百货商场用户画像描绘与价值分析
百货商场用户画像描绘与价值分析项目
文章目录
-
- 百货商场用户画像描绘与价值分析项目
- 一、背景及思路
- 二、数据说明
- 三、数据探索及数据预处理
- 四、数据分析及可视化
- 五、构建用户画像
- 六、营销方案
- 七、结论
数据源来自和鲸社区分享的泰迪公司提供的百货商店会员数据。
会员信息表:会员卡号 出生时间 性别 登记时间
订单流水表:会员卡号 消费时间 商品编码 销售数量 商品售价 消费金额 商品名称 此次消费的会员积分 收银机号 单据号 柜组编码 柜组名称
本项目主要围绕着“百货商店会员用户画像描绘与价值分析”内容进行,结合目前百货商场的数据情况,可以实现以下目标:
借助百货商场会员用户数据,对会员用户进行分群。
对不同的会员用户类别进行特征分析,比较不同类别会员用户的会员用户价值。
对不同价值的会员用户类别提供个性化服务,制定相应的营销策略。
一、背景及思路
- 背景
百货商场是一个拥有大量会员的零售机构,会员价值体现在持续不断地为零售运营商带来稳定的销售额和利润,同时也为零售运营商策略的制定提供数据支持。零售行业会采取各种不同方法来吸引更多的人成为会员,并且尽可能提高会员的忠诚度。当前电商的发展使商场会员不断流失,给零售运营商带来了严重损失。
本案例通过对某商场的经营数据和会员信息数据进行分析,对商场会员进行用户画像描绘,并根据会员的消费特征对会员进行精细划分,针对不同群体制定对应的营销策略,从而提升商场的销售利润。
- 分析思路
- 数据收集:收集百货商场会员的交易数据,包括会员信息、消费记录等。
- 数据清洗与预处理:对数据进行探索和清洗,处理缺失值、异常值等问题,确保数据的准确性和完整性。
- 数据合并:将不同的数据表进行合并,建立全面的会员数据集。
- 统计分析与可视化:对会员数据进行统计分析,包括年龄段分析、消费金额分析、性别比例分析、订单数分析等,并利用可视化工具进行数据可视化展示。
- 构建用户画像:根据统计分析结果,描绘会员的特征画像,如年龄段、消费偏好、性别比例等,帮助商场更好地了解目标用户群体。
- 营销方案:基于用户画像和价值分析结果,制定个性化的营销方案,包括优惠券、促销活动、会员专享服务等,以提高客户的忠诚度和消费频率。
二、数据说明
- 会员信息表:
- kh(会员卡号):会员的唯一标识
- csrq(会员的出生日期)
- xb(性别):0表示女士,1表示男士
- djsj(会员入会登记时间)
- 订单流水表:
- dtime(消费产生的时间)
- spbm(商品编码)
- sl(销售数量)
- sj(商品售价)
- je(消费金额)
- spmc(商品名称)
- jf(此次消费的会员积分)
- syjh(收银机号)
- djh(单据号)
- gzbm(柜组编码)
- gzmc(柜组名称)
三、数据探索及数据预处理
- 数据探索及数据清洗:
- 探索数据集,查看缺失值、异常值、重复值等问题。
- 处理缺失值和异常值,根据实际情况进行填充或删除。
- 去除重复值,确保数据的唯一性。
- 进行数据类型转换,确保数据的一致性。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来显示负号
x = pd.read_excel('D:\\BigData\\analyse\\retail-master\\项目数据1.xlsx') # 导入第一张表数据
x.shape # 第一张表查看数据结构
x.keys() # 查看键
x = x.drop_duplicates() # 第一张表去重
# 第一张表缺少值处理
x.isnull().sum()
x = x.dropna()
# 第一张表异常值处理
x['csrq'].dtype # 查看出生日期的数据类型
pd.Timestamp.max # 查看时间的范围
# 第二张表处理
y = pd.read_csv('D:\\BigData\\analyse\\retail-master\\项目数据2.csv')
y['je'].describe() # 查看je列的描述
p = plt.boxplot(y['je']) # 异常值箱线图
plt.show()
p['fliers'][0].get_ydata() # 提取异常值
# 合并两张表
z = pd.merge(y,x,left_on='kh',right_on='kh') # 主键合并,left_on、right_on都是键
z['xb'] = z['xb'].fillna(1)
z['xb'] = z['xb'].astype(int)
z
异常值箱线图如下:

四、数据分析及可视化
- 分析会员年龄段
首先使用datetime库将会员的出生日期进行格式转换并提取出会员出生日期的年份,然后打印出当前年份,对二者进行相减从而得出会员的年龄。之后对其进行划分,使用pd.cut对会员的年龄划分为“Youth”,“Midlife”,“Elder”三个群体。
task2 = pd.to_datetime(z['csrq']) # 将出生日期转换为时间格式
import datetime as dt
Now_year = dt.datetime.today().year # 今天的日期
Age = Now_year - task2.dt.year # 算出年龄
Age
Age_group = pd.cut(Age,[15,45,59,120]) # 数据分段
Age_group
Age_group = Age_group.value_counts() # 统计数量
plt.pie(Age_group,labels=['Youth','Midlife','Elder'],autopct='%.1f%%') #输出饼图
plt.show()

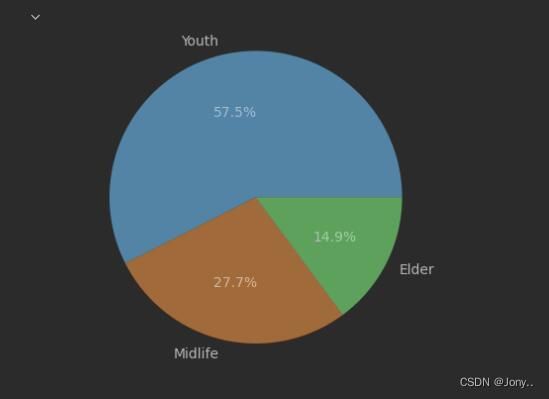
- 分析不同年龄段会员的消费金额
使用groupby来对金额进行聚合分组。然后,将groupby之后的数据使用value_counts进行统计,得出每个年龄段的消费金额。
amount = z['je'].groupby(by=Age_group) # 根据年龄对金额进行分类
import numpy as np
amount1 = amount.agg(np.sum) # 加总各个年龄的金额
# #根据年龄分类计算各年龄段的消费金额绘制饼图
plt.pie(amount1,labels=['Youth','Midlife','Elder'],autopct='%.1f%%')
plt.show()
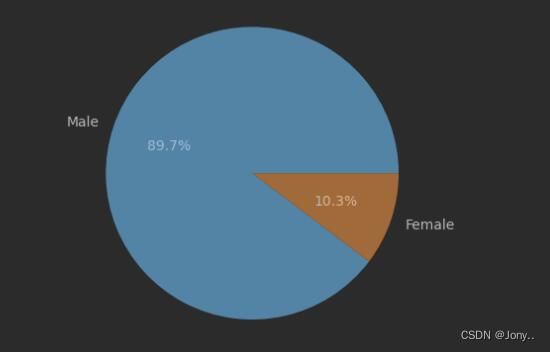
- 分析会员的性别比例
使用value_counts对性别进行统计,用统计得到的数据绘制饼图。
gender = z['xb'].value_counts() # 统计性别的样本数量
plt.pie(gender,labels=['Male','Female'],autopct='%.1f%%') # 制作性别比例饼图
plt.show()
- 分析不同性别的会员消费金额的比例
使用了agg()函数对amount_gender进行了聚合操作,将相同性别的消费金额进行了求和。
amount_gender = z['je'].groupby(gender) # 根据性别分类出金额数据
amount_gender1 = amount_gender.agg(np.sum) # 统计金额
#根据年龄分类计算各年龄段的消费金额
plt.pie(amount_gender1,labels=['Male','Female'],autopct='%.1f%%')
plt.show()

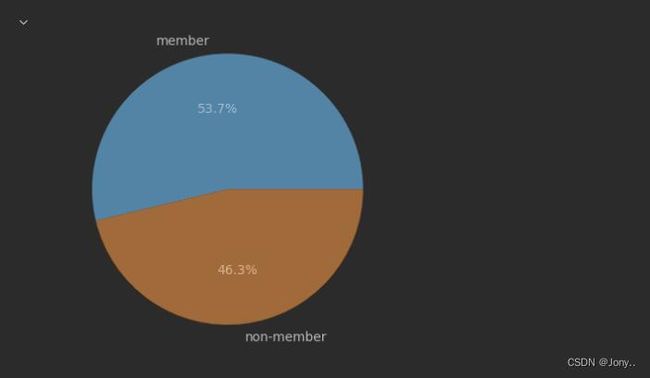
- 分析会员的订单数
对表中的卡号列的缺失值与非缺失值进行统计,并制作饼图
y['kh'].isnull().sum() # 查看客户为空的行数
y['kh'].notnull().sum() # 查看客户不为空的行数
y['kh'].value_counts()
plt.pie([y['kh'].isnull().sum(),y['kh'].notnull().sum()],labels=['member','non-member'],autopct='%.1f%%')
plt.show()
- 分析会员与非会员的消费金额比例
通过计算总的消费金额,减去会员消费金额,算出非会员的消费金额。
amount_member = z['je'].sum() # 会员金额
amount_non_member = y['je'].sum() - z['je'].sum() # 非会员金额
plt.pie([amount_member,amount_non_member],labels=['member','non_member'],autopct='%.1f%%')
plt.show()

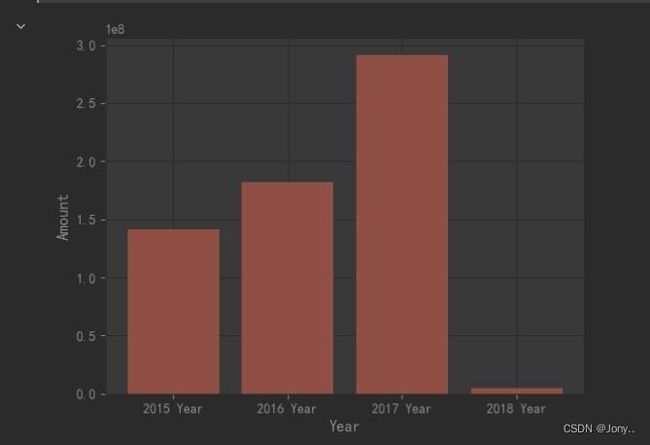
- 分析商场会员不同年份的消费金额
提取出会员消费的年份,以此为条件对“je”列进行聚合分组,然后对其进行汇总统计;最后制作柱状图。
dtime_year = pd.to_datetime(z['dtime']).dt.year # 提取出会员消费的年份
dtime_year
amount_year = z['je'].groupby(dtime_year)
amount_year1 = amount_year.agg(np.sum) # 贾总各个年份的金额
amount_year1
plt.bar(['2015 Year','2016 Year','2017 Year','2018 Year'],amount_year1)
plt.ylabel('Amount')
plt.xlabel('Year')
plt.show()
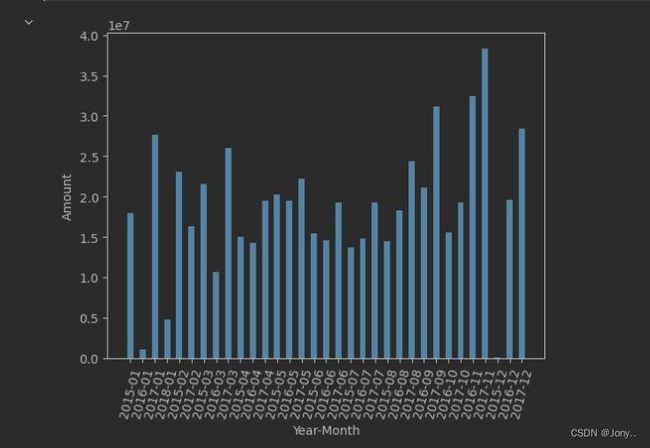
- 分析会员不同月份的消费金额
提取出会员的消费月份,“je”上述代码中提取出的消费年份和本次提取出的月份为分组条件进行分组聚合,然后对聚合结果进行统计分析,并绘制柱状图。
dtime_month = pd.to_datetime(z['dtime']).dt.month #提取消费月份
dtime_month # 输出结果
amount_month = z['je'].groupby(by=[dtime_month,dtime_year]) # 根据年月进行分类聚合
amount_month_res = amount_month.agg(np.sum) # 输出各年月份加总金额
amount_month_res
x = ['2015-01','2016-01','2017-01','2018-01',
'2015-02','2017-02',
'2015-03','2016-03','2017-03',
'2015-04','2016-04','2017-04',
'2015-05','2016-05','2017-05',
'2015-06','2016-06','2017-06',
'2015-07','2016-07','2017-07',
'2015-08','2016-08','2017-08',
'2016-09','2017-09',
'2016-10','2017-10',
'2016-11','2017-11',
'2015-12','2016-12','2017-12']
plt.bar(x,amount_month_res,width=0.5)
plt.xticks(x,x,rotation=75)
plt.ylabel('Amount')
plt.xlabel('Year-Month')
plt.show()
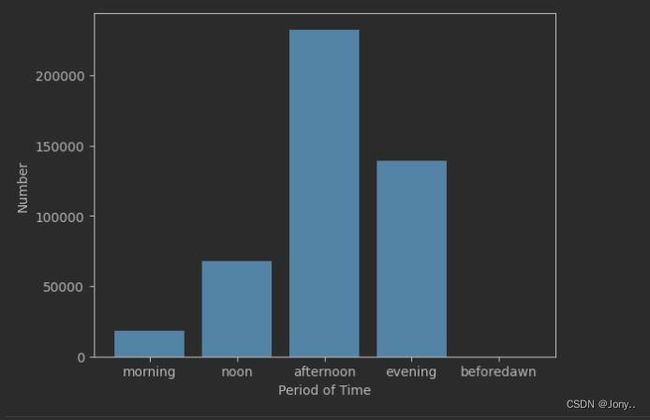
- 分析一天中会员消费高峰时段
提取出会员消费的“小时”数据,并以提取出的小时进行聚合分组。最后按“早上”,“中午”,“下午”,“晚上”,“凌晨”这五个时段进行统计,并制作柱状图。
#任务2.3.1
ddtime_hour = pd.to_datetime(z['dtime']).dt.hour # 提取出消费时间的“小时”
amount_hour = z['je'].groupby(ddtime_hour) # 根据“小时”来计算各个小时的金额
amount_hour1 = amount_hour.agg(np.sum) # 输出各个小时的消费金额
amount_hour1
amount_morning = 547801.23+ 23925058.02+ 41099533.55 #早上的消费金额
amount_noon = 50638448.43 + 54009197.32 #中午的消费金额
amount_afternoon = 58653027.97 + 67055349.36 + 69643425.32 + 64108654.96 + 50613356.48 #下午的消费金额
amount_evening = 41809627.43 + 44854627.50 + 40631594.72 + 10385821.73 + 2021491.47 #晚上的消费金额
amount_beforedawn = 121891.20 + 124062.20 + 56770.20 #凌晨的消费金额
number_hour = z['djh'].groupby(ddtime_hour) # 根据消费的“小时来划分单据发生”
number_hour.count() # 计算出各个时间的订单数
number_morning = 305 + 17865
number_noon = 30490 + 37087
number_afternoon = 40333 + 44996 + 49701 + 51131 + 46353
number_evening = 37663 + 31630 + 33316 + 28815 + 6573 + 1159
number_beforedawn = 53 + 34 + 7
plt.bar(['morning','noon','afternoon','evening','beforedawn'],[number_morning,number_noon,number_afternoon,number_evening,number_beforedawn])
plt.xlabel('Period of Time')
plt.ylabel('Number')
plt.show()
- 分析不同季节会员的消费金额
使用提取出的会员消费年份和月份,对“djh”进行聚合分组,对聚合结果进行统计,绘制柱状图。
#任务2.3.2
number_season = z['djh'].groupby(by=[dtime_year,dtime_month]) # 按照月和年划分单据号
number_season = number_season.count() # 计数
number_2015_spring = np.sum(number_season[0:3])
number_2015_summer = np.sum(number_season[3:6])
number_2015_fall = np.sum(number_season[6:8])
number_2015_winter = np.sum(number_season[7:8])
number_2016_spring = np.sum(number_season[9:11])
number_2016_summer = np.sum(number_season[11:14])
number_2016_fall = np.sum(number_season[14:17])
number_2016_winter = np.sum(number_season[17:20])
number_2017_spring = np.sum(number_season[20:23])
number_2017_summer = np.sum(number_season[23:26])
number_2017_fall = np.sum(number_season[26:29])
number_2017_winter = np.sum(number_season[29:32])
number_2018_spring = np.sum(number_season[32:35])
x = ['2015 spring','2015 summer','2015 fall','2015 winter',
'2016 spring' ,'2016 summer','2016 fall','2016 winter',
'2017 spring','2017 summer','2017 fall','2017 winter','2018 spring']
plt.bar(x,[number_2015_spring,number_2015_summer,number_2015_fall,number_2015_winter,
number_2016_spring,number_2016_summer,number_2016_fall,number_2016_winter,
number_2017_spring,number_2017_summer,number_2017_fall,number_2017_winter,number_2018_spring],width = 0.5) #绘图
plt.xticks(x,x,rotation=30)
plt.show()

五、构建用户画像
读取用户画像文件,对“年龄”,“积分”,“卡号”,“性别”进行赋值。
m = pd.read_excel('D:\\BigData\\analyse\\retail-master\\用户画像.xlsx')
m['年龄'] = Age
m['积分'] = z['jf']
m['卡号'] = z['kh']
for i in z['xb']:
if z['xb'].loc[i] == 0:
m['性别'] = '男'
else:
m['性别'] = '女'
通过当天日期-会员登记时间(djsj)得到会员的入会时长,给列“入会时长”,“消费水平”,“购物偏好”,“购物季节偏好”赋值。
#任务3.2
Now_year = dt.datetime.today().year # 今天的日期
member_time = Now_year - z['djsj'].dt.year # 入会时长
m['入会时长'] = member_time
m['消费水平'] = z['je']
n = z['spmc']
m['购物偏好'] = n
dtime_quarter = pd.to_datetime(z['dtime']).dt.quarter
for i in range(len(dtime_quarter)):
line = dtime_quarter.iloc[i]
if line == 1:
m['购物季节偏好'] = '春季'
elif line == 2:
m['购物季节偏好'] = '夏季'
elif line == 3:
m['购物季节偏好'] = '秋季'
elif line == 4:
m['购物季节偏好'] = '冬季'
m.loc[20]
绘制词云图
import wordcloud
wc = wordcloud.WordCloud(scale=16,background_color = 'white',max_words = 100,colormap ='coolwarm',font_path='./SimHei.ttf')
result = m.loc[0]
X = wc.generate(str(result))
wc.to_file(r'.\wordcloud.png')
plt.imshow(X)
用户价值特征分析
file = pd.read_excel('D:\\BigData\\analyse\\retail-master\\Model.xlsx')
file['入会时长'] = m['入会时长']
file['消费金额'] = m['消费水平']
file['消费季节'] = dtime_quarter
file = file.fillna(0)
file
# 数据差距太大,进行标准化处理
def Zscore(data):
data = (file - file.mean())/file.std()
data.columns = ['Z' + i for i in data.columns]
return data
datafile = Zscore(data=file)
datafile = datafile.fillna(0)
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3).fit(file)
model
model.labels_
model.cluster_centers_ # 查看聚类中心
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中学
r = pd.concat([r2,r1],axis=1) # 连接r1,r2
r.columns = list(datafile.columns) + ['类别数目'] # 重命名表头
r3 = pd.concat([datafile,pd.Series(model.labels_,index=datafile.index)],axis=1) # 详细输出每个样本对应的类别
r3.columns = list(datafile.columns) + ['聚类类别'] # 重命名表头
六、营销方案
- 新客户营销建议:
- 通过广告宣传和市场推广活动吸引新客户的注意力,例如优惠促销、新用户专享折扣等。
- 提供良好的购物体验,包括店面布局设计、商品陈列和导购服务等,以吸引新客户的兴趣并提高他们的购买意愿。
- 针对新客户提供个性化的推荐和优惠,基于他们的购买行为和偏好进行精准营销。
- 鼓励新客户参与会员计划,享受更多会员特权和福利,例如积分兑换、生日礼品等,以促使他们成为忠实客户。
- 会员营销建议:
- 加强会员关系管理,保持与会员的良好沟通和互动,例如发送个性化的推荐和优惠信息,定期提供会员活动和专享福利。
- 培养会员的忠诚度,通过提供高品质的产品和服务,让会员感受到与众不同的购物体验,从而增加他们的复购率。
- 提供会员专属活动和特权,例如会员专场、预售活动等,以激发会员的兴趣和购买欲望。
- 利用会员数据进行数据分析,了解会员的购买偏好和消费行为,从而进行精准的营销和个性化推荐。
七、结论
在百货商场用户画像描绘与价值分析项目中,拓展新客户的成本较高,而维持会员的成本相对较低。因此,留住会员成为一个重要的策略方向。通过提供个性化的优惠和特权,以及优质的购物体验,商场可以增加会员的忠诚度,并促使他们进行持续的消费。同时,会员的满意度和忠诚度也能够通过口碑传播,帮助吸引新客户。
为了吸引新客户,百货商场可以投放一定数量的广告,并利用互联网和新媒体渠道进行宣传推广。通过社群裂变等方式,商场可以在社群中发放优惠券、折扣等激励措施,吸引新客户前来购买。同时,利用数据驱动的决策和优化,商场可以进行精准营销,针对不同的用户群体制定差异化的营销策略,提高顾客的满意度和忠诚度。
综上所述,百货商场可以通过留住会员和吸引新客户相结合的方式,实现精准营销和差异化服务,提高顾客的满意度和忠诚度,从而刺激客户的消费。通过持续优化和改进营销策略,商场有望实现可持续的业绩增长和市场竞争优势。