一、知识点总结
注:期中知识点总结归纳了教材第一、二、三、四、六、七章的重点内容和Linux命令man、cheat、grep、vi、gcc、gdb、make的使用,详细知识点内容请见前六篇博客。
(一)第一章 计算机系统漫游
1. 信息=位+上下文。
2. 翻译过程分为四个阶段:预处理、编译、汇编、链接,预处理器、编译器、汇编器、链接器一起构成编译系统。
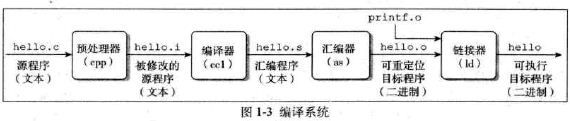
3. 系统的硬件组成:总线、I/O设备、内存、处理器。
4. 并发:一个同时具有多个活动的系统。并行:用并发使一个系统运行地更快,并行可以在计算机系统多个抽象层次上运用。按照系统层次结构由高到低的顺序强调三个层次:线程级并发、指令级并行、单指令多数据并行。
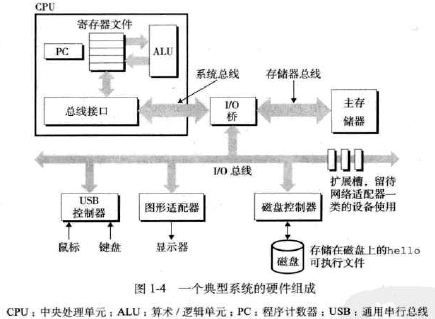
5. 操作系统内核是应用程序和硬件之间的媒介,提供三个基本的抽象:
-
文件是对I/O设备的抽象
-
虚拟存储器是对主存和磁盘的抽象
-
进程是对处理器、主存和I/O设备的抽象
6. 计算机系统是由硬件和系统软件组成的,程序被其他程序翻译成不同的形式,开始时是ASCII文本,然后被编译器和链接器翻译成二进制可执行文件。
7. 处理器读取并解释存放在主存里的二进制指令。
(二)第二章 信息的表示和处理
1. 字长:指明整数和指针数据的标称大小。一个字长为w的机器的虚拟地址范围为0~2^(w-1),程序最多访问2^w个字节。
2. int 、char 4字节,单精度float 字节,双精度double 8字节。
3. 三种最重要的数字表示:无符号、补码、浮点数。
4. 运算:整数运算、浮点运算。
5. 小端法和大端法
-
小端法:最低有效字节在前面——“高对高,低对低”
-
大端法:最高有效字节在前面
6.布尔代数:
- 与: &
- 或: |
- 非: ~
- 异或:^
7. 逻辑运算符
- 与:&&
- 或:||
- 非:!
8. 逻辑运算和位运算的区别
- 只有当参数被限制为0或1时,逻辑运算才与按位运算有相同的行为。
- 如果对第一个参数求值就能确定表达式的结果,逻辑运算符就不会对后面的参数求值。
9. 移位运算
- 逻辑右移:在左端补k个0,多用于无符号数移位运算
- 算术右移:在左端补k个最高有效位的值,多用于有符号数移位运算。
10. 有符号数和无符号数的转换
(1)有符号数→无符号数:
- 非负数——保持不变
- 负数——转换成大正数
(2)无符号数→有符号数:
- 小于2的w-1次方——保持不变
- 大于2的w-1次方——转换为负数值
11.扩展
- 零扩展:多用于无符号数转换为一个更大的数据类型,只需在开头加上0即可。
- 符号扩展:多用于补码数字转换,最高有效位是什么,就添加什么。
12.截断数字
将一个w位的数截断为k位数字时,就会丢弃高w-k位。
- 对于无符号数来说,就相当于 mod 2的k次幂
- 对于有符号数来说,先按照无符号数截断,然后再转化为有符号数
13.舍入
- 向偶舍入:将数字向上或向下舍入,是的结果的最低有效数字为偶数。能用于二进制小数。
- 向零舍入:把整数向下舍入,负数向上舍入。
- 向下舍入:正数和负数都向下舍入。
- 正数和负数都向上舍入。
(三)第三章 程序的机器级表示
1. GCC将源代码转化为可执行代码的步骤
- C预处理器——扩展源代码-生成.i文件
- 编译器——产生两个源代码的汇编代码-——生成.s文件
- 汇编器——将汇编代码转化成二进制目标代码——生成.o文件
- 链接器——产生可执行代码文件
2. 几个处理器
- 程序计数器(CS:IP)
- 整数寄存器(AX,BX,CX,DX)
- 条件码寄存器(OF,SF,ZF,AF,PF,CF)
- 浮点寄存器
3. 数据格式
(1)Intel:
8 位:字节
16位:字
32位:双字
64位:四字
(2)c语言基本数据类型对应的IA32表示:
char 字节 1字节
short 字 2字节
int 双字 4字节
long int 双字 4字节
long long int (不支持) 4字节
char * 双字 4字节
float 单精度 4字节
double 双精度 8字节
long double 扩展精度 10/12字节
4. 操作数类型:立即数、寄存器、存储器
5. 寻址方式
(1)立即数寻址方式
格式:$后加用标准c表示法表示的整数,如$0xAFF
(2)寄存器寻址方式
如%eax,与汇编中学过的AX寄存器类比。
(3)存储器寻址方式
- 直接寻址方式
- 寄存器间接寻址方式
- 寄存器相对寻址方式
- 基址变址寻址方式
- 相对基址变址寻址方式
6. 数据传送指令
- mov指令
- 入栈push
- 出栈pop
7. 条件码
- CF:进位标志
- ZF:零标志
- SF:符号标志
- OF:溢出标志
8. 循环
- do while
- while
- for
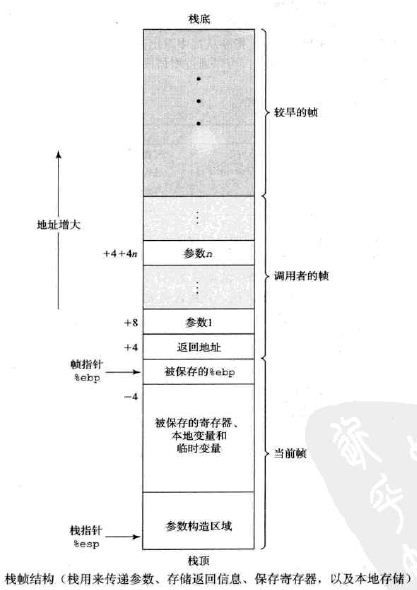
9. 栈帧
- 寄存器%ebp-帧指针,寄存器%esp-栈指针
- 栈用来传递参数、存储返回信息、保存寄存器,以及本地存储。
10. 转移控制
- call:CALL指令的效果是将返回地址入栈,并跳转到被调用过程的起始处。返回地址是还在程序中紧跟在call后面的那条指令的地址。
- ret:指从栈中弹出地址,并跳转到这个位置。
- leave可以使栈做好返回的准备
11. 指针
- 每个指针都对应一个类型
- 每个指针都有一个值
- 指针用&运算符创建
- 运算符*用于指针的间接引用
- 数组与指针紧密联系
- 将指针从一种类型强制转换成另一种类型,只改变它的类型而不改变它的值
- 指针也可以指向函数
(四)第四章 处理器体系结构
1. Y86指令集
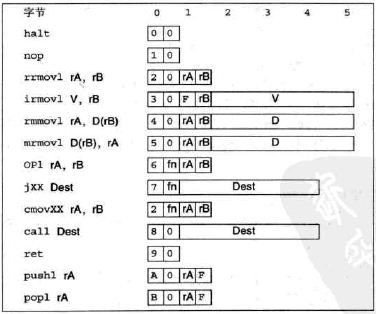
- 4个整数操作指令:addl、subl、andl、xorl
- 7个跳转指令:jmp、jle、jl、je、jne、jge、jg
- 6个条件传送指令:cmovle、cmovl、cmove、cmovne、cmovge、cmovg
- Halt指令停止指令的执行
2. 逻辑设计和硬件控制语言HCL
- 逻辑门:&&、|| 、!
- 字级的组合电路和HCL整数表达式:一些位级信号代表一个整数或一些控制模式。执行字级计算的组合电路根据输入字的各个位,用逻辑门来计算输出字的各个位。
-
两类存储器设备
时钟寄存器(简称寄存器):存储单个位或字,时钟信号控制寄存器加载输入值
随机访问存储器(简称存储器):存储多个字,用地址来选择该读或该写哪个字
3. Y86的顺序实现
- 取指:取指阶段从存储器读取指令字节,地址为程序计数器PC的值
- 译码:译码阶段从寄存器文件读入最多两个操作数
- 执行:在执行阶段,算数/逻辑单元要么根据ifun的值执行指令指明的操作,计算机存储器引用的有效地址,要么增加或减少栈指针
- 访存:访存阶段可以将数据写入存储器,或从存储器读出数据
- 写回:写回阶段最多可以写两个结果到寄存器文件
- 更新PC:将PC设置成下一条指令的地址
4. SEQ阶段的实现
-
取指阶段
取指阶段包括指令存储器硬件单元。以PC作为第一个字节(字节0)的地址,这个单元一次从存储器读出6个字节,第一个字节被解释称指令字节,分为两个4位数。标号为“icode”和“ifun”的控制逻辑块计算指令和功能码等于从存储器读出值,或者当指令地址不合法时(imem_error指明),这些值对应于nop指令。
-
译码和写回阶段
都要访问寄存器文件。寄存器文件有四个端口,支持同时进行两个读(端口A、B)和两个写(E、M),每个端口都有一个地址连接和一个数据连接。根据指令代码icode以及寄存器指示值rA和rB,可能还会根据执行阶段计算出的Cnd条件信号。
-
执行阶段
执行阶段包括算术/逻辑单元(ALU)第一步每条指令的ALU计算,执行阶段还包括条件码寄存器。
-
访存阶段
访存阶段的任务是读或者写程序数据,两个控制块产生存储器地址和存储器输入数据的值,另外两个块产生控制信号表明应该执行读操作还是写操作。当执行读操作时数据存储器产生值valM。
-
更新PC阶段
SEQ中最后一个阶段会产生程序计数器的新值,依据指令的类型和是否要选择分支,新的PC可能是valC、valM、valP。
(五)第六章 存储器层次结构
1. 存储器系统是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU寄存器保存着最常用的数据。小而快的高速缓存寄存器靠近CPU,下层存储设备慢而大、便宜。
2. 基本存储技术
- SRAM存储器
- DRAM存储器
- ROM存储器
- 旋转和固态的硬盘
3. 随机访问存贮器:分为静态(SRAM)和动态(DRAM)两类,SRAM更快更贵,用来作为高速缓存存储器。DRAM用来作为主存以及图形系统的帧缓冲区。
- 静态RAM:将每个位存储在一个双稳态的存储器单元里,只要有电就会永远保持它的值。
- 动态RAM:将每个位存储为对一个电容的充电,当电容的电压被干扰后就存储器单元就永远不会恢复了。存储器系统必须周期性地通过读出,然后重写来刷新存储器的每一位。
4. 访问主存:数据流通过称为总线的共享电子电路在处理器和DRAM主存之间来回。读事物 从主存传送数据到CPU,写事物从CPU传送数据到主存。
- 总线是一组并行的导线,能携带地址、数据和控制信号。
- 计算机系统配置:CPU芯片、I/O桥、组成主存的DRAM存储器模块
- 系统总线连接CPU和I/O桥,存储器总线连接I/O桥和主存
5. 磁盘构造:磁盘由盘片构成,每个盘片有两面或称为表面,盘片中央有一个可旋转的主轴,它使盘片以固定的旋转速率旋转。
6. 磁盘容量=字节数/扇区 * 平均扇区数/磁道 * 磁道数/表面 * 表面数/盘片 * 盘片数/磁盘
7. 对扇区的访问时间有三个主要部分:寻道时间、旋转时间、传送时间
- 寻道时间:为了读取某个目标扇区的内容,传动臂首先将读写头定位到包含目标扇区的磁道上。移动传动臂所需的时间称为寻道时间。
- 旋转时间:最大旋转延迟Tmax rotation=1/RPM * 60secs/1min。平均旋转时间Tavg rotation的一半。
- 传送时间:Tavg transfer=1/RPM * 1/(平均扇区数/磁道) * 60secs/1min
- 估计总访问时间=Tavg seek+Tavg rotation+Tavg transfer。因为寻道时间和旋转延迟大致相等,所以将寻道时间乘以2可简单估计磁盘访问时间。
8. 局部性:时间局部性、空间局部性
- 重复引用同一个变量的程序有良好的时间局部性。
- 对于具有步长为k的引用模式的程序,步长越小空间局部性越好。具有步长为1的引用模式的程序有很好的空间局部性。在存储器中以大步长跳来跳去的程序空间局部性很差。
- 对于取指令而言,循环有好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
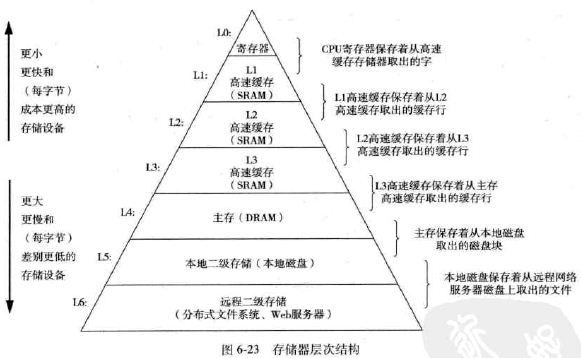
9. 存储器结构
- 高速缓存是一个小而快速的存储设备,它作为存储在更大也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存。
- 存储器层次结构的中心思想:对于每个k,位于k层的更快更小的存储设备作为位于k+1层的更大更慢的存储设备的缓存。
- 缓存命中:当程序需要第k+1层的某个数据对象d时,首先在当前存储于第k层的一个块中查找d,且d刚好缓存在第k层。
- 缓存不命中:当程序需要第k+1层的某个数据对象d时,首先在当前存储于第k层的一个块中查找d,且第k层没有缓存数据对象d。覆盖一个现存的块的过程称为替换或驱逐这个块,被驱逐的这个块也称为牺牲块。决定该替换哪个块由缓存的替换策略控制。
10. 直接映射高速缓存:高速缓存确定一个请求是否命中,然后抽取被请求的字的过程分为三步
- 组选择
- 行匹配
- 字抽取
11. 组相联高速缓存
- 组中的任何一行都能包含任何映射到这个组的存储器块,所以高速缓存必须搜索组中的每一行,寻找一个有效的行,其标记与地址中的标记相匹配。如果高速缓存找到了这样一行就命中,块偏移从这个块中选择一个字,和前面一样。
-
缓存不命中则高速缓存必须从存储器中取出包含这个字的块,如果有一个空行则可以被替换,如果没有空行则必须从中选择一个非空的行,希望CPU不会很快引用这个被替换的行。
(1)最不常用策略
(2)最近最少使用策略
12. 全相联高速缓存:全相联高速缓存中的行匹配和字选择与组相联高速缓存中的一样,主要区别是规模大小的问题。全相联高速缓存只适合做小的高速缓存。
13. 写
-
写命中:
直写:高速缓存更新了它的w拷贝后立即将w的高速缓存块写到紧接着的低一层中。缺点是每次写都会引起总线流量。
写回:尽可能推迟存储器更新,只有当替换算法要驱逐更新过的块时,才把它写到紧接着的低一层中。能显著地减少总线流量,缺点是增加了复杂性。高速缓存必须为每个高速缓存行维护一个额外的修改位,表明这个高速缓存块是否被修改过。
-
写不命中
写分配:加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块。缺点是每次不命中都会导致一个块从低一层传送到高速缓存。
非写分配:避开高速缓存,直接把这个字写到低一层中。直写高速缓存通常是非写分配的,写回高速缓存通常是写分配的。
14. 高速缓存参数的性能影响
- 高速缓存大小的影响:较大的高速缓存可能会提高命中率,使大存储器运行得更快更难,较大的高速缓存可能会增加命中时间。
- 块大小的影响:较大的块能利用程序中可能存在的空间局部性,帮助提高命中率。但对于给定的高速缓存大小,块越大代表高速缓存行数越少,会损害时间局部性比空间局部性更好的程序的命中率。较大的块对不命中处罚也有负面影响。
- 相联度的影响:较高的相联度(E值较大)的优点是降低了高速缓存由于冲突不命中出现抖动的可能性。但较高的相联度成本较高,很难使之速度变快,增加命中时间,增加不命中处罚。
- 写策略的影响:直写高速缓存容易实现,且能独立于高速缓存的写缓冲区,用来更新存储器。读不命中的开销不大,因为不会触发存储器写。另外,写回高速缓存引起的传送较少。一般高速缓存越往下层越可能使用写回。
15. 存储器山
- 一个程序从存储系统中读数据的速率称为读吞吐量或读带宽。
- 每台计算机都有表明他存储器系统的能力特色的唯一的存储器山。
- 目的:使得程序运行在山峰而不是低谷。利用时间局部性,使得频繁使用的字从L1中取出;利用空间局部性,使得尽可能多的字从一个L1高速缓存行中访问到。
(六)第七章 链接
1. 静态链接器主要任务:符号解析、重定位。
2. 目标文件形式:可重定位目标文件、可执行目标文件、共享目标文件。
3. 每个可重定位目标模块m都有一个符号表,它包含m所定义和引用的符号的信息。有三种不同的符号:
-
由m定义并能被其他模块引用的全局符号
-
由其他模块定义并被模块m引用的全局符号
-
只被模块m定义和引用的本地符号
(七)Linux命令
1. man -k
- man -k k1|grep k2|grep 2
2. cheat
- 使用du命令对当前目录下的目录或文件按大小排序 的命令是du -sk *| sort -rn
- To list the content of /path/to/foo.tgz archive using tar ( tar -jtvf /path/to/foo.tgz )
3. grep
- 使用grep查找当前目录下*.c中main函数在那个文件中的命令是grep main *.c
- grep -nr xxx/usr/include 查找宏
- ~/test 文件夹下有很多c源文件,查找main函数在哪个文件中可用命令grep main *.c
4. find
- 查找当前目录下2天前被更改过的文件find . -mtime +2 -type f -print
- 查找当前目录下所有目录的find命令是find . -type d
(八)vi、gcc、gdb、make的使用
1. gcc库选项
-
static 进行静态编译,即链接静态库,禁止使用动态库
-
shared 1.可以生成动态库文件 2.进行动态编译,尽可能地链接动态库,只有当没有动态库时才会链接同名的静态库(默认选项,即可省略)
-
L dir 在库文件的搜索路径列表中添加dir 目录
-
lname 链接称为libname.a(静态库)或者libname.so(动态库)的库文件。若两个库都存在,则根据编译方式(-static 还是-shared)而进行链接
-
$ gcc –g gdb.c -o testgdb 使用gdb调试$ gdb testgdb 启动gdb键入 l命令相当于list命令,从第一行开始列出源码
2. gdb调试器
-
查看文件: 在gdb 中键入“l”(list)就可以查看所载入的文件
-
设置断点: 设置断点是调试程序中一个非常重要的手段,它可以使程序运行到一定位置时暂停。因此,程序员在该位置处可以方便地查看变量的值、堆栈情况等,从而找出代码的症结所在。在gdb 中设置断点非常简单,只需在“b”后加入对应的行号即可
-
查看断点情况: 在设置完断点之后,用户可以键入“info b”来查看设置断点情况
-
运行代码: gdb 默认从首行开始运行代码,键入“r”(run)即可(若想从程序中指定行开始运行,可在r 后面加上行号)
-
查看变量值: 在程序停止运行之后,程序员所要做的工作是查看断点处的相关变量值。在gdb 中键入“p”+变量值即可
-
单步运行: 单步运行可以使用命令“n”(next)或“s”(step),它们之间的区别在于:若有函数调用的时候,“s”会进入该.数而“n”不会进入该函数。
-
(gdb) break 16 设置断点,在源程序第16行处。
- (gdb) break func 设置断点,在函数func()入口处。
- (gdb) info break 查看断点信息。
3. make
- makefile的好处:自动化编译。make是一个命令工具,是一个及时makefile中命令的工具程序。make工具最主要也是最基本的功能就是根据makefile文件中描述的源程序至今的相互关系来完成自动编译、维护多个源文件工程。
-
Makefile的一般写法
test(目标文件): prog.o code.o(依赖文件列表)tab(至少一个tab的位置) gcc prog.o code.o -o test(命令)
4. vi
vi 有3 种模式,分别为命令行模式、插入模式及命令行模式。
(1)命令行模式
用户在用vi 编辑文件时,最初进入的为一般模式。在该模式中用户可以通过上下移动光标进行“删除字符”或“整行删除”等操作,也可以进行“复制”、“粘贴”等操作,但无法编辑文字。
(2)插入模式
只有在该模式下,用户才能进行文字编辑输入,用户按[ESC]可键回到命令行模式。
(3)底行模式
在该模式下,光标位于屏幕的底行。用户可以进行文件保存或退出操作,也可以设置编辑环境,如寻找字符串、列出行号等。
vi的基本流程
(1)进入vi,即在命令行下键入“vi hello”(文件名)。此时进入的是命令行模式,光标位于屏幕的上方
(2)在命令行模式下键入i 进入插入模式
(3)最后,在插入模式中,按“Esc”键,则当前模式转入命令行模式,并在底行行中.入“:wq”(存盘退出)进入底行模式
vi 的各模式功能键
命令行模式常见功能键
i 切换到插入模式,在目前的光标所在处插入输入的文字,已存在的文字会向后退
a 切换到插入模式,并从目前光标所在位置的下一个位置开始输入文字
o 切换到插入模式,且从行首开始插入新的一行
0(数字0) 光标移到本行的开头
G 光标移动到文件的最后
nG 光标移动到第n 行
$ 移动到光标所在行的“行尾”
n 光标向下移动n 行
dd 删除光标所在行
ndd 从光标所在行开始向下删除n 行
yy 复制光标所在行
nyy 复制光标所在行开始的向下n 行
u 恢复前一个动作
插入模式常见功能键
插入模式的功能键只有一个,即按“Esc”键可回到命令行模式。
底行模式常见功能键
:w 将编辑的文件保存到磁盘中
:q 退出vi(系统对做过修改的文件会给出提示)
:q! 强制退出vi(对修改过的文件不作保存)
:wq 存盘后退出
:w [filename] 另存一个名为filename 的文件
:set nu 显示行号,设定之后,会在每一行的前面显示对应行号
:set nonu 取消行号显示二、期中学习总结
信息安全信息设计基础这门课开课以来已经过了半学期,这几个月的时间内,我从一开始对学习方法的不习惯慢慢过渡到逐渐适应的阶段,学习也渐入佳境。目前已经学习了教材第一、二、三、四、六、七章的内容,对于计算机的具体层次结构和数据处理方式有了更深刻的理解。不过我认为我收获最大的不是这方面,而是在不断学习、不断改进中掌握了最适合自己的学习方法,即先阅读课本,将重点内容和不理解的内容记下来,通过网上查阅资料、咨询身边同学解决问题,并且通过实践加深对重点内容的理解记忆,定时回顾从前学过的内容,避免遗忘生疏。这种学习方法不仅适用于系统设计基础这门课,对于其他课程,甚至是工作之后的继续学习也是大有裨益。我相信“元知识”的积累也一定是短暂的大学生涯中最宝贵的财富。
但是,在学习中我仍存在不足的地方亟需改进。比如在遇到问题时觉得自己无法解决就习惯于求助同学和网络资料,很多时候缺少深度钻研、深度思考这个过程,这样导致对于问题的理解不够深刻,过一段时间就很容易忘记。意识到这个问题后,我下定决心在之后的学习生活中都要改变这种懒散的心态,不畏疑难,遇到难题时首先自己积极思考解决方法而不是依赖于他人。
本门课程的学习任务安排方面,我觉得很合适。万事开头难,前面打好基础后在之后的学习中就感觉稍轻松一些。除此之外,我对本门课程有感到疑惑的地方,老师偶尔会在群里发布一些额外小任务或是在课堂上说一些加分项,但是这些加分项太多而我不太清楚这些加分项是属于哪个部分,那个部分的总分足够后多余的分是否会累加到其他项中。而且现在也存在着有些加分项分数很高的同学仍然哄抢题目的情况,或许是他们不知道自己的分数是否已满,索性多多益善,直接导致手速慢一点的同学拿不到家庭作业题目。我觉得如果能将所有加分项、对应分值以及该项目多出分数的处理方法列出来,应该能解决这个问题。谢谢老师!