间复杂度为O(n)
修改操作同查询操作。
所以综上,我们得出动态数组操作的时间复杂度:
- 增:O(n)
- 删:O(n)
- 改:已知索引O(1),未知索引O(n)
- 查:已知索引O(1),未知索引O(n)
所以这个结论也正应了学习数组一开始说的那句,使用数组最好是索引有语义的情况,因为我们如果知道具体的索引,我们就可以利用数组快速找到索引对应的元素。那么性能上就有非常强的优势。
但是还是遗留了一个问题,那就是增和删:
如果只对最后一个元素操作,按理说这两个时间复杂度都是O(1)级别的操作,可是我们还是将时间复杂度视为O(n),就是因为可能存在resize操作,这样看好像resize操作是一个性能很差,很耽误性能的操作。可实际上真是如此吗,实际上我们对resize进行最坏情况的时间复杂度分析是不合理的,我们后面会说到均摊时间复杂度分析,就会让大家知道resize()实际上性能并没有大家想象的那么糟糕。
四、resize()的时间复杂度分析
我们之前从最坏角度去分析对最后一个元素的增删操作,统一认为它的时间复杂度因为有resize()的影响应该为O(n),而不是O(1)。但是我们忽略了一个问题:我们不可能每次添加元素的时候都会触发resize操作。假设我们数组有10个空间,那么我得添加10次元素后才会触发一次resize操作。接着空间变为20,我们需要再添加10次元素然后resize一次,接着空间变为40,我们直接变成需要添加20次元素后才会触发一次resize操作,以此类推。换句话说,我们不可能每次添加元素的时候都会触发resize操作。因此我们通过最坏情况去分析resize多少是有些不合理的。
假设数组当前capacity = 8,并且每一次添加操作都使用addLast,即添加元素操作上我的时间复杂度都是O(1)的
那么在添加8次每次O(1)的时间复杂度的添加操作后,此时我添加第九个元素触发resize,将之前添加的8个元素放到新的数组中,此时耗费的时间为8+1。那么把上面的操作总结一下,就是9次addLast操作,触发resize,总共进行了17次基本操作。平均来看的话,每次addLast操作,进行了2次基本操作(17/9≈2)
即假设capacity = n,n+1次addLast,触发resize,总共进行2n+1次基本操作。平均来看的话,每次addLast操作,进行了2次基本操作(2n+1/(n+1)≈2),即我n+1次addLast才会触发一次resize,我把resize耗费的时间平摊给了n+1次addLast,得到了上述结论。addLast平均进行了2次基本操作,这样均摊计算,时间复杂度是O(1)的。
在这个例子里,这样均摊计算,比计算最坏情况有意义。这就是因为最坏情况不会每次都出现。
而我们这样计算复杂度的行为称为均摊复杂度(amortized time complexity)
resize O(n)
addLast的均摊复杂度为O(1)
同理,我们看removeLast操作,均摊复杂度也为O(1)
五、复杂度震荡
我们之前分析addLast和removeLast操作的均摊复杂度都为O(1)
但是当我们同时看addLast和removeLast操作:
比如我有一个数组,现在是满的,此时调用addLast触发扩容resize,resize过程的时间复杂度为O(n),而调用完addLast后紧接着调用removeLast(),此时size=capacity/2,会触发缩容resize,此时resize过程的时间复杂度仍为O(n)。以此类推,假设我一直重复addLast和removeLast的操作,其实会频繁触发扩容这个时间复杂度为O(n)的操作。之前我们说过addLast和removeLast都是要调用n次后触发resize(),而不会每次都触发,但是现在这个场景每一次addLast和removeLast操作都会耗费O(n)的时间复杂度,这种情况称为复杂度震荡。
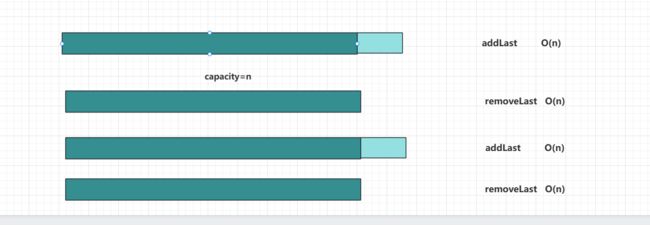
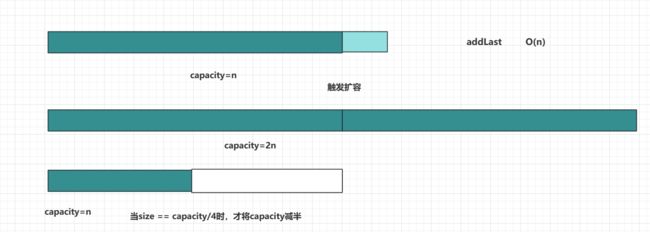
出现问题的原因:removeLast是resize过于着急(Eager)
解决方案:Lazy
假设一开始现在有一个已经装满元素的数组,现在addLast操作导致扩容,capacity从n变为2n,此时假设触发了removeLast,我可以再等等,不立即缩容,而是看后面的操作是否仍然会移除元素,直到size变为容量的1/4时,这时我再触发缩容,将capacity减半。
有时候更“懒”,其实是在改善算法性能。当然这个不代表代码量更少或者说代码更容易编写。后续在线段树的学习中大家就能领会了。那么现在我们将我们这种思想体现在我们动态数组的代码中:
//从数组中删除Index位置的元素,返回删除的元素
public T remove(int index) {
//如果size容量,则报错
//如果index比size还要大(中间会出现非法元素)或者index<0,也需报错
if (index < 0 || index >= size) {
throw new IllegalArgumentException("add failed,index should >= 0 or index < size");
}
T result = array[index];
for (int i = index + 1; i < size; i++) {
array[i - 1] = array[i];
}
size--;
//如果发现size=当前数组容量1/4,防止复杂度震荡,则将数组缩容至原来一半
if (size == array.length / 4) {
resize(array.length / 2);
}
return result;
}
当然我们现在的remove其实是有Bug的,当我们的数组长度缩容的越来越小的时候,小到array.length = 1,此时array.length / 2 = 0 ,那回到我们resize(),我们是不能new一个容量为0的数组的。这样就出现了BUG,所以我们的缩容的条件还需要优化,因为其实当数组过于小的时候,已经没有缩容的必要了,所以我们可以这样改写:
if (size == array.length / 4 && array.length / 2 != 0) {
resize(array.length / 2);
}