elasticsearch 基本查询语法
elasticsearch 基本查询语法
- 执行查询的几种方式
- 查询语法
-
- 精确查询-匹配一个值(=):term
- 精确查询-匹配多个值(in):terms
- 一个条件匹配多个值(包含):match
- 一个条件匹配一个值(包含):match_phrase
- 多条件查询(各条件关系and):bool must
- 多条件查询(各条件关系or):bool should
- 多条件查询(各条件关系and,取反):bool must_not
- 查询某个字段不存在
- bool查询中的must,must_not,shoud混合使用:
- 前缀匹配:match_bool_prefix
- nested对象查询: 要用到nested和path(指明要查的nested对象)
- date范围查询:
- 聚合查询:相当于SQL中的group by
- 字段排序:sort,对_score默认是desc,其他字段默认是asc
- 多个字段排序:sort后面跟方括号
- nested对象排序:sort
- 设置返回的字段:_source 返回的字段,默认返回整个文档
- 设置分页
- "profile": "true" :查看执行的查询条件
执行查询的几种方式
- 方法一:使用curl命令
curl -i -X‘ :// : / ? ’ -d ‘’
i:表示显示http投
VERB:HTTP方法(GET, POST, PUT, HEAD, DELETE)
eg:
curl -XGET 'http://localhost:9200/_search ‘-d’
{“query”:{“term”:{“search_file”:“value”}}}
- 方法二:使用elasticsearch-head执行,如图所示

- 方法三:使用接口测试工具-postman/fiddler/jmeter等都可以
查询语法
以下语法都是基于elasticsearch 7.5.0版本
精确查询-匹配一个值(=):term
eg:查询search_file字段值是value的数据
{
"query":{
"term":{
"search_file":"value"
}
}
}
精确查询-匹配多个值(in):terms
eg:查询search_file的值是value1、value2的数据
{
"query":{
"term":{
"search_file":[
"value1",
"value2"
]
}
}
}
一个条件匹配多个值(包含):match
eg:返回了所有在 address 中包含“四川省” 或 “成都市” 的数据
{
"query":{
"match":{
"address":"四川省 成都市"
}
}
}
注意:若不能匹配出包含四川省或成都市的结果,那么查询的这个字段类型应该是不支持分词
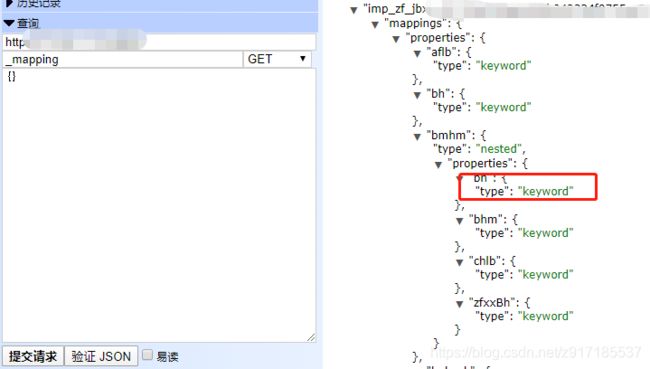
验证查询字段的类型:使用_mapping命令,可以查看字段类型,如图所示,如果是keyword类型是不支持分词的(目前只知道keyword、Numeric、date类型的不能分词)
一个条件匹配一个值(包含):match_phrase
eg:返回了所有在 address 中包含“四川省 成都市” 的数据
{
"query":{
"match_phrase":{
"address":"四川省 成都市"
}
}
}
多条件查询(各条件关系and):bool must
eg:返回了所有在 address 中包含了 “四川省"和 name值是"成都市” 的数据
{
"query":{
"bool":{
"must":[
{
"match":{
"address":"四川省"
}
},
{
"term":{
"name":"成都市"
}
}
]
}
}
}
多条件查询(各条件关系or):bool should
eg:返回了所有在 address 中包含了 “四川省"或"成都市” 的数据
{
"query":{
"bool":{
"should":[
{
"match":{
"address":"四川省"
}
},
{
"match":{
"address":"成都市"
}
}
]
}
}
}

多条件查询(各条件关系and,取反):bool must_not
eg:
所有在 address 中既不包含 “四川省” 也不包含 “成都市” 的数据
{
"query":{
"bool":{
"must_not":[
{
"match":{
"address":"四川省"
}
},
{
"match":{
"address":"成都市"
}
}
]
}
}
}
查询某个字段不存在
eg:查询不存在jsrq这个字段
{
"query":{
"bool":{
"must_not":{
"exists":{
"field":"jsrq",
"boost":1
}
}
}
}
}
{
"query":{
"bool":{
"must_not":{
"exists":{
"field":"jsrq",
"boost":1.0
}
}
}
}
}
bool查询中的must,must_not,shoud混合使用:
eg: age 为 40 但是 state 不为 ID 的账户
{
"query":{
"bool":{
"must":[
{
"match":{
"age":"40"
}
}
],
"must_not":[
{
"match":{
"state":"ID"
}
}
]
}
}
}
前缀匹配:match_bool_prefix
eg:匹配name是四川省开头的数据,结合bool 查询
{
"query":{
"bool":{
"must":[
{
"match_bool_prefix":{
"name":{
"query":"成都市"
}
}
}
]
}
}
}
nested对象查询: 要用到nested和path(指明要查的nested对象)
eg:查询jxjsqk(nested对象)中的clzt=3,spjg=1的数据,
{
"query": {
"nested" : {
"path" : "jxjsqk",
"query" : {
"bool" : {
"must" : [
{ "term" : {"jxjsqk.clzt" : "3"} },
{ "match" : {"jxjsqk.spjg" : "1"} }
]
}
}
}
}
}
date范围查询:
eg:查询jxjsqk(nested对象)中的clzt=3,spjg=1,ccdrq大于等于2020-01-01,小于等于2020-12-03的数据
gte:大于等于
gt:大于
lte:小于等于
lt:小于
{
"query": {
"nested" : {
"path" : "jxjsqk",
"query" : {
"bool" : {
"must" : [
{ "term" : {"jxjsqk.clzt" : "3"} },
{ "match" : {"jxjsqk.spjg" : "1"} },
{ "range" : {"jxjsqk.ccdrq" : {"gte":"2020-01-01","lte":"2020-12-03"}
#{"gte":"2020-01-01","lte":"2020-12-03"} 也可以写成{"from": "2020-01-01","to": "2020-12-03"}
]
}
}
}
}
}
聚合查询:相当于SQL中的group by
eg:对查询结果,通过xb字段分组
{
"query":{},
"size":0,
"aggs":{
"group_by_xb":{
"terms":{
"field":"xb"
}
}
}
}
输出结果(仅摘取了分组部分的结果):
{
"aggregations": {
"group_by_xb": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "1",
"doc_count": 33
},
{
"key": "2",
"doc_count": 3
}
]
}
}
}
字段排序:sort,对_score默认是desc,其他字段默认是asc
eg: 将id字段值为123的查询结果,按字段csrq的升序排
{
"query":{
"term":{
"id":"123"
}
},
"sort":{
"csrq":"asc"
}
}
或者下面这种写法
{
"query":{
"term":{
"id":"123"
}
},
"sort":{
"csrq":{
"order":"asc"
}
}
}
多个字段排序:sort后面跟方括号
eg:查询zybz字段10开头的,并且xb字段为1,将查询结果按csrq、bh升序排
{
"query":{
"bool":{
"must":[
{
"match_bool_prefix":{
"zybz":{
"query":"10"
}
}
},
{
"term":{
"xb":"1"
}
}
]
}
},
"sort":[
{
"csrq":{
"order":"asc"
}
},
"bh"
]
}
nested对象排序:sort
nested_path 定义要排序的嵌套对象,–必须
nested_filter 查询结果,中再过滤,-非必须
eg:查询zybz字段10开头的,并且xb字段为1,将查询结果按xfbd中的的pcah字段进行排序,并且再使用xfdb中的变dbhxz进行过滤
{
"query":{
"bool":{
"must":[
{
"match_bool_prefix":{
"zybz":{
"query":"10"
}
}
},
{
"term":{
"xb":"1"
}
}
]
}
},
"sort":[
{
"xfbd.pcah":{
"nested_path":"xfbd",
"nested_filter":{
"term":{
"xfbd.bdhxz":"6"
}
}
}
}
]
}
设置返回的字段:_source 返回的字段,默认返回整个文档
eg:查询结果中,返回csrq,name,dw字段的内容
{
"query":{
"term":{
"id":"123"
}
},
"_source":[
"csrq",
"name",
"dw"
]
}
设置分页
添加from 和 size参数,from默认值是0,设置返回的开始编号,size默认值是10,设置返回的条数,如果设置为0,则不返回_source中的内容
eg:返回查询结果中的第0-6条的数据
{
"from":0,
"size":10,
"query":{
"term":{
"id":"123"
}
}
}
“profile”: “true” :查看执行的查询条件
学习文档:http://doc.codingdict.com/elasticsearch/100/