详解kafka中的消息日志文件:Topic消息分类、partition分区、segment分段、offset偏移量索引文件

一、Kafka简介
Kafka是一种高吞吐量的基于zookeeper协调的以集群的方式运行的分布式发布订阅消息系统,支持分区(partition)、多副本(replica),具有非常好的负载均衡能力和处理性能、容错能力。Kafka采用发布/订阅模型,消息生产者将消息发送到Kafka的消息中心(broker)中,然后消费者从中心中读取消息。其逻辑架构请见下图所示:
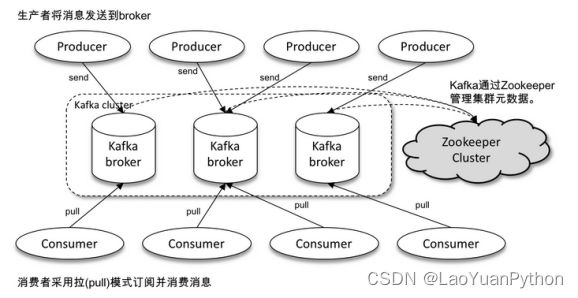
Broker是 Kafka集群中的服务器节点,每个 Broker 都是一个独立的服务器, 接收来自生产者的消息,并将消息存储在消息队列中。同时,它还处理来自消费者的请求,并将消息发送回消费者。Broker仅仅对消息进行存储和对注册到系统的Consumer进行通知。Consumer则根据监听和配置主动从broker拉取消息。
ZooKeeper 被用来管理集群的配置、状态和元数据信息等,以保证分布式消息系统的正常运行。
二、Kafka中的消息日志文件
1.消息的分类
Kafka的数据单元称为消息,可以把消息看成是数据库里的一个“数据行”或一条“记录”。Kafka将消息按topic(主题)进行分类组织和管理,各个主题之间相互独立,互不影响。topic由业务系统指定,用以区分消息的类型,生产者和消费者通过topic进行关联对接。Producer 生产的消息放入一个topic中,由指定的Consumer或Consumer Group对该topic的消息进行消费。
2.消息的分区存储
物理上,不同Topic的消息存储分开,每个Topic的消息可划分多个partition的逻辑分区存储,每个分区可以理解为一个独立的消息日志,只能存储同一个topic的消息,是这个topic的最细粒度逻辑存储。在kafka中,每个partition对应一个独立的文件目录,文件目录命名规则为:topic名称+分区序号。
同一个topic下的消息由生产者提交时,kafka会根据分区策略(如范围分配、循环分配、粘性分配)将消息分配到该topic的对应partition,同一个Topic下的不同的partition消息是完全不同的。
3.消息的身份标识offset
在单个partition中,存储的消息是有序的,每个消息被添加至分区时,以分区为单位顺序递增分配唯一offset来区别分区中每条不同的消息,offset也叫偏移量,是有序的数字,相当于消息的id,长度20位,不够20位的补0,它是消息在此分区中的唯一编号,Kafka保证在同一个分区内的消息是有序的,但是同一个topic中不同partition中消息是无序的。
4.消息日志的分段
为了防止消息日志不断追加使得文件过大,导致检索效率变低,一个Partiton又被划分多个Segment来组织数据,在磁盘上,每个Segment由一个存储消息的消息日志log文件和两个索引文件组成,每个日志文件包含一个或多个消息。每个日志文件的命名规则为"{baseOffset}.log",其中baseOffset是该日志文件中第一条消息的offset。
在一个Segment里面,消息日志是追加写人的,如果满足日志文件或索引文件超过一定大小或者当前时间-文件创建时间大于规定的时间间隔(以上条件都是参数设置的),就会切分日志文件和索引文件,产生一个新的Segment,新的Segment用当前最新的Offset作为名称。第一个Segment存储的第一条消息的起始序号为0,因此文件名为20位长度的0来命名。
5.Topic、partition、Segment之间的关系
下面是Topic、partition、Segment以及日志文件之间的逻辑关系图:

上图中,partition0的Segment0存储的第一条消息的offset为0,最后一条消息的offset为123456788,第二个segment的初始消息的offset为123456789,最后一个segment的初始消息的offset为xxxxxxxxxxxxxxxxxxxx。
三、Kafka中消息日志文件的索引文件
1.Kafka索引文件
Kafka的日志文件通常非常庞大,每条消息不是固定长度的,读取和处理可能会耗费大量时间和资源,为了提升读取和处理速度,Kafka为每个日志文件创建了两个索引文件,分别是偏移量索引文件(文件后缀".index")和时间戳索引文件(文件后缀".timeindex")。这两种索引文件都是稀疏索引,并不保证每个消息在索引文件中都有对应的索引项,因此可以大幅减少索引文件大小,从而实现索引文件的缓存加载,提升查询速度。
不同版本的Kafka的日志文件和索引文件有些不同,但记录的基本信息相似,日志文件和索引文件在不同版本中的实现机制相差不多。
2.偏移量索引文件
".index"偏移量索引文件是用来建立消息偏移量offset到消息在日志文件存储的物理地址之间的映射关系,当写入的消息长度超过一定量(由参数指定)时,偏移量索引文件就会增加一个偏移量索引项,该索引项包括该消息的offset以及其在物理文件中的位置。
由于日志文件名前缀为存储消息的baseoffset,当消费者想要读取消息时,先获取partition中的日志文件名列表顺序排序,根据消息的Offset(假设为x)使用二分法找到对应的日志文件,找到对应的日志文件之后,可以在对应偏移索引文件中通过二分查找来快速定位不大于x的最大索引条目项(假设其offset为y),并得到y在日志数据文件中存放的位置p,从p开始顺序扫描日志文件直到找到offset为x的那条消息。
3.时间戳索引文件
".timeindex"文件存储了消息的时间戳与消息的offset偏移量之间的映射关系,它根据时间戳将消息分片,并记录每片中最后一条消息的时间戳和对应的offset偏移量,用于按照时间顺序进行消息的快速查找。当 Kafka 写入的消息长度超过一定量(由参数指定)或新消息的时间戳和上一个索引条目的时间戳超过一定时长(参数指定),时间戳索引文件就会增加一个时间戳索引项。
当需要查询指定时间戳的日志消息时,使用二分法先找到时间戳索引文件中不大于目标时间戳的最大索引项x,得到该索引项对应的偏移量y,再根据y查询偏移量索引文件去读取消息所在的日志文件位置p。
4.索引文件小结
kafka同一个partition中消息的offset是按序递增的,出于提高性能考虑,同一个partition中的日志文件被拆成多个segment,每个segment保存一定量的消息数据,且每个segment都有偏移量索引文件和时间戳索引文件,这两类索引文件都是系数索引。
偏移量索引文件存放消息的offset和实际存储文件位置的映射关系,用于按消息的offset访问消息时使用,时间戳索引文件存放时间戳和偏移量的映射关系,用于按时间访问消息时使用,时间戳索引需要结合偏移量索引才能真正去访问数据。
由于索引文件是稀疏索引,通过索引绝大部分情况下只能找到消息数据的大致位置,最终需要从大致位置开始顺序读取消息才能找到要找的消息。由于消息offset递增并顺序写入日志文件、消息日志分区并分段、索引文件小可以缓存,因此这种索引机制整体效率挺高。
五、小结
本文详细介绍了kafka的消息日志文件的逻辑概念、物理存储分区、日志文件分段以及索引文件的概念以及相关关系,并详细介绍了偏移量索引文件和时间戳索引文件的逻辑结构及索引机制。有利于了解opic消息分类、partition分区、segment分段、offset偏移量索引文件等相关概念。
六、参考资料
- kafka中topic、partition、broker、consumerGroup、consumer之间的关系、区别及存在意义
- kafka是如何通过offset定位一条消息的?
- kafka 文件存储 消息同步机制
- 如何解读 Kafka 的索引机制
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
关于老猿的付费专栏
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_9607725.html 使用PyQt开发图形界面Python应用》专门介绍基于Python的PyQt图形界面开发基础教程,对应文章目录为《 https://blog.csdn.net/LaoYuanPython/article/details/107580932 使用PyQt开发图形界面Python应用专栏目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10232926.html moviepy音视频开发专栏 )详细介绍moviepy音视频剪辑合成处理的类相关方法及使用相关方法进行相关剪辑合成场景的处理,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/107574583 moviepy音视频开发专栏文章目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10581071.html OpenCV-Python初学者疑难问题集》为《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的伴生专栏,是笔者对OpenCV-Python图形图像处理学习中遇到的一些问题个人感悟的整合,相关资料基本上都是老猿反复研究的成果,有助于OpenCV-Python初学者比较深入地理解OpenCV,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/109713407 OpenCV-Python初学者疑难问题集专栏目录 》
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10762553.html Python爬虫入门 》站在一个互联网前端开发小白的角度介绍爬虫开发应知应会内容,包括爬虫入门的基础知识,以及爬取CSDN文章信息、博主信息、给文章点赞、评论等实战内容。
前两个专栏都适合有一定Python基础但无相关知识的小白读者学习,第三个专栏请大家结合《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的学习使用。
对于缺乏Python基础的同仁,可以通过老猿的免费专栏《https://blog.csdn.net/laoyuanpython/category_9831699.html 专栏:Python基础教程目录)从零开始学习Python。
如果有兴趣也愿意支持老猿的读者,欢迎购买付费专栏。