MySQL优化第二篇
MySQL优化第二篇
-
- 性能分析
- 小表驱动大表
-
- 慢查询日志
- 日志分析工具mysqldumpslow
- Show Profile进行SQL分析(重中之重)
七种JOIN
1、inner join :可以简写为join,表示的是交集,也就是两张表的共同数据
sql语句:select * from tbl_emp e inner join tbl_dept d on e.deptId=d.id

2、left join (左外连接):从集合上看就是A 、B 的交集加上A的私有,即左表的所有数据加上 左右表中相交的数据
sql 语句:select * from tbl_emp e left join tbl_dept d on e.deptId=d.id
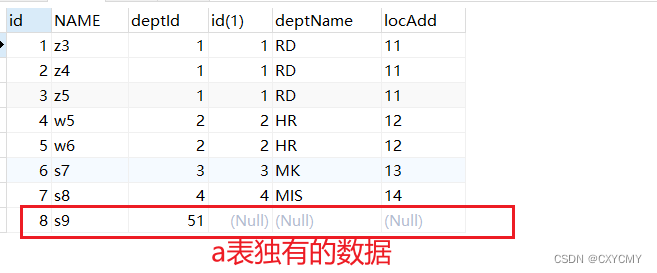
前七条共有数据;第八条a表独有数据,b表补null
3、right join(右外连接,全B):前七条共有数据;第八条b表独有数据,a表补null
4、左join独A:就是A表独有的部分,在left join的基础上加上where条件
sql语句:select * from tbl_emp e left join tbl_dept d on e.deptId=d.id where d.id is null

5、右join独B:就是B表的独有部分,同理可知在right join的基础上加上where条件
6、full join (全外连接):MySQL不支持使用full join 如果想要实现全A+B可以使用union去重中间部分(union关键字可以合并 并且 去重)
sql语句:
select * from tbl_emp a left join tbl_dept b on a.deptId=b.id
union
select * from tbl_emp a right join tbl_dept b on a.deptId=b.id

7、A、B各自独有集合
select * from tbl_emp a left join tbl_dept b on a.deptId=b.id where b.id is null
union
select * from tbl_emp a right join tbl_dept b on a.deptId=b.id where a.deptId is null

性能分析
MySQL Query Optimizer(查询优化器)[ˈkwɪəri] [ˈɒptɪmaɪzə]
Mysql中专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划(他认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
当客户端向MySQL请求一条Query,命令解析器模块完成请求分类,区别出是SELECT并转发给MySQL Query Optimizer时,MySQL Query Optimizer首先会对整条Query进行优化,处理掉一些常量表达式的预算直接换算成常量值。并对Query中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等。然后分析Query 中的 Hint信息(如果有),看显示Hint信息是否可以完全确定该Query的执行计划。如果没有Hint 或Hint信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据Query进行写相应的计算分析,然后再得出最后的执行计划
小表驱动大表
exists语法:SELECT * FROM table WHERE EXISTS (subquery)
该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE或FALSE)来决定主查询的数据结果是否得以保留
优化原则:
小表驱动大表,即小的数据集驱动大的数据集
就比如大表是A 小表是B
1、当B表的数据集必须小于A表的数据集的时候,用in会比用exists好
2、当A表的数据集是小于B表的数据集的时候,用exists会比较好
重点:A表与B表的id字段应该建立索引
in和exists的用法
sql语句:
select * from tbl_emp e where e.deptId in (select id from tbl_dept d)
select * from tbl_emp e where EXISTS (select 1 from tbl_dept d where e.deptId=d.id)

慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,**具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上的语句。由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql 结合之前explain进行全面分析
操作说明:
默认情况下,MySQL数据库没有开启慢查询日速,需要我们手动来设置这个参数。
但是开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件。
查看是否开启以及如何开启慢查询:
默认: SHOW VARIABLES LIKE ‘%slow_query_log%’;
开启:set global slow_query_log=1;,只对当前数据库生效,如果MySQL重启后则会失效
永久开启:就必须修改配置文件my.cnf文件,将下面两行的数据配置进文件中
slow_query_log =1
slow_query_log_file=/var/lib/mysqatguigu-slow.log
重点:关于慢查询的参数slow_query_log_file,它指定慢查询日志文件的存放路径,系统默认会给一个缺省的文件host_name-slow.log(如果没有指定参数slow_query_log_file的话)
查看慢sql阈值时间:即查看long_query_time的值。
查看命令是:SHOW VARIABLES LIKE ‘long_query_time%’;
修改命令是:set global long_query_time=3;
查询当前有多少慢查询sql:show global status like ‘%Slow_queries%’
重点:如果显示修改无效的话可以重开一个连接,或者换一个语句:show global variables like ‘long_query_time’;
日志分析工具mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,是非常复杂且麻烦的,MySQL提供了日志分析工具mysqldumpslow。
查看mysqldumpslow的帮助信息,mysqldumpslow --help。
常用mysqldumpslow帮助信息:
s是表示按照何种方式排序
c访问次数
l锁定时间
r返回记录
t查询时间
al平均锁定时间
ar平均返回记录数
at平均查询时间
t即为返回前面多少条的数据
g后边搭配一个正则匹配模式,大小写不敏感的
常用举例:
得到返回记录集最多的10个SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
得到访问次数最多的10个SQL:
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
得到按照时间排序的前10条里面含有左连接的查询语句:
mysqldumpslow -s t -t 10 -g “left join” /var/lib/mysql/atguigu-slow.log
另外建议在使用这些命令时结合│和more 使用,否则有可能出现爆屏情况:
mysqldumpslow -s r-t 10 /ar/lib/mysql/atguigu-slow.log | more
Show Profile进行SQL分析(重中之重)
Show Profile是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量
使用步骤:
1、查看当前mysql是否支持:**show variables like 'profiling;**或者 show variables like ‘profiling %’;
2、开启这个功能(因为默认是关闭的,所以需要手动开启):set profiling=on;
3、运行SQL
4、查看结果:show profiles;
5、诊断SQL,show profile cpu,block io for query ID号;(ID号为第4步Query_ID列中数字)
参数信息说明:
ALL显示所有的开销信息。
BLOCK IO显示块lO相关开销。
**CONTEXT SWITCHES **上下文切换相关开销。
CPU显示CPU相关开销信息。
IPC显示发送和接收相关开销信息。
MEMORY显示内存相关开销信息。
PAGE FAULTS显示页面错误相关开销信息。
SOURCE显示和Source_function,Source_file,Source_line相关的开销信息。
SWAPS显示交换次数相关开销的信息。
Status列显示结果表示严重问题的有
- converting HEAP to MyISAM查询结果太大,内存都不够用了往磁盘上搬了。
- Creating tmp table创建临时表,拷贝数据到临时表,用完再删除
- Copying to tmp table on disk把内存中临时表复制到磁盘,危险!
- locked锁了