kafka 消费者的消费策略以及再平衡1
一kafka 再平衡
1.1 kafka的再平衡
Kafka的再平衡是consumer所消费的topic发生变化时,topic上的分区再次分配的情况。
默认策略是 Range + CooperativeSticky 。 Kafka 可以同时使用 多个分区分配策略。
1.2 kafka触发再平衡的情况
1.consumer group中的新增或删除某个consumer,导致其所消费的分区需要分配到组内其他的consumer上;
2.consumer订阅的topic发生变化,比如订阅的topic采用的是正则表达式的形式,如test-*此时如果有一个新建了一个topic test-user,那么这个topic的所有分区也是会自动分配给当前的consumer的,此时就会发生再平衡;
3.consumer所订阅的topic发生了新增分区的行为,那么新增的分区就会分配给当前的consumer,此时就会触发再平衡。
1.3 kafka触发再平衡的策略
1.Round Robin:会采用轮询的方式将当前所有的分区依次分配给所有的consumer;
2.Range:首先会计算每个consumer可以消费的分区个数,然后按照顺序将指定个数范围的分区分配给各个consumer;
3.Sticky:这种分区策略是最新版本中新增的一种策略,其主要实现了两个目的:
将现有的分区尽可能均衡的分配给各个consumer,存在此目的的原因在于Round Robin和Range分配策略实际上都会导致某几个consumer承载过多的分区,从而导致消费压力不均衡;如果发生再平衡,那么重新分配之后在前一点的基础上会尽力保证当前未宕机的consumer所消费的分区不会被分配给其他的consumer上;
1.4 Round Robin策略
其主要采用的是一种轮询的方式分配所有的分区。轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将partition分配给各个consumer,如果当前的consumer没有订阅当前的partition,那么就会轮询下一个consumer,直至最终将所有的分区都分配完毕。
假设假如现在有 7 个分区, 3 个消费者,排序后的分区将会 是0,1,2,3,4,5,6;消费者为c1,c2,c3
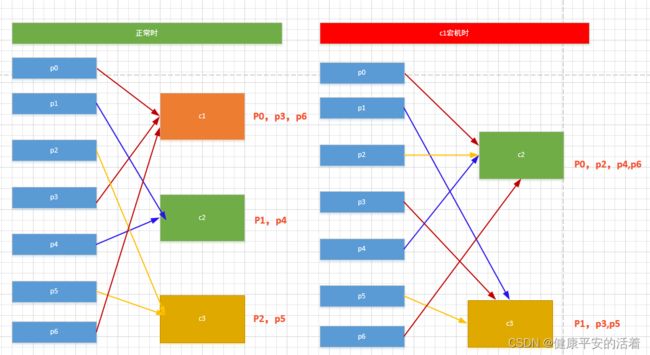
缺点:
轮询的方式会导致每个consumer所承载的分区数量不一致,从而导致各个consumer压力不均一。
1.5 Range策略
Range策略就是,统计出分区数/消费者数量,得出的结果就是每个分区的平均数,余数再平均分给前面几个消费者。
假设假如现在有 7 个分区, 3 个消费者,排序后的分区将会 是0,1,2,3,4,5,6;消费者为c1,c2,c3

缺点:这种方式从计算原理上就会导致排序在前面的consumer分配到更多的分区,从而导致各个consumer的压力不均衡。
1.6 Sticky策略
可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,consumer尽量保持原有分配的分区不变化。在此基础上进行新增一些分区。
假设假如现在有 7 个分区, 3 个消费者,排序后的分区将会 是0,1,2,3,4,5,6;消费者为c1,c2,c3
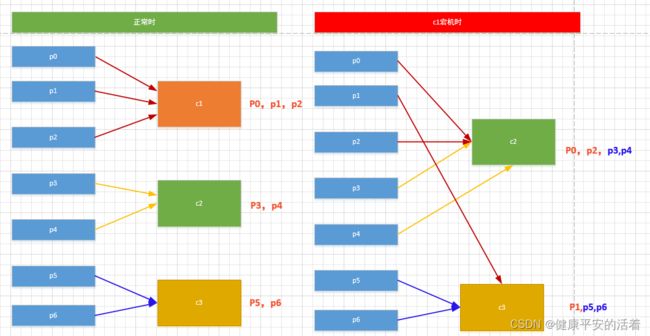
结论:各个分区是均匀的分配到各个consumer的,并且还保证了当前consumer已经消费的分区是不会分配到其他的consumer上的。与Round Robin进行对比,可以很明显的发现,Sticky重分配策略分配得更加均匀一些。
https://mp.weixin.qq.com/s?__biz=MzI2NTkwOTgxMw==&mid=2247483653&idx=1&sn=e0df814f7818414f27ad2c2c567b031a&chksm=ea97625fdde0eb4922eae9ded101dbdf149a35a9241046aadaa90922cf8399c9e609cda4df9f&scene=27