YOLO物体检测-系列教程4:YOLOV3项目实战1之 整体介绍与数据处理 (coco图像数据集/darknet预训练模型)
YOLO 系列教程 总目录
上篇内容:
YOLOV3整体解读
YOLOV3提出论文:《Yolov3: An incremental improvement》
1、整体项目
1.1 环境
- 一个有debug功能的IDE,建议Pycharm
- PyTorch深度学习开发环境
- 下载COCO数据集:
- 训练集,是很大的数据
- 验证集,是很大的数据
1.2 数据
依次进入以下地址:
项目位置\PyTorch-YOLOv3\data\coco\images,一共有两个文件:

进入训练集:
训练集有8万张图片,验证集有4万张。
进入标签数据中(项目位置\PyTorch-YOLOv3\data\coco\labels\labels\train2014):
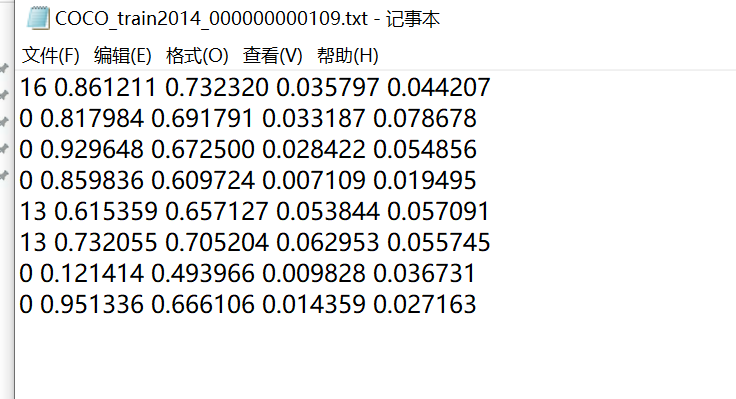
随便打开一个,记录的都是坐标:
选中标签文件的名字,在数据中搜索,可以搜索到对应的:

也就是说数据和标签的名字都是一一对应的。
如图所示,当前的图片,在标签中有8行数据,意味着图片中有8个物体被框住,而且已经被标注了位置(对角线两个点的坐标确定了框)
在这里还有一个文件:trainvalno5k.txt,记录了所有训练数据的路径,这是读数据的路径
1.3 配置文件
在这里有一个配置文件:项目位置\PyTorch-YOLOv3\config\yolov3.cfg
主要包括了一些参数,还有所有网络模型的结构的参数:
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
最后还有一个yolo层,9个候选框:
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
2、配置运行参数:
需要指定以下参数才能运行(新版pycharm配置运行参数教程):
–data_config config/coco.data
–pretrained_weights weights/darknet53.conv.74
pretrained_weights weights/darknet53.conv.74,表示用一个已经预训练的模型做初始化操作。
在这里有一个coco.data文件:项目位置\PyTorch-YOLOv3\config\coco.data
classes= 80
train=data/coco/trainvalno5k.txt
valid=data/coco/5k.txt
names=data/coco.names
backup=backup/
eval=coco
这个文件记录了当前训练所有需要的信息,比如:
- 80分类任务
- 训练数据(存了训练数据路径的文件)
- 验证数据
简要流程介绍:
- 配置所有参数
- 模型构造(模型怎么定义的,前向传播是怎么走的)
- 读进预训练模型和数据
- 训练
3、数据预处理
如果按照正常流程,把所有数据都读进来再处理,但是我们的数据有10多个G这么大,内存都没有这么大这是无法完成的。所以本次的项目是训练的时候一批一批的读数据处理的,训练的时候实时读进来的。
在uitls/datasets.py文件中,ListDataset类的__getitem__函数。这个函数专门用来读取数据和标签。
3.1 图片填充函数
这个函数的主要功能是将图片填充为一个正方形,并且返回填充后的图像和填充的信息。
def pad_to_square(img, pad_value):
c, h, w = img.shape
dim_diff = np.abs(h - w)
pad1, pad2 = dim_diff // 2, dim_diff - dim_diff // 2
pad = (0, 0, pad1, pad2) if h <= w else (pad1, pad2, 0, 0)
img = F.pad(img, pad, "constant", value=pad_value)
return img, pad
- 传进来一张图片数据,和要填充的值(一般为0)
- 获取通道、长、宽
- 计算长宽的差值的绝对值
- 将dim_diff除以2的商和余数分赋给pad1, pad2
- 这一行代码根据图像的高度和宽度大小确定填充的位置。如果高度小于等于宽度,就在上下两侧填充,否则在左右两侧填充。
pad是一个包含四个元素的元组,表示上、下、左、右四个方向的填充量。 - 用torch的pad方法,将图像添加0
- 返回数值
3.2 数据读取
def __getitem__(self, index):
img_path = self.img_files[index % len(self.img_files)].rstrip()
img_path = '项目地址\\PyTorch\\PyTorch-YOLOv3\\data\\coco' + img_path
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
img, pad = pad_to_square(img, 0)
_, padded_h, padded_w = img.shape
- 函数名,按照索引来读取数据,一张图像一张图像的读数据,所以这个函数一次只读一张图像,和一张图像对应的标签
- 详解
img_path = self.img_files[index % len(self.img_files)].rstrip():self.img_files是一个从ImageFolder类中传进来的list,这个list包含了所有训练图像数据的相对路径len(self.img_files)这个值就是训练数据的图片数- index就是当前读进来数据的索引,
index % len(self.img_files)的意思是,如果index不小心增加到了超过len(self.img_files)的数,就进行取余操作,所以大部分情况self.img_files[index % len(self.img_files)].rstrip()和self.img_files[index].rstrip()是等价的 - 获取了一张图片的路径,.rstrip()将路径的末尾的空格全部去掉,一般不会有空格
- 现在得到的是一张图像的相对路径, 还是在前面加上绝对路径,因为容易出错
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))Image.open(img_path)根据图像路径读进来这张图像Image.open(img_path).convert('RGB'))读进来的是BGR,转换为RGBimg = transforms.ToTensor()(Image.open(img_path).convert('RGB'))转化为PyTorch的Tensor的格式
- 判断数据是不是三维的,如果不是就是一个灰度图
- 增加一个维度,将形状从(高度,宽度)变为(1,高度,宽度),将灰度图转化为具有单通道的彩色表示,在第一个维度上复制图像,使其有三个维度
- 获取长和宽
self.normalized_labels表示是否需要对目标标签的坐标信息进行归一化(缩放)的形式以适应调整后的图像。,如果self.normalized_labels为True,h_factor, w_factor用(h,w)赋值,表示用原始图像的高度和宽度作为缩放因子,否则用(1,1)赋值,表示不用缩放。- 使用pad_to_square函数,给图像加上padding
- 获取加上了padding后的图像的长宽
3.3 标签读取
label_path = self.label_files[index % len(self.img_files)].rstrip()
label_path = 'E:\\eclipse-workspace\\PyTorch\\PyTorch-YOLOv3\\data\\coco\\labels' + label_path
- 和前面一样的读取数据的方式,读取标签数据
if os.path.exists(label_path):
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
- 读进来标签的路径
np.loadtxt(label_path)标签文件的每一行包含了对象的类别标签和四个与对象位置相关的值,这五个值由空格或其他分隔符分开,(np.loadtxt(label_path).reshape(-1, 5))参数-1表示自动计算这个维度的大小,以确保总的元素数量不变。在这里,它被用于确保每行包含5个值(一个类别标签和四个坐标值),torch.from_numpy(...):将 NumPy 数组转换为 PyTorch 张量- 接下来的一系列操作是根据缩放因子和填充信息,对目标的坐标信息进行调整,以适应填充后的图像,这部分代码的目的是根据图像的缩放因子
w_factor和h_factor以及填充信息pad来调整目标标签的坐标信息,以适应调整后的图像。这通常用于确保目标标签的坐标信息与图像的尺寸相匹配。详细解释这个过程:x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2):这一行代码计算了目标标签框左上角 x 坐标(x1)。boxes[:, 1]包含了原始标签数据中每个目标框的中心 x 坐标,而boxes[:, 3]包含了每个目标框的宽度。通过这两者的计算,得到了左上角 x 坐标。然后,将x1乘以w_factor来缩放 x 坐标以适应调整后的图像尺寸。y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2):类似地,这一行代码计算了目标标签框左上角 y 坐标(y1)。boxes[:, 2]包含了原始标签数据中每个目标框的中心 y 坐标,而boxes[:, 4]包含了每个目标框的高度。通过这两者的计算,得到了左上角 y 坐标。然后,将y1乘以h_factor来缩放 y 坐标以适应调整后的图像尺寸。x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)和y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2):这两行代码分别计算了目标标签框右下角的 x 坐标(x2)和 y 坐标(y2)。通过将中心坐标和宽度、高度信息相加或相减,得到了右下角的坐标。然后,分别乘以w_factor和h_factor以进行缩放。x1 += pad[0]、y1 += pad[2]、x2 += pad[1]、y2 += pad[3]:这四行代码将计算得到的坐标信息与填充信息pad相加,以考虑到图像的填充。填充信息pad包含了上、下、左、右四个方向的填充量,用于调整坐标信息以适应填充后的图像。boxes[:, 1] = ((x1 + x2) / 2) / padded_w和boxes[:, 2] = ((y1 + y2) / 2) / padded_h:这两行代码计算了目标标签框的中心坐标,并将其除以填充后的图像的宽度(padded_w)和高度(padded_h)来进行归一化,以确保坐标信息相对于图像的尺寸在0到1之间。boxes[:, 3] *= w_factor / padded_w和boxes[:, 4] *= h_factor / padded_h:这两行代码将目标标签框的宽度和高度分别乘以缩放因子,以将它们调整为填充后的图像的尺寸。- 最终,
boxes张量中包含了经过缩放和填充调整后的目标标签信息,包括类别标签、归一化的中心坐标、归一化的宽度和高度。这些调整后的标签信息将用于目标检测模型的训练。
targets = torch.zeros((len(boxes), 6)):创建一个零填充的张量用于存储目标信息。每个目标包括一个类别标签和一些坐标信息,所以这个张量的形状是(目标数量, 6),len(boxes)表示目标的数量targets[:, 1:] = boxes:这一行代码将经过调整的目标标签数据boxes复制到targets张量中。具体来说,它将boxes张量的所有列(除了第一列,即类别标签列)复制到targets张量的所有列中。这样做是为了将目标标签信息放入targets张量中,其中第一列将保持为零,因为目前还没有指定类别标签。最终,targets张量中包含了每个目标的标签信息,包括类别标签和坐标信息,可以用于目标检测模型的训练。这种格式通常在目标检测任务中使用,其中每行表示一个检测到的目标,第一列通常用于表示目标的类别标签,而后面的列包含坐标信息。
3.4 数据增强
3.4.1 数据增强
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets)
return img_path, img, targets
self.augment预设的布尔值,判断是否要进行数据增强操作np.random.random()函数生成一个随机的0到1之间的随机数,检查是否小于0.5。这个检查的目的是随机决定是否执行水平翻转操作。因为0.5的概率是相等的,所以每个图像有50%的概率进行水平翻转。img, targets = horisontal_flip(img, targets)使用horisontal_flip函数进行水平翻转操作return img_path, img, targets返回了三个值,分别是:
1.img_path:这是一个字符串,表示图像文件的路径。它告诉你加载的图像来自哪个文件。
2.img:这是一个 PyTorch 张量,表示加载和处理后的图像数据。通常,这个张量的形状是(通道数, 高度, 宽度),它包含了图像的像素值,可以用于输入深度学习模型进行训练或推断
3.targets:这是一个 PyTorch 张量,表示加载和处理后的目标标签信息。它的形状通常是(目标数量, 6),其中每行包含一个检测到的目标的标签信息,包括类别标签和坐标信息。这个张量用于训练目标检测模型,以告诉模型在图像中哪些区域包含了目标物体以及它们的类别和位置
4. 因此,这个函数返回了图像文件路径、图像数据以及目标标签信息,这些数据通常被用于训练目标检测模型。
3.4.2 水平翻转函数
def horisontal_flip(images, targets):
images = torch.flip(images, [-1])
targets[:, 2] = 1 - targets[:, 2]
return images, targets
- 获取图像数据和标签信息数据
- 使用torch的flip函数进行水平反正操作,
[-1]表示在最后一个维度(通常是图像的宽度维度)上进行翻转,即将图像从左到右翻转。 targets[:, 2] = 1 - targets[:, 2]:这一行代码用于调整目标标签的坐标信息,以反映图像的水平翻转。具体地,它修改了目标标签中所有行的第3列(通常是y坐标)的值。通过计算1 - targets[:, 2],它将原始的y坐标值从图像的底部翻转到图像的顶部。- 将翻转的信息返回
下篇内容:
YOLOV3项目实战2