自然语言处理(一):基于统计的方法表示单词
文章目录
-
- 1. 共现矩阵
- 2. 点互信息
- 3. 降维(奇异值分解)
1. 共现矩阵
将一句话的上下文大小窗口设置为1,用向量来表示单词频数,如:

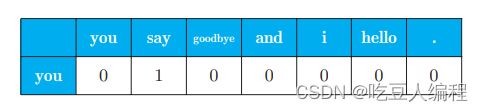
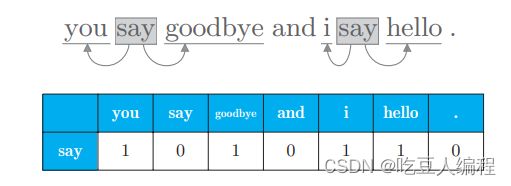
将每个单词的频数向量求出,得到如下表格,即共现矩阵:

我们可以用余弦相似度(cosine similarity)来计算单词向量的相似性:
similarity ( x , y ) = x ⋅ y ∥ x ∥ ∥ y ∥ = x 1 y 1 + ⋯ + x n y n x 1 2 + ⋯ + x n 2 y 1 2 + ⋯ + y n 2 \operatorname{similarity}(\boldsymbol{x}, \boldsymbol{y})=\frac{\boldsymbol{x} \cdot \boldsymbol{y}}{\|\boldsymbol{x}\|\|\boldsymbol{y}\|}=\frac{x_{1} y_{1}+\cdots+x_{n} y_{n}}{\sqrt{x_{1}^{2}+\cdots+x_{n}^{2}} \sqrt{y_{1}^{2}+\cdots+y_{n}^{2}}} similarity(x,y)=∥x∥∥y∥x⋅y=x12+⋯+xn2y12+⋯+yn2x1y1+⋯+xnyn
有时会出现分母为0的情况,在具体代码实现的时候,我们可以加上一个微小值,如1e-8
def cos_similarity(x, y, eps=1e-8):
nx = x / (np.sqrt(np.sum(x ** 2)) + eps)
ny = y / (np.sqrt(np.sum(y ** 2)) + eps)
return np.dot(nx, ny)
2. 点互信息
在语料库中可能会看到很多“…the car…”这样的短语。实际上,与 the相比,drive和 car 的相关性更强。为了避免这种情况,可以引入PMI
PMI ( x , y ) = log 2 P ( x , y ) P ( x ) P ( y ) = log 2 C ( x , y ) N C ( x ) N C ( y ) N = log 2 C ( x , y ) ⋅ N C ( x ) C ( y ) \operatorname{PMI}(x, y)=\log _{2} \frac{P(x, y)}{P(x) P(y)}=\log _{2} \frac{\frac{\boldsymbol{C}(x, y)}{N}}{\frac{\boldsymbol{C}(x)}{N} \frac{\boldsymbol{C}(y)}{N}}=\log _{2} \frac{\boldsymbol{C}(x, y) \cdot N}{\boldsymbol{C}(x) \boldsymbol{C}(y)} PMI(x,y)=log2P(x)P(y)P(x,y)=log2NC(x)NC(y)NC(x,y)=log2C(x)C(y)C(x,y)⋅N
P(x) 表示 x 发生的概率,P(y) 表示 y 发生的概率,P(x, y) 表示 x
和 y 同时发生的概率。PMI 的值越高,表明相关性越强。
这里假设语料库的单词数量(N)为 10 000,the 出现 100 次,car 出现 20 次,drive 出现 10 次,the 和 car 共现 10 次,car 和 drive 共现 5 次。
P M I ( " t h e " , " c a r " ) = l o g 2 10 ⋅ 10000 1000 ⋅ 20 ≈ 2.32 PMI("the","car")=log_2\frac{10\cdot 10000}{1000 \cdot 20}\approx 2.32 PMI("the","car")=log21000⋅2010⋅10000≈2.32
P M I ( " c a r " , " d r i v e " ) = l o g 2 5 ⋅ 10000 20 ⋅ 10 ≈ 7.79 PMI("car","drive")=log_2\frac{5\cdot 10000}{20 \cdot 10}\approx 7.79 PMI("car","drive")=log220⋅105⋅10000≈7.79
得出的PMI值,后者比前者要高,这是我们所需要的结果
3. 降维(奇异值分解)
奇异值分解(Singular Value Decomposition,SVD)。SVD 将任意矩阵分解为 3 个矩阵的乘积,如下式所示:
X = U S V T X=USV^T X=USVT
上面的例子只考虑了一句话中少量单词的共现矩阵,如果我们使用一个真正的语料库,那么这个矩阵将变得十分庞大,这是一个很大的稀疏矩阵,我们需要对其进行降维,这里用到奇异值分解。
在numpy中可以用
U, S, V = np.linalg.svg()

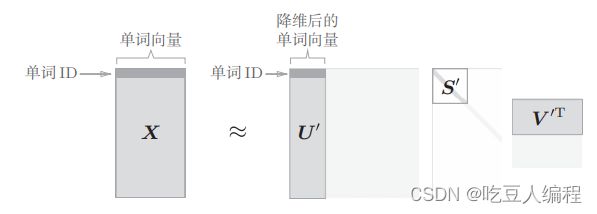
我们只需要取矩阵U的前两个元素即可将其降维到二维向量。