kafka知识点汇总
kafka是什么?
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
消息队列的两种模式
- 点对点模式
一个生产者对应一个消费者,消费者消费消息后消息队列删除消息。 - 发布/订阅模式
- 可以有多个topic
- 消费者消费数据后,不删除数据
- 每个消费者相互独立,都可以消费到数据。
Kafka基础架构

kafa的架构是由生产者、kafka集群、消费者、Zookeeper组成的。生产者生产消息,发送到kafka集群,消费者从kafka集群消费消息,Zookeeper存储Kafka相关的元数据信息。
kafka由多个Broker(每个Broker就是一个Kafka服务实例)节点组成。
kafka里面的消息按主题进行管理,每个主题可以分成多个分区,每个分区会有一个或多个副本,分区和副本分别称为Leader分区和Follower分区,Leader分区和Follower分区在不同的Broker上,当Leader分区无法提供服务时,Follower分区会升级成Leader分区为消费者和生产者提供服务,Follower只负责同步数据,不提供服务。
消费者负责消费消息,多个消费者可以组成一个消费者组共同消费一个主题的消息,一个分区只能有消费者组中的一个消费者消费。
ISR、OS、AR
kafka中所有的Partition(Leader+Follower)称为AR(Assigned Replicas),与Leader保持同步的Partition集合称为ISR(In-Sync Replicas),与Leader不同步的Partition则称为OSR(Out-of-Sync Replicas),ISR的维护是根据Follower的同步情况实时维护的。Leader节点选举的时候,从AR中取在ISR中的第一个节点作为Leader。
生产者消息发送流程

生成者生产消息,然后消息经过拦截器做一些业务处理,然后通过序列化器做消息序列化,接着通过分区器对消息进行分区,分区器里面可以指定消息发往那个分区。
生产者将消息分好区后发送到RecordAccumulator中进行缓存,该缓冲器默认大小是32M,不同分区的消息不缓存到不同的内存缓存队列(ProducerBatch)中。
Sender线程负责不断的从RecordAccumulator中拉取消息发送到KafkaBroker,Sender线程拉取消息的策略可以通过batch.size和linger.ms来配置。
- batch.size配置ProducerBatch中数据累积到一个阈值后,Sender才会拉取数据,默认是16K。
- linger.ms配置sender拉取数据的时间间隔,默认为0;
- Sender拉取数据的条件就是ProducerBatch中数据累积达到batch.size或者时间间隔达到linger.ms,linger.ms为0表示,数据来了就会立马被Sender拉走。
Sendder内部通过InFightRequest来缓存数据发送到Broker但尚未收到应答的请求,底层通过Selector进行数据传输。 应答ACK有三种配置策略。
- 0:生产者发送过来的数据,不需要等待数据落盘应答,可靠性差,效率高。
- 1:生产者发送过来的数据,Leader收到数据后应答,可靠性中等,效率中等。
- -1/all:生成者发送过来的数据,需要Leader和ISR队列里面的所有节点收齐数据后应答,可靠性高,效率低。
kafka消息的顺序
kafka只能在一定条件下保证单分区消息的有序。
- 在1.x版本之前,需要配置max.in.flight.requests.per.connection=1,也就是Sender线程向Broker发送请求的InFightRequest只缓存一个连接。保证前一条消息成功落地后才发送下一条。
- 在1.x版本后提供类消息的幂等性,在开启幂等性的前提下,max.in.flight.requests.per.connection <= 5即可,未开启幂等性的情况下,max.in.flight.requests.per.connection=1。
Kafka中的几个偏移量
Kafka每个Partition中的消息都是append进去的,Kafka用几个重要的偏移量对消息进行维护。
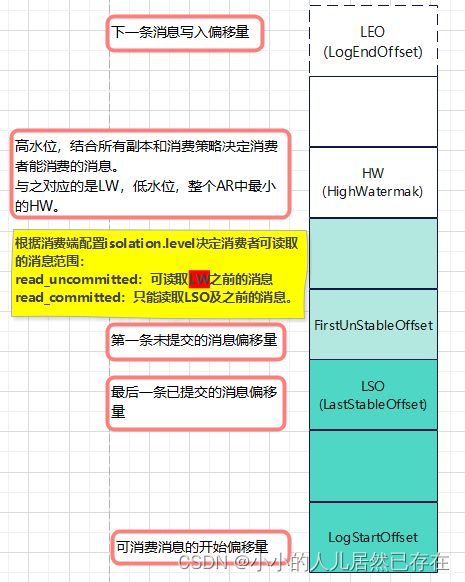
每个Partition分别维护着这些偏移量,用于数据同步和Leader重新选举后恢复数据一致性。
新的Leader出现后,如果其他Follower的HW小于新Leader的HW,则会先截取新HW之后的数据再开始同步,所以,如果Leader重选的Partition的HW小于先前的Leader的HW,则会出现消息丢失。
消息丢失场景
生产者端:
- ACK配置为0;
- ACK配置为1,消息发到Leader成功,但是Leader还没来得及同步到Follower就挂掉了。
- unclean.leader.election.enable配置为true,允许选举ISR以外的副本作为Leader,会导致数据丢失,默认为false。
解决方案:
- ACK配置为all/-1.
- 配置:min.insync.replicas>1,副本指定必须确认写操作成功的最小副本数量。
- 生产者发送消息会自动重试,要不可恢复的异常会抛出,这个时候可以捕获异常对发送失败的消息单独处理。
消费者端:
- 先commit再处理消息,如果处理消息时遇到异常,但offset已经提交,则消息会丢失。
解决方案:先处理再commit。
如果先处理消息再commit,消息处理完成后,commit提交失败则会导致重复消费问题。
Broker
broker在消息刷盘到磁盘之前挂掉,则会导致未刷盘的消息丢失。
解决方案:减少刷盘间隔。
如何保障消息不被重复消费
MQ无法解决消息的重复消费,所以需要消费者来保障消息的不被重复消费,可以采用幂等来解决(一个数据或请求重复,确保对应数据不会改变,不能出错)。
- 如果是写redis等缓存,则天然幂等。
- 生产者发送消息带上一个全局唯一的id,消费者拿到消息后,先更加这个id去redis里查一下,如果消费过则不再消费。
- 基于数据库的唯一键。
Kafa脚本
kafka-topics.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server |
连接的KafkaBroker主机名称和端口号 |
| –topic |
操作的topic名称 |
| –create | 创建主题 |
| –delete | 删除主题 |
| –alter | 修改主题 |
| –list | 查看所有主题 |
| –describe | 查看主题详细描述 |
| –partitions |
设置分区数 |
| –replication-factor |
设置分区的副本数 |
| –config |
更新系统默认配置 |
创建主题
bash./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic_name --partitions partition_num --replication-factor replication_num
其中:
–zookeeper localhost:2181:指定Zookeeper的地址。
–create:表示创建主题。
–topic topic_name:指定主题名称。
–partitions partition_num:指定主题的分区数。
–replication-factor replication_num:指定主题的副本数。
分区数只能增加,不能减少;
命令行不能修改副本数;
kafka-console-producer.sh
bash./kafka-console-producer.sh --broker-list localhost:9092 --topic topic_name
> message
其中:
–broker-list localhost:9092:指定Kafka的地址。
–topic topic_name:指定要发送消息到的主题。
–message`:要发送的消息内容。
kafka-console-consumer.sh
bash./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_name --from-beginning
其中:
–bootstrap-server localhost:9092:指定Kafka的地址。
–topic topic_name:指定要消费的主题。
–from-beginning:从消息队列头部开始消费。
是否从头消费根据实际情况决定。
SpringBoot集成Kafka
maven
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
customer
@Service
public class KafkaConsumer {
@KafkaListener(topics = "my-topic",groupId = "my-group")
public void kafkaListen(String message){
System.out.println(message);
}
}
producer
@RestController
@RequestMapping("/api/kafka")
public class KafkaController {
@Autowired
private KafkaTemplate kafkaTemplate;
@GetMapping("send")
public Result send(String topic,String msg){
kafkaTemplate.send(topic,msg);
return Result.ok();
}
}
消费者配置:
auto.offset.rese:
- earliest:消费未消费过的数据。
- latest:消费最新的消息,消费者启动前产生的消息不会再次消费。