Hadoop:YARN、MapReduce、Hive操作
分布式计算概述
分散->汇总模式:(MapReduce就是这种模式)
1. 将数据分片,多台服务器各自负责一部分数据处理
2. 然后将各自的结果,进行汇总处理
3. 最终得到想要的计算结果
中心调度->步骤执行模式:(大数据体系的Spark、Flink等是这种模式)
1. 由一个节点作为中心调度管理者
2. 将任务划分为几个具体步骤
3. 管理者安排每个机器执行任务
4. 最终得到结果数据
YARN概述
YARN 即Hadoop内提供的进行分布式资源调度的组件

一般来说,MapReduce最好是在YARN的管控下进行
Map任务喝Reduce任务分别向YARN申请资源,然后YARN根据现存的资源进行任务分配
YARN架构
核心架构
主从架构,有两个角色 :ResourceManager(主),NodeManager(从)
- ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
- NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用
当任务发起时,ResourceManager进行总的资源调度(每个服务器分配多少内存),然后NodeManager使用容器Container,预先占用这一部分资源,然后将这一部分资源提供给程序使用
辅助架构
除了这两个角色,还可以搭配两个辅助角色使得YARN更加稳定
- 代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
- 历史服务器(JobHistoryServer): 应用程序历史信息记录服务
Web应用代理(Web Application Proxy)
代理服务器,即Web应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。
JobHistoryServer历史服务器
历史服务器的功能很简单: 记录历史运行的程序的信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看。
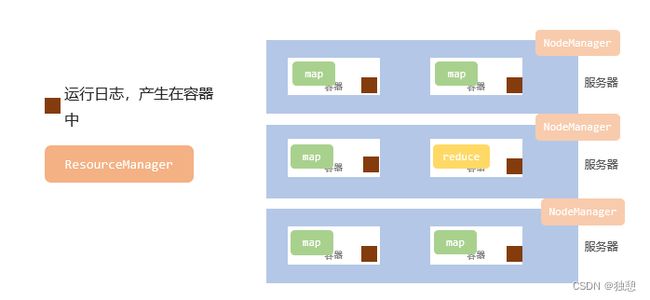
一般来说,日志运行在容器中,如果想查看日志则需要去不同的服务器调用不同意的容器,比较麻烦,于是就可以统一收集到HDFS,由历史服务器托管为WEB UI供用户在浏览器统一查看
MapReduce 概述
• MapReduce 是 Hadoop 中的分布式计算组件• MapReduce 可以以分散 -> 汇总(聚合)模式执行分布式计算任务,提供两个接口• map 接口,主要提供 “ 分散 ” 功能,由服务器分布式处理数据• reduce 接口,主要提供 “ 汇总 ” 功能,进行数据汇总统计得到结果
以一个统计问题为例子,例如要统计一个很长的字符串A里面有多少个字母a,那么假设我有四个服务器
设置三个服务器为分散服务器,一个服务器为汇总服务器,那么会把A map成三分,然后分别计算,最后把结果reduce到汇总服务器
配置相关文件
$HADOOP_HOME/etc/hadoop 文件夹内,修改:
#设置JDK路径
export JAVA_HOME=/export /server /jdk
#设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
#设置日志级别为INFO
export HADO0P_MAPRED_ROOT_LOGGER=INFO,RFA
•mapred-site.xml文件,添加如下配置信息
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
mapreduce.jobhistory.intermediate-done-dir
/data/mr-history/tmp
mapreduce.jobhistory.done-dir
/data/mr-history/done
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
mapreduce.map.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
mapreduce.reduce.env
HADOOP_MAPRED_HOME=$HADOOP_HOME
在 $HADOOP_HOME/etc/hadoop 文件夹内,修改:
#设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
#设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
#设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#设置目志文件路径的环境变量
export HADOOP LOG DIR=$HADO0P_HOME/logs
yarn.log.server.url
http://node1:19888/jobhistory/logs
yarn.web-proxy.address
node1:8089
proxy server hostname and port
yarn.log-aggregation-enable
true
Configuration to enable or disable log aggregation
yarn.nodemanager.remote-app-log-dir
/tmp/logs
Configuration to enable or disable log aggregation
yarn.resourcemanager.hostname
node1
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.nodemanager.local-dirs
/data/nm-local
Comma-separated list of paths on the local filesystem where intermediate data is written.
yarn.nodemanager.log-dirs
/data/nm-log
Comma-separated list of paths on the local filesystem where logs are written.
yarn.nodemanager.log.retain-seconds
10800
Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.
yarn.nodemanager.aux-services
mapreduce_shuffle
Shuffle service that needs to be set for Map Reduce applications.
然后复制到另外两个节点中去
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2: `pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3: `pwd`/最后启动:
一键启动YARN 集群: $HADOOP_HOME/sbin/start-yarn.sh会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager会基于 workers 文件配置的主机启动 NodeManager一键停止YARN 集群: $HADOOP_HOME/sbin/stop-yarn.sh在当前机器,单独启动或停止进程$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserverstart和stop决定启动和停止可控制resourcemanager、nodemanager、proxyserver三种进程历史服务器启动和停止$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
一般来说,运行下面就可以了
start-yarn.sh
mapred --daemon start historyserver可以通过 node1:8088这个端口检测yarn运行情况
提交MapReduce到YARN
一般来说不会直接写MapReduce代码,但是Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用。
• 这些内置的示例 MapReduce 程序代码,都在:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar 这个文件内。
• 可以通过 hadoop jar 命令来运行它,提交 MapReduce 程序到 YARN 中。语法: hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
这里举一个例子:
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /data/test.txt /data/wc使用wordcount这个方法,对test.txt进行运算,意思就是统计单词的数量,把结果存储到wc文件夹中:
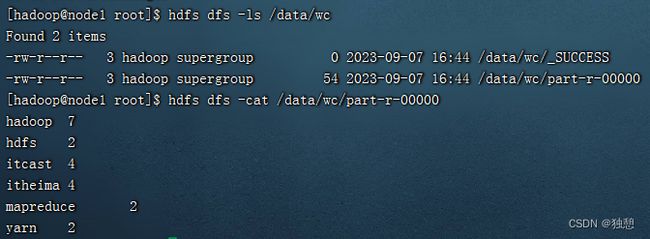
也可以进入node1:8088查看状态
Hive
MapReduce支持程序开发(Java、Python等)但不支持SQL开发,Apache Hive是一款分布式SQL计算的工具, 其主要功能是:将SQL语句 翻译成MapReduce程序运行
Hive架构
要实现分布式SQL计算,起码需要两种过程:
元数据管理:管理数据的位置,数据结构,数据描述,例如select age from table1,这样一条语句,需要存储table1的位置,age列对应的数据等等
SQL解析器:SQL分析,SQL到MapReduce程序的转换,提交MapReduce程序运行并收集执行结果
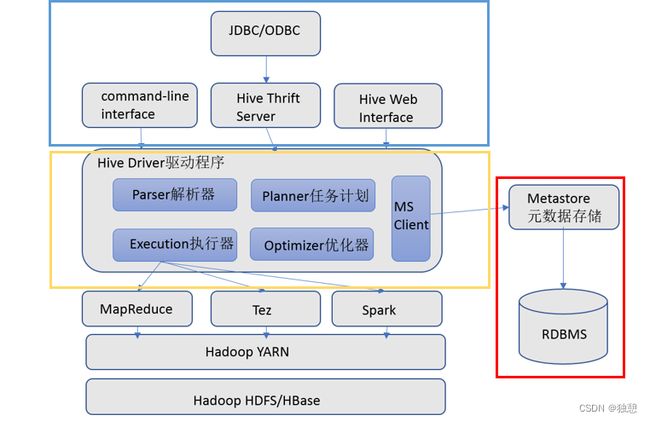
元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-- Hive提供了 Metastore 服务进程提供元数据管理功能
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中
用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
-- Hive提供了 Hive Shell、 ThriftServer等服务进程向用户提供操作接口
Hive在VMware部署
Hive是一个单机工具,只需要部署到一台服务器即可
以下步骤来自:第四章-04-[实操]Hive在VMware虚拟机中部署_哔哩哔哩_bilibili
1、在node1节点上配置Mysql
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql
yum -y install mysql-community-server
# 启动Mysql设置开机启动
systemctl start mysqld
systemctl enable mysqld
# 检查Mysql服务状态
systemctl status mysqld
# 第一次启动mysql,会在日志文件中生成root用户的一个随机密码,使用下面命令查看该密码
grep 'temporary password' /var/log/mysqld.log
# 修改root用户密码
mysql -u root -p -h localhost
Enter password:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root!@#$';
# 如果你想设置简单密码,需要降低Mysql的密码安全级别
set global validate_password_policy=LOW; # 密码安全级别低
set global validate_password_length=4; # 密码长度最低4位即可
# 然后就可以用简单密码了(课程中使用简单密码,为了方便,生产中不要这样)
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
/usr/bin/mysqladmin -u root password 'root'
grant all privileges on *.* to root@"%" identified by 'root' with grant option;
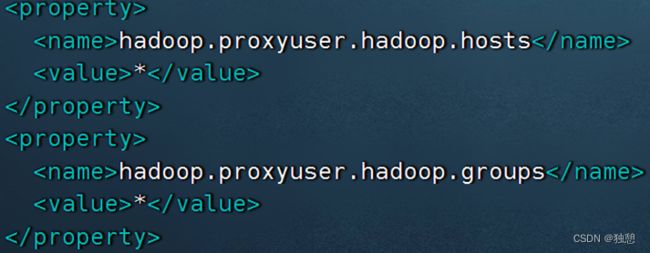
flush privileges;2、配置hadoop
配置如下内容在Hadoop的core-site.xml中,并分发到其它节点,且重启HDFS集群
3:下载解压Hive
• 切换到 hadoop 用户su - hadoop
• 下载 Hive 安装包:http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
• 解压到 node1 服务器的: /export/server/ 内tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
• 设置软连接ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
4:提供MySQL Driver包
• 下载 MySQL 驱动包:https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
• 将下载好的驱动 jar 包,放入: Hive 安装文件夹的 lib 目录内mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/
5:配置Hive
• 在 Hive 的 conf 目录内,新建 hive-env.sh 文件,填入以下环境变量内容:export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
•在Hive的conf目录内,新建hive-site.xml文件,填入以下内容:
javax.jdo.option.ConnectionURL
jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.server2.thrift.bind.host
node1
hive.metastore.uris
thrift://node1:9083
hive.metastore.event.db.notification.api.auth
false
步骤6:初始化元数据库
支持,Hive的配置已经完成,现在在启动Hive前,需要先初始化Hive所需的元数据库。
• 在 MySQL 中新建数据库: hiveCREATE DATABASE hive CHARSET UTF8;
• 执行元数据库初始化命令:cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
# 初始化成功后,会在MySQ L的hive库中新建74张元数据管理的表。
步骤7:启动Hive(使用Hadoop用户)
• 确保 Hive 文件夹所属为 hadoop 用户• 创建一个 hive 的日志文件夹:mkdir /export/server/hive/logs
• 启动元数据管理服务(必须启动,否则无法工作)前台启动:bin/hive --service metastore
后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
• 启动客户端,二选一(当前先选择 Hive Shell 方式)Hive Shell方式(可以直接写SQL): bin/hive
Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用): bin/hive --service hiveserver2
. Hive中创建的库和表的数据,存储在HDFS中,默认存放在:hdfs://node1:8020/user/hive/warehouse中。
Hive的启动
上面说到启动hive有两种方式,即前台方式和后台方式
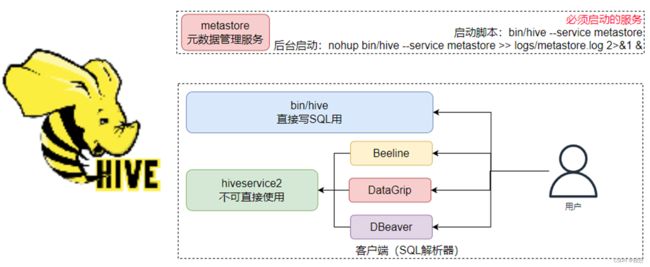
bin/hive这种就是直接 Hive的Shell客户端,写mysql代码
HiveServer2这种方式就是给第三方软件一个接口,可以使用第三方软件连接到hive,从而更方便的写mysql代码
HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口(默认10000)供其它客户端链接
可以连接ThriftServer的客户端有:
• Hive 内置的 beeline 客户端工具(命令行工具)第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
启动方法:
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore
nohup bin/hive --service hiveserver2
测试一下接口:
netstat -anp|grep 10000
说明 HiveServer2位于71625端口,且提供了端口号为10000的thrift端口
数据库操作
• 创建数据库create database if not exists myhive;
use myhive;
• 查看数据库详细信息desc database myhive;
• 创建数据库并指定hdfs存储位置create database myhive2 location '/myhive2';
使用location关键字,可以指定数据库在HDFS的存储路径。
• 删除一个空数据库,如果数据库下面有数据表,那么就会报错drop database myhive;
• 强制删除数据库,包含数据库下面的表一起删除drop database myhive2 cascade;
数据表操作
创建表的语法:
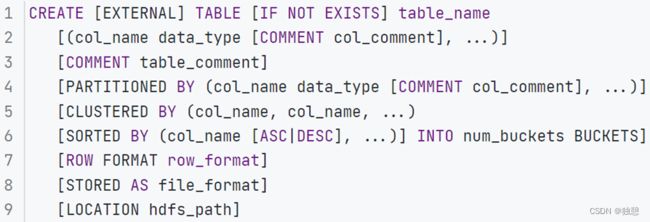
- •EXTERNAL,创建外部表
- •PARTITIONED BY, 分区表
- •CLUSTERED BY,分桶表
- •STORED AS,存储格式
- •LOCATION,存储位置
内部表操作
hive中的表可以分为 内部表 外部表 分区表 分桶表
• 内部表( CREATE TABLE table_name ...... )未被external关键字修饰的即是内部表, 即普通表。 内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
• 外部表 ( CREATE EXTERNAL TABLE table_name ......LOCATION...... )被external关键字修饰的即是外部表, 即关联表。
外部表是指表数据可以在任何位置,通过LOCATION关键字指定。 数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。
所以,在删除外部表的时候, 仅仅是删除元数据(表的信息),不会删除数据本身。
在创建完内部表并赋值后,可以查看内容,一半默认是存储在/user/hive/warehouse中,也可使用location替换:

可以看到列之间没有分割,其实只是我们看不到,默认的数据分隔符是:”\001”是一种特殊字符,是ASCII值,键盘是打不出来
在某些文本编辑器中是显示为SOH的。
当然,分隔符我们是可以自行指定的。
在创建表的时候可以自己决定:
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t';desc formatted table;外部表操作
外部表的数据和表是独立的,可以分别建立
比如先建立表,再建立数据文件
1、现在linux上建立文件date\test.txt:
vim test.txt
1 qqqq
2 wwww
3 eeee2、 创建外部表,这里必须规定分隔符,且必须跟上述文件中的分隔符一样
create external table test_ext1(id int, name string)
row format delimited fields terminated by ‘\t’ location ‘/tmp/test_ext1’;
3、把linux的文件放入hive的表对应的文件夹中
hdfs dfs -put -f test.txt /tmp/test_ext1/此时查看表test_ext1就可以看到对应内容了
4、但是如果此时修改test.txt文件,表的数据也会变化
但是在hive中删除表,不会删除数据文件
同理 先有数据文件再有表也可以
内部表和外部表可以相互转换
alter table stu set tblproperties('EXTERNAL'='TRUE');
alter table stu set tblproperties('EXTERNAL'='FALSE');
数据加载和导出
数据加载LOAD
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;
1、[LOCAL]:数据如果在linux本地,使用LOCAL,如果在hdfs中不使用
2、[OVERWRITE] 是否覆盖
基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)
数据加载 - INSERT SELECT 语法
我们也可以通过SQL语句,从其它表中加载数据。
INSERT [OVERWRITE | INTO] TABLE tablename1
[PARTITION (partcol1=val1, partcol2=val2 ...)
[IF NOT EXISTS]] select_statement1 FROM from_statement;
例如想要数据翻倍:
insert into test_ext1 select * from test_ext1这种方式会执行mapreduce,小数据下会比较慢
hive表数据导出 - insert overwrite 方式
insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;如果要导出到linux系统,就带local
例如
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
此处导出时的分隔符还是默认的,也可以自己定义分隔符
insert overwrite local directory '/home/hadoop/export2'
row format delimited fields terminated by '\t' select * from test_load;
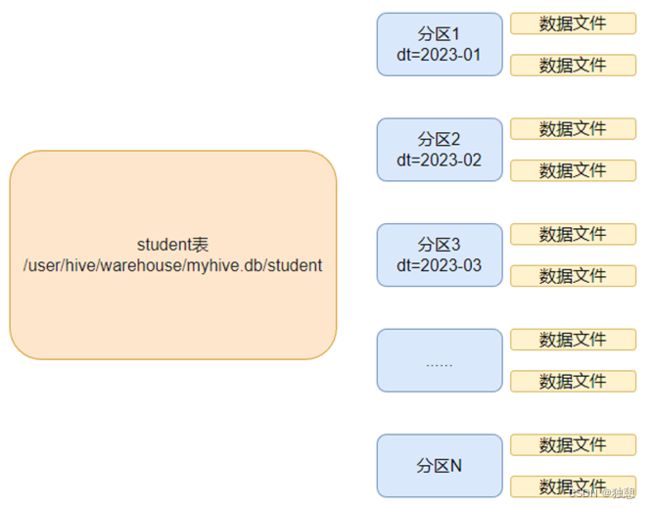
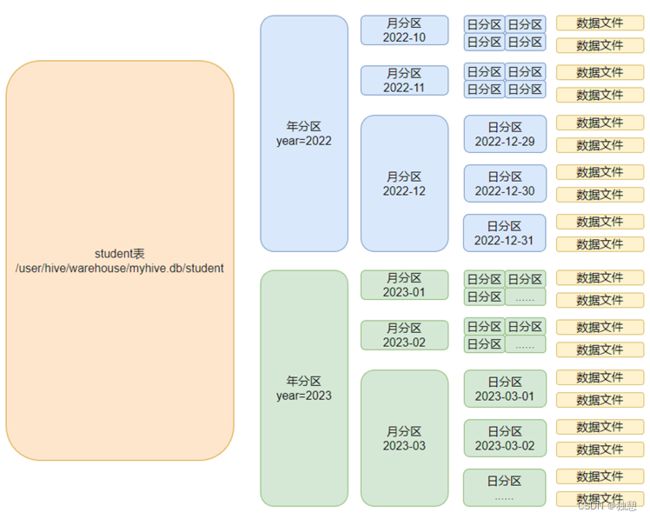
分区表
在hive中可以把大的数据进行分类,放置在不同的文件夹中进行存储,那么在操作时就会变得更加快速和简便
比如要存储不同月份的销售数据,那么可以根据月份进行分区,不同的月份创建不同的文件夹存放数据
语句:
create table tablename(...) partitioned by (分区列 列类型, ......)
row format delimited fields terminated by '';
实例:创建 partition_test表并按照month分区
create table partition_test(id int,name string) partitioned by (month string)
row format delimited fields terminated by '\t';
提前准备好test.txt文件:
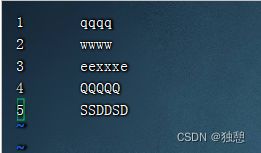
上传数据并设置月份:
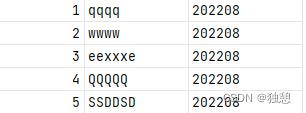
load data local inpath '/export/server/hive/date/test.txt'
into table partition_test partition(month='202208');最终:
又上传一遍 ,设置为202209:
load data local inpath '/export/server/hive/date/test.txt'
into table partition_test partition(month='202209'); 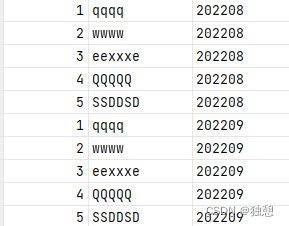
但是在文件中,会按照月份进行分别存放

当然也可以创建多级分区
create table partition_test(id int,name string)
partitioned by (year int,month int,day int)
row format delimited fields terminated by '\t';这样就会按照年月日进行分区了