使用Python爬虫获取大乐透开奖信息的实践
使用Python爬虫获取大乐透开奖信息的实践
文章目录
-
-
- 1. 引言
- 2. 技术选型
- 3.反爬机制
- 4. 程序实现步骤
- 5. 数据分析和展示
- 6. 总结
-
简介: 在数字化时代,数据获取和分析成为了重要的任务。本文将介绍如何使用Python编写一个爬虫程序,获取大乐透近2000期的开奖信息,并将数据保存到CSV文件中。通过这个实践项目,我们可以学习如何使用Selenium进行页面交互,解决网页加载和元素定位的难题,并利用Pandas对数据进行处理和存储。
正文:
1. 引言
数据在当今社会具有巨大的价值,而获取数据的过程通常需要经过各种挑战和困难。在本文中,我们将探索如何利用Python爬虫技术获取大乐透的开奖信息。大乐透作为一种常见的彩票游戏,其开奖数据对于彩票爱好者和数据分析师来说具有重要意义。我们将通过编写一个爬虫程序,自动获取大乐透的开奖信息,并将其保存为结构化的数据以供进一步分析和处理。
2. 技术选型
在实现这个爬虫程序的过程中,我们选择使用Python编程语言以及以下关键技术:
- Selenium:用于模拟浏览器行为,实现页面交互和数据提取。
- Pandas:用于数据处理和存储,方便后续分析和展示。
3.反爬机制
- 需要获取的源代码存在于frame框架中:使用selenium的**switch_to.frame()**方法

- 需要等待页面加载完成才能获取新页面的源代码
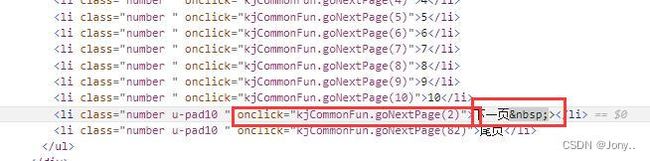
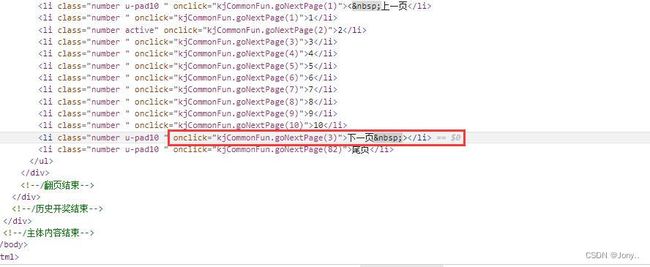
- 下一页按钮是随着页面变化的
4. 程序实现步骤
以下是我们实现大乐透爬虫程序的主要步骤:
- 导入所需的Python库和模块,并设置格式。
import time
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
from selenium.webdriver.support.wait import WebDriverWait
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来显示负号
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False)
- 初始化Selenium WebDriver,指定浏览器类型和驱动路径。
# 创建浏览器操作对象
path = Service('msedgedriver.exe')
# 不会自动关闭
options = webdriver.EdgeOptions()
options.add_argument(
'User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67')
# 使浏览器的window.navigator.webdriver的属性为false
# option.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option('detach', True)
browser = webdriver.Edge(service=path, options=options)
- 打开目标网页,定位到包含开奖信息的frame标签,并获取第一页的源代码。
url = 'https://www.lottery.gov.cn/kj/kjlb.html?dlt'
browser.get(url)
frame = browser.find_element(By.XPATH, '//iframe[@id="iFrame1"]')
browser.switch_to.frame(frame)
wait = WebDriverWait(browser, 10)
wait.until(EC.visibility_of_element_located((By.TAG_NAME, "body")))
time.sleep(1)
# 定位下一页按钮
next_page = browser.find_element(By.XPATH, "//li[contains(@class, 'number u-pad10') and "
"@οnclick='kjCommonFun.goNextPage(2)']")
next_page.click()
content = browser.page_source
- 循环执行以下操作:
- 点击下一页按钮,加载并切换到下一页的开奖信息,待全部数据保存后关闭浏览器。
df = pd.DataFrame()
i = 2
while i <= 100:
try:
# 提取表格数据
df = df._append(pd.read_html(content, header=1), ignore_index=True)
# 点击下一页
time.sleep(2) # 等待页面加载完成
next_page = browser.find_element(By.XPATH, "//li[contains(@class, 'number u-pad10') and "
"@οnclick='kjCommonFun.goNextPage(" + str(i + 1) + ")']")
next_page.click()
# 获取下一页的源码
content = browser.page_source
# print(df)
i += 1
except NoSuchElementException:
break
browser.close()
- 把爬取到的数据进行清洗,并写入到csv文件中
# 重命名列名
df.columns = ['期号', '开奖日期', '前1', '前2', '前3', '前4', '前5', '后1', '后2', '一等奖|基本注数',
'一等奖|基本奖金()元',
'一等奖|追加注数', '一等奖|追加奖金()元',
'二等奖|基本注数', '二等奖|基本奖金()元', '二等奖|追加注数', '二等奖|追加奖金()元', '销售额', '奖池奖金',
'开奖公告']
# 筛选目标字段
df = df.drop(
['一等奖|追加奖金()元', '一等奖|基本奖金()元', '二等奖|基本奖金()元', '二等奖|追加奖金()元', '销售额', '奖池奖金',
'开奖公告'], axis=1)
print(df)
df.to_csv('大乐透.csv', header=True, index=False, encoding='utf-8')
5. 数据分析和展示
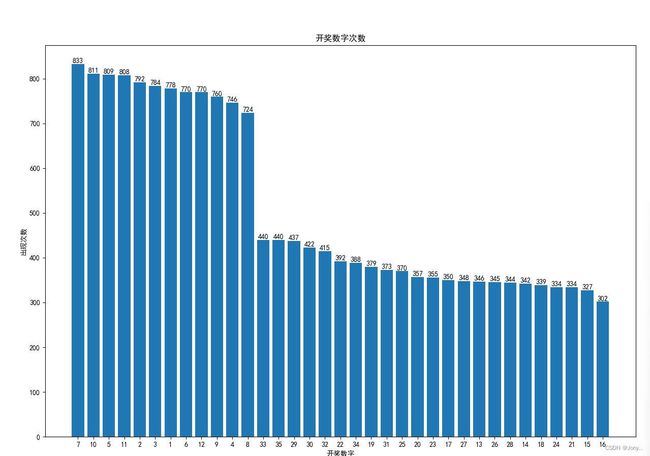
通过以上步骤,我们成功地获取了大乐透近2500期的开奖信息,并将其保存为CSV文件。接下来,我们可以利用Pandas对数据进行分析、统计和可视化,以揭示其中的模式和趋势。我们可以计算每个号码的出现频率。
df1 = pd.read_csv('./大乐透.csv')
number_counts = pd.concat([df1['前1'], df1['前2'], df1['前3'], df1['前4'], df1['前5'], df1['后1'], df1['后2']]).value_counts()
print(number_counts)
# 绘制柱状图
plt.figure(figsize=(15, 10))
# 把出现的数字作为x轴标签
x_labels = number_counts.index.astype(str).tolist()
# 添加数字标签
for i, v in enumerate(number_counts.values.flatten()):
plt.text(i, v, str(v), ha='center', va='bottom')
plt.bar(x_labels, number_counts.values.flatten())
# 设置图表标题和标签
plt.title('开奖数字次数')
plt.xlabel('开奖数字')
plt.ylabel('出现次数')
# 显示图表
plt.show()
6. 总结
本文介绍了如何使用Python编写一个爬虫程序,通过Selenium和Pandas实现了大乐透开奖信息的自动化获取和存储。通过这个实践项目,我们学习了如何处理网页加载和元素定位的问题,并利用Pandas对数据进行处理和分析。爬虫技术为我们提供了获取大量数据的便利,为数据驱动的决策和分析提供了基础。
如果你对此感兴趣,你可以自己动手尝试编写这个爬虫程序,并进行更多的数据分析和探索。希望本文对你在Python爬虫和数据分析方面的学习和实践有所帮助。
文末:本文仅供学习使用,不支持任何商业或投资用途!
理网页加载和元素定位的问题,并利用Pandas对数据进行处理和分析。爬虫技术为我们提供了获取大量数据的便利,为数据驱动的决策和分析提供了基础。
如果你对此感兴趣,你可以自己动手尝试编写这个爬虫程序,并进行更多的数据分析和探索。希望本文对你在Python爬虫和数据分析方面的学习和实践有所帮助。
文末:本文仅供学习使用,不支持任何商业或投资用途!