Python读写word文档
目录
前言
一、环境搭建
二、Word文档的读取
1.导入所需要的库
2.读取文档并提取段落数
3.读取docx中的段落文本内容
4.读取docx中的表格内容
三、Word文件的写入
保存文件
总结
前言
Word文档与其他纯文本文档的比较:
和纯文本文档相比,word种含有各种格式和样式,需要设置字体格式和大小、颜色,加粗等,段落间距行距等,其中还会涉及图表、公式等插入与调整。
run对象
一个Run对象是具有相同格式的文本,当发生变化的时候就需要一个新的Run对象。例如:共计6个run对象的文本:
AVL Cruise是AVL公司开发的一款整车及动力总成仿真分析软件。它可以研究整车的动力性、燃油经济性、排放性能及制动性能,是车辆系统的集成开发平台。AVL Cruise软件已经成功的在整车生产商和零部件供应商之间搭建起了沟通的桥梁。
第0个Run对象文本: AVL Cruise
第1个Run对象文本: 是
第2个Run对象文本: AVL
第3个Run对象文本: 公司开发的一款整车及动力总成仿真分析软件。它可以研究整车的动力性、燃油经济性、排放性能及制动性能,是车辆系统的集成开发平台。
第4个Run对象文本: AVL Cruise
第5个Run对象文本: 软件已经成功的在整车生产商和零部件供应商之间搭建起了沟通的桥梁。
一、环境搭建
读写Word也需要像读写Excel一样导入包,读写Word文档的操作均由python-docx模块,模块直接使用Ppip安装:
pip install python-docx二、Word文档的读取
1.导入所需要的库
import docx # 读取Word文档2.读取文档并提取段落数
doc =docx.Document(r'C:/Users/ypzhao/Desktop/训练/test.docx')
# 读取docx文件中的内容
print(len(docx.paragraphs))#输出总的段落数
3.读取docx中的段落文本内容
# 读取word文档中的第一段内容
print(docx.paragraphs[0].text)
'''指定word某几段内容读取'''
for i in range(2,5):
print(docx.paragraphs[i].text)
'''读取word种所有内容读取'''
for paragraph in docx.paragraphs:
print(paragraph.text)4.读取docx中的表格内容
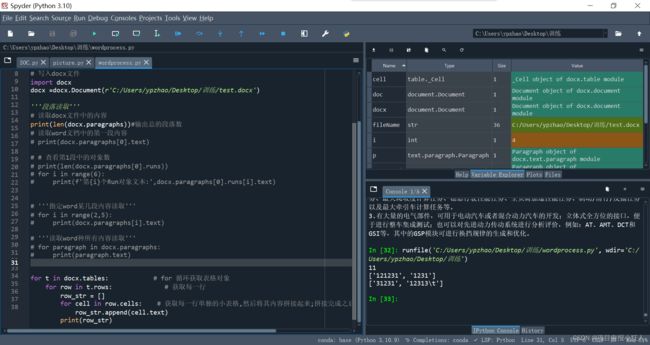
for t in docx.tables: # for 循环获取表格对象
for row in t.rows: # 获取每一行
row_str = []
for cell in row.cells:
row_str.append(cell.text)
print(row_str)运行结果:
三、Word文件的写入
- 换行
# 换行
para = docx.add_paragraph().add_run('\n')- word中表格写入
list1 = [
["语文","数学","英语"],
["100","100","100"],
["100","100","100"],
["100","100","100"],
["100","100","100"]
]
list2 = [
["政治","历史","地理"],
["100","100","100"],
["100","100","100"],
["100","100","100"],
["100","100","100"]
]
table1 = docx.add_table(rows=5,cols=3)
for row in range(5):
cells = table1.rows[row].cells
for col in range(3):
cells[col].text = str(list1[row][col])
table2 = docx.add_table(rows=4,cols=3)
for row in range(4):
cells = table2.rows[row].cells
for col in range(3):
cells[col].text = str(list2[row][col])
t = docx.tables[1]
workbook = Workbook()
sheet = workbook.active
for i in range(len(t.rows)):
list1 = []
for j in range(len(t.columns)):
list1.append(t.cell(i,j).text)
sheet.append(list1)
workbook.save("table1.xlsx")-
保存文件
docx.save('test.docx')完整代码
# -*- coding: utf-8 -*-
"""
Created on Sun May 7 14:22:49 2023
@author: ypzhao
"""
# 写入docx文件
import docx
# 设置图片格式
from docx.shared import Cm
from openpyxl import Workbook
from docx import Document
from docx.shared import Pt, RGBColor
from docx.oxml.ns import qn
docx =docx.Document(r'C:/Users/ypzhao/Desktop/训练/test.docx')
'''段落读取'''
# 读取docx文件中的内容
print(len(docx.paragraphs))#输出总的段落数
# 读取word文档中的第一段内容
print(docx.paragraphs[0].text)
# 查看第1段中的对象数
print(len(docx.paragraphs[0].runs))
for i in range(6):
print(f'第{i}个Run对象文本:',docx.paragraphs[0].runs[i].text)
'''指定word某几段内容读取'''
for i in range(2,5):
print(docx.paragraphs[i].text)
'''读取word种所有内容读取'''
for paragraph in docx.paragraphs:
print(paragraph.text)
for t in docx.tables: # for 循环获取表格对象
for row in t.rows: # 获取每一行
row_str = []
for cell in row.cells: # 获取每一行单独的小表格,然后将其内容拼接起来;拼接完成之后再第二个for循环中打印出来
row_str.append(cell.text)
print(row_str)
p1 = docx.add_paragraph('这是一个段落')
# 加粗
p1.add_run('加粗的一句话').bold = True
# 斜体
p1.add_run("这句是斜体文字块").italic = True
docx.add_paragraph('这是第二个段落')
docx.add_paragraph('这是一个段落,后面带图片')
'''
Cm 模块,用于设定图片尺寸大小
只给定一个宽度或高度
'''
docx.add_picture('electric vehicle.png',width=Cm(14),height=Cm(7))
docx.add_paragraph('这是第二个段落')
# 分页
docx.add_page_break()
paragraph1 = docx.add_paragraph("这是新增的一页")
Document().add_heading('正文',1).add_run("前言")
Document().add_heading('标题',2)
'''添加表格'''
# 换行
para = docx.add_paragraph().add_run('\n')
# 换行
para = docx.add_paragraph().add_run('\n')
# 换行
para = docx.add_paragraph().add_run('\n')
# 换行
para = docx.add_paragraph().add_run('\n')
list1 = [
["语文","数学","英语"],
["100","100","100"],
["100","100","100"],
["100","100","100"],
["100","100","100"]
]
list2 = [
["政治","历史","地理"],
["100","100","100"],
["100","100","100"],
["100","100","100"],
["100","100","100"]
]
table1 = docx.add_table(rows=5,cols=3)
for row in range(5):
cells = table1.rows[row].cells
for col in range(3):
cells[col].text = str(list1[row][col])
docx.add_paragraph("---------------------------------------------------------")
table2 = docx.add_table(rows=4,cols=3)
for row in range(4):
cells = table2.rows[row].cells
for col in range(3):
cells[col].text = str(list2[row][col])
t = docx.tables[1]
workbook = Workbook()
sheet = workbook.active
for i in range(len(t.rows)):
list1 = []
for j in range(len(t.columns)):
list1.append(t.cell(i,j).text)
sheet.append(list1)
workbook.save("table1.xlsx")
docx.save('test.docx')
提示:下期再见!