迁移学习和多任务学习
迁移学习(Transfer Learning)
深度学习中,最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。
例如,你已经训练好一个能够识别猫的图像的神经网络,然后使用从这个神经网络学习得到的知识,或者部分习得的知识去帮助您更好地阅读x射线扫描图,这就是所谓的迁移学习。
那么迁移学习什么时候是有意义的呢?迁移学习起作用的场合是,在迁移来源问题中你有很多数据,但迁移目标问题你没有那么多数据。例如,假设图像识别任务中你有1百万个样本,所以这里数据相当多。可以学习低层次特征,在神经网络的前面几层学到如何识别很多有用的特征。但是对于放射科任务,也许你只有一百个样本,你的放射学诊断问题数据很少,所以你从图像识别训练中学到的很多知识可以迁移,并且真正帮你加强放射科识别任务的性能。
所以在这种情况下,你是从数据量很多的问题迁移到数据量相对小的问题。然而反过来的话,迁移学习可能就没有意义了。比如,你用100张图训练图像识别系统,然后有100甚至1000张图用于训练放射科诊断系统,为了提升放射科诊断的性能,那么用放射科图像训练可能比使用猫和狗的图像更有价值。所以,如果你的放射科数据更多,那么你这100张猫猫狗狗或者随机物体的图片肯定不会有太大帮助,因为来自猫狗识别任务中,每一张图的价值肯定不如一张 X 射线扫描图有价值,对于建立良好的放射科诊断系统而言是这样。
所以总结一下,什么时候迁移学习是有意义的?如果你想从任务 A 学习并迁移一些知识到任务 B ,那么当任务 A 和任务 B 都有同样的输入 x 时,迁移学习是有意义的。在上面的例子中, A 和 B 的输入都是图像。当任务 A 的数据比任务 B 多得多时,迁移学习意义更大。所有这些假设的前提都是,你希望提高任务 B 的性能,因为任务 B 每个数据更有价值,对任务 B 来说通常任务 A 的数据量必须大得多,才有帮助,因为任务 A 里单个样本的价值没有比任务 B 单个样本价值大。然后如果你觉得任务 A 的低层次特征,可以帮助任务 B 的学习,那迁移学习更有意义一些。
多任务学习
在迁移学习中,你的步骤是串行的,你从任务 A 里学习知识然后迁移到任务 B 。在多任务学习中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
 假设你在研发无人驾驶车辆,你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如上图图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。
假设你在研发无人驾驶车辆,你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如上图图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。
如果输入图像 x ( i ) x^{(i)} x(i),那么输出不再是一个标签 y ( i ) y^{(i)} y(i),而是有4个标签,所以 y ( i ) y^{(i)} y(i)是个4×1向量。如果你从整体来看这个训练集标签和以前类似,我们将训练集的标签水平堆叠起来,像这样 y ( 1 ) y^{(1)} y(1)到 y ( m ) y^{(m)} y(m):
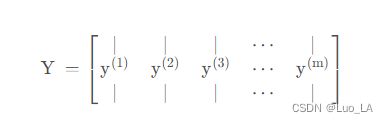
矩阵 Y Y Y是 4 × m 4×m 4×m矩阵。
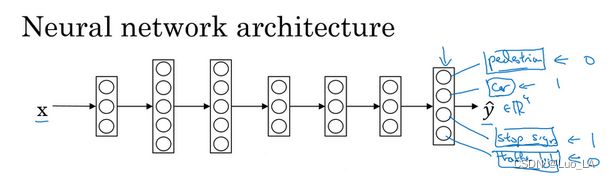 那么你现在可以做的是训练一个神经网络,来预测这些 y 值,你就得到这样的神经网络,输入 x ,现在输出是一个四维向量 y 。这里有四个输出节点,第一个节点就是我们想预测图中有没有行人,然后第二个输出节点预测的是有没有车,然后是停车标志和交通灯,因此 y ^ \hat{y} y^ 是4维的。
那么你现在可以做的是训练一个神经网络,来预测这些 y 值,你就得到这样的神经网络,输入 x ,现在输出是一个四维向量 y 。这里有四个输出节点,第一个节点就是我们想预测图中有没有行人,然后第二个输出节点预测的是有没有车,然后是停车标志和交通灯,因此 y ^ \hat{y} y^ 是4维的。
要训练这个神经网络,你现在需要定义神经网络的损失函数,对于一个输出 y ^ \hat{y} y^ ,是个4维向量,对于整个训练集的平均损失:
1 m ∑ i = 1 m ∑ j = 1 4 L ( y ^ j ( i ) , y j ( i ) ) \frac{1}{m}\sum_{i=1}^{m}\sum_{j=1}^{4}L(\hat{y}_j^{(i)},y_j^{(i)}) m1i=1∑mj=1∑4L(y^j(i),yj(i))
∑ j = 1 4 L ( y ^ j ( i ) , y j ( i ) ) \sum_{j=1}^{4}L(\hat{y}_j^{(i)},y_j^{(i)}) ∑j=14L(y^j(i),yj(i)) 这些单个预测的损失,就是对四个分量的求和,标志 L L L 指的是 logistic 损失:
L ( y ^ j ( i ) , y j ( i ) ) = − y j ( i ) log y ^ j ( i ) − ( 1 − y j ( i ) ) log ( 1 − y ^ j ( i ) ) L(\hat{y}_j^{(i)},y_j^{(i)})=-y_j^{(i)}\log \hat{y}_j^{(i)}-(1-y_j^{(i)})\log(1-\hat{y}_j^{(i)}) L(y^j(i),yj(i))=−yj(i)logy^j(i)−(1−yj(i))log(1−y^j(i))
整个训练集的平均损失和之前分类猫的例子主要区别在于,现在你要对 j = 1 到 4 j=1 到 4 j=1到4求和,这与softmax回归的主要区别在于,softmax将单个标签分配给单个样本。
不是说每张图都只是一张行人图片,汽车图片、停车标志图片或者交通灯图片。你要知道每张照片是否有行人、或汽车、停车标志或交通灯,多个物体可能同时出现在一张图里。实际上,在文章开始的那张图中,同时有车和停车标志,但没有行人和交通灯,所以你不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,那类物体有没有出现在图中。如果你训练了一个神经网络,试图最小化这个成本函数,你做的就是多任务学习。
另外你也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络一些早期特征,在识别不同物体时都会用到,然后你发现,训练一个神经网络做四件事情会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
多任务学习什么时候有意义呢?
第一,如果你训练的一组任务,可以共用低层次特征。对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志。
第二点不是绝对正确的准则,如果你专注于单项任务,想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量,这样其他任务的知识才能帮你改善这个任务的性能。
第三是你可以训练一个足够大的神经网络。多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况就是你的神经网络还不够大。但如果你可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能。
在实践中,多任务学习的使用频率要低于迁移学习。多任务学习比较少见,在计算机视觉领域,物体检测这个例子是最显著的例外情况。但平均来说,目前迁移学习使用频率更高,比多任务学习频率要高,但两者都可以成为你的强力工具。
所以总结一下,多任务学习能让你训练一个神经网络来执行许多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。