python3 线程池 ThreadPoolExecutor 简介
前言
从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类。
相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值:
- 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
- 当一个线程完成的时候,主线程能够立即知道。
- 让多线程和多进程的编码接口一致。
线程池的基本使用
# coding: utf-8
from concurrent.futures import ThreadPoolExecutor
import time
def spider(page):
time.sleep(page)
print(f"crawl task{page} finished")
return page
with ThreadPoolExecutor(max_workers=5) as t: # 创建一个最大容纳数量为5的线程池
task1 = t.submit(spider, 1)
task2 = t.submit(spider, 2) # 通过submit提交执行的函数到线程池中
task3 = t.submit(spider, 3)
print(f"task1: {task1.done()}") # 通过done来判断线程是否完成
print(f"task2: {task2.done()}")
print(f"task3: {task3.done()}")
time.sleep(2.5)
print(f"task1: {task1.done()}")
print(f"task2: {task2.done()}")
print(f"task3: {task3.done()}")
print(task1.result()) # 通过result来获取返回值
执行结果如下:
task1: False
task2: False
task3: False
crawl task1 finished
crawl task2 finished
task1: True
task2: True
task3: False
1
crawl task3 finished
-
使用 with 语句 ,通过 ThreadPoolExecutor 构造实例,同时传入 max_workers 参数来设置线程池中最多能同时运行的线程数目。
-
使用 submit 函数来提交线程需要执行的任务到线程池中,并返回该任务的句柄(类似于文件、画图),注意 submit() 不是阻塞的,而是立即返回。
-
通过使用 done() 方法判断该任务是否结束。上面的例子可以看出,提交任务后立即判断任务状态,显示四个任务都未完成。在延时2.5后,task1 和 task2 执行完毕,task3 仍在执行中。
-
使用 result() 方法可以获取任务的返回值。
主要方法:
wait
wait(fs, timeout=None, return_when=ALL_COMPLETED)
wait 接受三个参数:
fs: 表示需要执行的序列
timeout: 等待的最大时间,如果超过这个时间即使线程未执行完成也将返回
return_when:表示wait返回结果的条件,默认为 ALL_COMPLETED 全部执行完成再返回
还是用上面那个例子来熟悉用法
示例:
from concurrent.futures import ThreadPoolExecutor, wait, FIRST_COMPLETED, ALL_COMPLETED
import time
def spider(page):
time.sleep(page)
print(f"crawl task{page} finished")
return page
with ThreadPoolExecutor(max_workers=5) as t:
all_task = [t.submit(spider, page) for page in range(1, 5)]
wait(all_task, return_when=FIRST_COMPLETED)
print('finished')
print(wait(all_task, timeout=2.5))
# 运行结果
crawl task1 finished
finished
crawl task2 finished
crawl task3 finished
DoneAndNotDoneFutures(done={, , }, not_done={})
crawl task4 finished
- 代码中返回的条件是:当完成第一个任务的时候,就停止等待,继续主线程任务
- 由于设置了延时, 可以看到最后只有 task4 还在运行中
as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。最好的方法是当某个任务结束了,就给主线程返回结果,而不是一直判断每个任务是否结束。
ThreadPoolExecutorThreadPoolExecutor 中 的 as_completed() 就是这样一个方法,当子线程中的任务执行完后,直接用 result() 获取返回结果
用法如下:
# coding: utf-8
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def spider(page):
time.sleep(page)
print(f"crawl task{page} finished")
return page
def main():
with ThreadPoolExecutor(max_workers=5) as t:
obj_list = []
for page in range(1, 5):
obj = t.submit(spider, page)
obj_list.append(obj)
for future in as_completed(obj_list):
data = future.result()
print(f"main: {data}")
# 执行结果
crawl task1 finished
main: 1
crawl task2 finished
main: 2
crawl task3 finished
main: 3
crawl task4 finished
main: 4
as_completed() 方法是一个生成器,在没有任务完成的时候,会一直阻塞,除非设置了 timeout。
当有某个任务完成的时候,会 yield 这个任务,就能执行 for 循环下面的语句,然后继续阻塞住,循环到所有的任务结束。同时,先完成的任务会先返回给主线程。
map
map(fn, *iterables, timeout=None)
fn: 第一个参数 fn 是需要线程执行的函数;
iterables:第二个参数接受一个可迭代对象;
timeout: 第三个参数 timeout 跟 wait() 的 timeout 一样,但由于 map 是返回线程执行的结果,如果 timeout小于线程执行时间会抛异常 TimeoutError。
用法如下:
import time
from concurrent.futures import ThreadPoolExecutor
def spider(page):
time.sleep(page)
return page
start = time.time()
executor = ThreadPoolExecutor(max_workers=4)
i = 1
for result in executor.map(spider, [2, 3, 1, 4]):
print("task{}:{}".format(i, result))
i += 1
# 运行结果
task1:2
task2:3
task3:1
task4:4
使用 map 方法,无需提前使用 submit 方法,map 方法与 python 高阶函数 map 的含义相同,都是将序列中的每个元素都执行同一个函数。
上面的代码对列表中的每个元素都执行 spider() 函数,并分配各线程池。
可以看到执行结果与上面的 as_completed() 方法的结果不同,输出顺序和列表的顺序相同,就算 1s 的任务先执行完成,也会先打印前面提交的任务返回的结果。
实战
以某网站为例,演示线程池和单线程两种方式爬取的差异
# coding: utf-8
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
import json
from requests import adapters
from proxy import get_proxies
headers = {
"Host": "splcgk.court.gov.cn",
"Origin": "https://splcgk.court.gov.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"Referer": "https://splcgk.court.gov.cn/gzfwww/ktgg",
}
url = "https://splcgk.court.gov.cn/gzfwww/ktgglist?pageNo=1"
def spider(page):
data = {
"bt": "",
"fydw": "",
"pageNum": page,
}
for _ in range(5):
try:
response = requests.post(url, headers=headers, data=data, proxies=get_proxies())
json_data = response.json()
except (json.JSONDecodeError, adapters.SSLError):
continue
else:
break
else:
return {}
return json_data
def main():
with ThreadPoolExecutor(max_workers=8) as t:
obj_list = []
begin = time.time()
for page in range(1, 15):
obj = t.submit(spider, page)
obj_list.append(obj)
for future in as_completed(obj_list):
data = future.result()
print(data)
print('*' * 50)
times = time.time() - begin
print(times)
if __name__ == "__main__":
main()
运行结果如下:
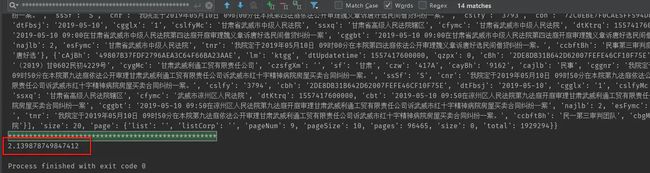
多线程
可以看到,14 页只花了 2 秒钟就爬完了
下面我们可以使用单线程来爬取,代码基本和上面的一样,加个单线程函数
代码如下:
def single():
begin = time.time()
for page in range(1, 15):
data = spider(page)
print(data)
print('*' * 50)
times = time.time() - begin
print(times)
if __name__ == "__main__":
single()
运行结果:
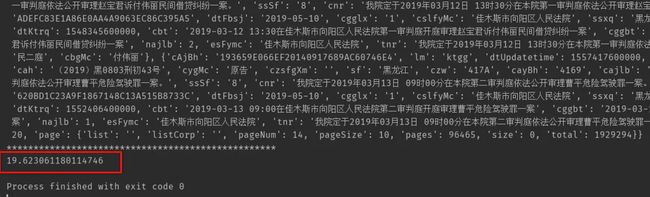
单线程
可以看到,总共花了 19 秒。真是肉眼可见的差距啊!如果数据量大的话,运行时间差距会更大!