【学习点滴】游戏后台开发-tx
目录
1.战团匹配算法
自己的思考
2.服务器内存优化
3.高时效的UDP
4.弱联网优化之道
移动网络的特点
原因
解决方式:
1.快链路
2.轻往复
强监控
多异步
5.服务端其他优化手段:
游戏同步
6.DOS攻击和DDOS攻击
7.网络编程中的粘包问题
1.战团匹配算法
原文:https://www.gameres.com/827195.html
其实后来看了一下,原作者也是摘自《2018腾讯移动游戏技术评审标准与实践案例》
游戏中存在跨服战等需求,将一些队伍组成固定规模战团,然后战团之间战斗,战团匹配过程应当尽量高效、快速,同时实现战力均衡。为了实现尽可能公平均衡的战团匹配,直观的做法当然是搜索所有队伍组成固定规模的战团,然而其时间复杂度为指数级,以极高的计算代价换取最优匹配显然是不现实的,因此,战团匹配问题也成为制约服务器性能瓶颈问题。
为此,本文利用压桶法实现了快速组成固定规模为K的战团,在尽量保证匹配战团的战力均衡前提下,将战团匹配的时间复杂度降为O(n)。具体上,当有玩家或队伍(实际中,队伍人数为1到5)申请组成战团时,将其加入队列尾部。然后在游戏的心跳中遍历队列,如果当前遍历的玩家或队伍的人数加上桶里的人数小于等于K,则将当前玩家或队伍加入桶,并从队列中删除;否则新建一个桶,将玩家或队伍加入新桶中。在战团匹配时,找出所有人数为K的桶,将桶里所有玩家的战力值的和设为对应桶的权重值,并以此对所有的满的桶进行排序,每次选择战力值最接近的两个战团进行战力均衡的调整,然后传送到战斗服务器进行战斗。
然而,由于压桶法是为了节省时间而选择的贪心算法,可能会遗漏能组成战团的玩家或队伍,因此在压桶法后,本文采用查表法对剩余的玩家和队伍再次尝试组成固定规模的战团。首先在服务器启动时做些预处理,群举所有能组成两个固定规模战团的组合(队伍人数为一的队伍数目,队伍人数为二的队伍数目,...,队伍人数为五的队伍数目),并存在set里,该步骤是全局唯一的,并且只需要做一次。然后统计剩下的玩家和队伍,计算人数为一、二、...、五的队伍数目。如果剩下的玩家或队伍队伍人数为一到五的队伍数目均大于set中某个元素,则set中该元素表示能组成两个固定规模战团的组合,并从剩下的玩家或队伍中删除。此步骤重复进行,直到剩下的玩家或队伍无法组成两个固定规模的战团。
通过上述方法,本文实现尽可能合理的战团组成,在此之后,为了尽可能实现两个战团战力均衡,本文进一步设计战团玩家调整方法。当两个固定规模的战团组成后,通过查询预先生成的表,调整两个战团里的玩家,使得两个战团的战力尽可能相等,增强战斗刺激性。具体上,首先群举所有的能组成两个固定规模战团的可能,并存在map里,map的key为字符串,key唯一标识战团的构成(队伍人数为一的队伍数目,队伍人数为二的队伍数目,...,队伍人数为五的队伍数目),map的value为一个vector容器,vector中存储当前key拆分成两个固定规模战团的所有可能。当调整两个战团的战力时,通过map查询当前两个战团能重组成的所有两个战团的可能,然后遍历所有的可能,找出两个战团战力最接近的组合。
自己的思考
原文中介绍的算法很精彩,考虑的情况也比较复杂。我自己想了下fifaol3这款游戏的匹配对战方式,应该是比较简单的,尝试分析一下。
玩家点击“排位赛”或者“友谊赛”按钮后会进入对战房间,在房间中可以邀请好友加入,因此在发起对战匹配请求前,我方阵容的情况只有三种:1人、2人、3人。实际上我们可以在服务器维护3个桶分别记录玩家数是1、2、3人的队伍,其中key为队伍中玩家的昵称组合,value为队长的战力(即前场中场后场的能力值,只需要队长的数据是因为对战时使用的是队长的球员阵容)。当玩家发起对战请求时,就在对应的桶里找到战力均衡的两支队伍发起对战。(当然还需要对玩家的排位等级做一些加权影响,因为传奇级的玩家和业余级的玩家对战的话会索然无味,影响游戏体验)。
上面介绍的是最简单的情况,即玩家只进行与自己队伍人数相同的匹配。比较复杂的是房间中只有1人,但是他选择的是2v2或者3v3对战的情况等,这就涉及到不同人数的队伍之间进行临时组队再进行匹配的算法。思考如下:
同样维护3个桶队列,分别表示选择1v1、2v2、3v3的房间,那么这三种房间的人数上限分别为2、4、6。例如当1个单独玩家选择参加3v3时,遍历3v3的桶队列,若发现有一个房间的人数已经为5(为什么会出现5,看下一句话),就直接凑成6人加入,若没有就将此玩家加入桶队列。在每次遍历时,可以将一些零散的房间内的玩家拼在一个房间内,供下一次别人匹配来使用,如将1、1、2人的房间拼凑成一个4人的房间。当然这是一种贪心策略,可能会造成有的玩家等了好久都匹配不上的情况,但是游戏中确实存在等了2分钟都没匹配上的情况-_-。(当然房间中还允许有4个观战者,这种情况先不考虑啦)
2.服务器内存优化
本部分仍然转自https://www.gameres.com/827195.html
2.1 内存统计
在对内存优化之前,需要先确定程序每个模块的内存分配。程序的性能有perf、gprof等分析工具,但内存没有较好的分析工具,因此需要自行统计。在linux下/proc/self(pid)/statm有当前进程的内存占用情况,共有七项:指标vsize虚拟内存页数、resident物理内存页数、share 共享内存页数、text 代码段内存页数,lib 引用库内存页数、data_stack 数据/堆栈段内存页数、dt 脏页数,七项指标的数字是内存的页数,因此需要乘以getpagesize()转换为byte。在每个模块结束后统计vsize的增加,即可知该模块占用的内存大小。
在面向对象开发中,内存的消耗由对象的消耗组成,因此需要统计每个类的成员变量的占用内存大小。使用CLion或者visual studio都可以导出类中定义的所有成员变量,然后在gdb使用命令:
p ((unsigned long)(&((ClassName*)0)->MemberName)),即可打印出类ClassName的成员变量MemberName相对类基地址的偏移,根据偏移从小到大排序后,变量的顺序即为定义的顺序,根据偏移相减即可得出每个成员变量大小,然后优化占用内存大的成员变量。
2.2 内存泄露
内存泄露是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,导致内存一直增长。虽然有valgrind等工具可以检查内存泄露,但valgrind虚拟出一个CPU环境,在该环境上运行,会导致内存增大、效率降低,对于大规模程序,基本无法在valgrind上运行。因此需要自行检查内存泄露,glibc提供的内存管理器的钩子函数可以监控内存的分配、释放。如图2.2.2、2.2.3所示,分别为钩子函数的分配内存和释放内存。因为服务器启动时需要预先分配很多内存,比如内存池,这些内存是在服务器停止时才释放,因此为了避免这些内存的干扰,在服务器启动之后才能开始内存泄露的统计。
首先申请固定大小的vec_stack,记录所有分配的内存,如果有释放,则从vec_stack中删除,最后vec_stack中的元素即为泄露的内存,vec_stack必须为固定大小,否则vector扩容中会有内存分配,也不可以用map,map的红黑树旋转也会有内存分配,会造成干扰;然后通过图2.2.1所示的my_back_hook记录原有的malloc、free;并通过图2.2.2所示的my_init_hook将malloc、free换成自定义的钩子函数。
每次分配内存时,都会进入自定义钩子函数my_malloc_hook中,如图2.2.2所示。在my_malloc_hook中首先通过my_recover_hook将malloc恢复成默认的,否则会造成死递归,然后通过默认的malloc分配大小为size的空间,为了分线程统计内存泄露,还需要对线程号做判断,在stTrace.m_pAttr记录内存分配的地址,m_nSize记录大小,m_szCallTrace记录调用栈,如果vec_stack已满,需要根据m_nSize从大到小排序,如果当前分配内存大于vec_stack记录的最小的分配内存,则替换;如果未满,则直接加入vec_stack,在my_malloc_hook结束时,将malloc替换成自定义的malloc。
每次释放内存时,都会进入自定义钩子函数my_malloc_free中,如图2.2.3所示。在my_malloc_free中首先通过my_recover_hook将free恢复成默认的,否则会造成死递归,对线程号判断,然后在vec_stack中删除对应的分配,并将free替换成自定义free。

图2.2.1

图2.2.2
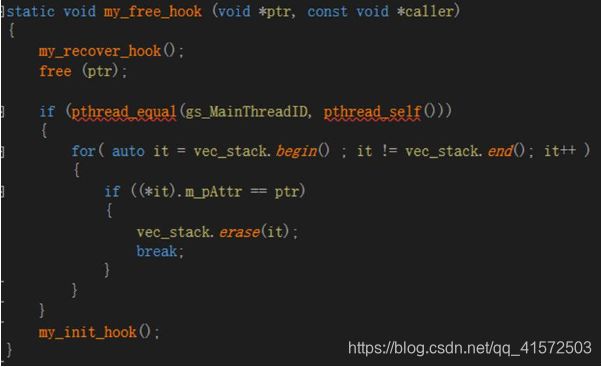
图2.2.3
3.高时效的UDP
摘自《2018腾讯移动游戏技术评审与实践案例》
到底是用tcp还是udp见一些参考指标
游戏对网络有实时性要求高,带宽要求小的特点。TCP 虽然提供了可靠传输,但是内置的复杂拥塞控制算法并不是专为实时性优化的,也没有提供较好的方法让业务定制化。CF 手游实现了自定义的RUDP 协议方案,使用UDP 保证协议实时性,同时通过自定义重传策略兼顾可靠性,取得了很好效果,主要技术要点包括:
- 数据传输分类
CF 手游中并非所有数据都要求可靠,按游戏逻辑需要,只有不到50%的协议有可靠性需求,RUDP 中只对这部分协议提供可靠性保证。而非可靠包则保证尽快到达,以满足游戏的实时性需求。对玩家移动状态等信息,由业务层定时冗余重传。

客户端与服务的的交互时序如下:

图CF 手游网络数据交互时序
- 快速发送
发送方不维护发送窗口,不等待前面包是否ack,有数据需要发送时立即发送。
- 快速重传
CF 手游使用比TCP 更高精度,响应速度更快的重传策略以保证实时性。

- 带宽优化
主要思路是有损服务和降低不必要开销。CFM 持续进行了多轮流量优化,包括:
1.MTU 设计为500+字节,应用逻辑保证数据包大小不超过MTU,避免拆包。
2.减小包头,8 字节。
3.小包合并。同一帧发往同一个目标的多个小数据包合并为大包,减少包数量。
4.降低服务端帧率和位置精度,但不影响玩家体验。
4.弱联网优化之道
摘自《2018腾讯移动游戏技术评审与实践案例》,作者:腾讯互娱专家工程师-樊华恒
移动网络的特点
1.移动状态网络信号不稳定,高时延、易抖动丢包、通道狭窄
2.移动状态网络接入类型和接入点变化频繁
3.移动状态用户高频化、碎片化、非wifi流量敏感
原因
如下:

第一、直观印象是通讯链路长而复杂,从(移动)终端设备到应用服务器之间,相较有线互联网,要多经过基站、核心网、WAP 网关(好消息是WAP 网关正在被依法取缔)等环节,这就像送快递,中间环节越多就越慢,每个中转站的服务质量和服务效率不一,每次传递都要重新交接入库和分派调度,一不小心还能把包裹给弄丢了;
第二、这是个资源受限网络,移动设备接入基站空中信道数量非常有限,信道调度更是相当复杂,如何复杂就不展开了,莫文蔚那首歌词用在这里正合适:“我讲又讲不清,你听又听不懂......”,最最重要的是分配的业务信道单元如果1 秒钟不传数据就会立马被释放回收,六亲不认童叟无欺;
第三、这个链条前端(无线端)是高时延(除某些WIFI 场景外)、低带宽(除某些WIFI 场景外)、易抖动的网络,无线各种制式网络带宽上限都比较低而传输时延比较大(参见【表一 运营商移动信号制式带宽标准】),并且,没事就能丢个包裹玩玩,最最重要的是,距离基站的远近,把玩手机的角度、地下室的深度等等都能影响无线信号的质量,让包裹在空中飞一会,再飞一会。这些因素也造成了移动互联网网络质量稳定性差、接入变化频繁,与有线互联网对比更是天上人间的差别,从【图二 有线互联网和移动互联网网络质量差异】中可以有更直观的感受;

第四、这是个局部封闭网络,空中信道接入后要做鉴权、计费等预处理,WAP 网络甚至还要做数据过滤后再转发,在业务数据有效流动前太多中间代理人求参与,效率可想而知。产品研发为什么又慢又乱,广大程序猿心里明镜似的;最最重要的是,不同运营商之间跨网传输既贵且慢又有诸多限制,聪明的运营商便也用上了缓存技术,催生了所谓网络“劫持”的现象。如果我们再结合用户在移动状态下2G/3G/4G/WIFI 的基站/AP 之间,或者不同网络制式之间频繁的切换,情况就更加复杂了。
除了这些物理上的约束,还有上层的约束:
1 DNS 解析,这个在有线互联网上司空见惯的服务,在移动互联网上变成了一种负担,一个往复最少1s,还别提遇到移动运营商DNS 故障时的尴尬;
2 链路建立成本暨TCP 三次握手,在一个高时延易抖动的网络环境,并且大部分业务数据交互限于一个HTTP 的往返,建链成本尤其显著;
3 TCP 协议层慢启动、拥塞控制、超时重传等机制在移动网络下参数设定的不适宜;
4 不好的产品需求规定或粗放的技术方案实现,使得不受控的大数据包、频繁的数据网络交互等,在移动网络侧TCP 链路上传输引起的负荷;
5 不好的协议格式和数据结构设计,使得协议封装和解析计算耗时、耗内存、耗带宽,甚至协议格式臃肿冗余,使得网络传输效能低下;
6 不好的缓存设计,使得数据的加载和渲染计算耗时、耗内存、耗带宽;
解决方式:
整体来说有四个方面:快链路、轻往复、强监控、多异步
1.快链路
- tcp/ip参数调优:
a.控制传输包的大小:即令传输层的MSS为1460字节以下(受限于数据链路层的MTU大小),避免ip包被分片,导致一个ip包片丢失会要求整个ip包重传(因为ip层没有确认机制)(MSS在三次握手中协商)
b.放大TCP拥塞窗口:如将慢启动窗口cwnd设置为10*MSS。这是因为对于移动APP来说,大部分的网络交互都是HTTP并发短链接小数据量传输的形式,若服务端有10KB+的数据返回,采用过去的慢启动机制时,大概会需要2~3个RTT(Round Trip Time,网络往返时间)才能完成数据传输,反映到用户体验层面就是慢,而把拥塞窗口初始值提升到10后,大多数情况下都能在1个RTT的周期内完成应用数据的传输。
c.调大SOCKET读写缓冲区:把SOCKET的读写缓冲取大小设置为64KB(tcp报头的窗口大小字段为16字节)。在Linux 平台上,可以通过 setsockopt 函数设置SO_RCVBUF 和SO_SNDBUF 选项来分别调整SOCKET 读缓冲区和写缓冲区的大小。
d.调大RTO(Retransmission TimeOut)的初始值:将超时重传的初始值设为3s(TCP协议栈会根据RTT动态重新计算此值,以适应当前的网络状况),因为在移动网络高时延的情景下,若RTO值过小,很容易造成TCP协议栈的过激反应,即拥塞控制闪亮登场。
e.开启TCP_NODELAY,移动APP的设计实现中,客户端请求大部分都很轻(数据大小不超过MSS),应该关闭Nagle算法
f.适当开启tcp端口快速回收:主动关闭的一端只等待一个重传时间RTO就释放socket,而不等TIME-WAIT
1) 服务器如果直接在公网服务于客户端时,因为客户端有可能通过NAT 代理访问外部网络,故建议关闭TCP 快速回收选项;
2) 服务器各层级在内网互联时,同时作为链接的主动发起方和链接的主动关闭方,建议开启TCP 快速回收。上述建议例外场景是:如服务器层级之间有4 层NAT,则需要考察层级靠前的服务器集群时钟同步的精度水平是否能到毫秒级,通常建议关闭TCP 快速回收选项;
设置例子见百度百科 和 CSDN博客
- 接入调度
(这些好像是客户端的相关知识...之前没有接触过,就大概摘录下)
a.就快接入:
1) 服务器分省分运营商分国内外的部署及使用CDN,广度和深度并举;
2) 客户端测速报告及服务质量监控报告,测速这个话题,稍微多探讨一下,在有线网络,实时测速并调整调度策略数据是非常普通的方案,但放在移动网络条件下,就有重新思考的必要。移动网络易抖动和移动应用大部分短链接轻量交互的特点,使得我们很难在一个短的时间内做出网络速度的有效判断,即便有初步的判断,也可能因为没有马上使用的时机而导致过期失效。因此,我们更倾向于把这些质量数据报告到后台,通过大量的数据归并分析,形成接入速度调度策略的判断依据;
3) 客户端接入IP 库与接入服务器就快调度匹配库需要持续更新;
4) 服务器调度中尽量减少302 跳转,做到一击即中;
b.去DNS的ip直连:
DNS 不但需要1 个RTT 的时间消耗,而且移动网络下的DNS 还存在很多其它问题:
1) 部分DNS 承载全网用户40%以上的查询请求,负载重,一旦故障,影响巨大,这样的案例在PC 互联网也有很多,Google 一下即可感受触目惊心的效果;
2) 山寨、水货、刷ROM 等移动设备的LOCAL DNS 设置错误;
3) 终端DNS 解析滥用,导致解析成功率低;
4) 某些运营商DNS 有域名劫持问题,实际上有线ISP 也存在类似问题。域名劫持对安全危害极大,产品设计时要注意服务端返回数据的安全校验(如果协议已经建立在安全通道上时则不用考虑,安全通道可以基于HTTPS 或者私有安全体系)。对于劫持的判断需要客户端报告实际拉取服务数据的目标地址IP 等信息;
5) DNS 污染、老化、脆弱;
综上就是在前述就快接入小节中,接入调度FSM 会优先使用动态服务器列表的原因。
c.网络可达性探测:
在连接建立过程中如果出现连接失败的现象,而终端系统提供的网络状态接口反馈网络可用时,我们需要做网络可达性探测(即向预埋的URL 或者IP 地址发起连接尝试),以区别网络异常和接入服务异常的情况,为定位问题,优化后台接入调度做数据支持。
探测数据可以异步报告到服务器,至少应该包含以下字段:
1) 探测事件ID,要求全局唯一不重复;
2) 探测发生时间;
3) 探测发生时网络类型和其它网络信息(比如WIFI 时的SSID 等);
4) 本地调度的接入服务器集合类型;
5) 本地调度的接入服务器IP(如使用域名接入,可忽略);
6) 探测的目标URL 或IP
- 链路管理
a.链路复用
我们在开篇讨论无线网络为什么慢的时候,提到了链接建立时三次握手的成本,在无线网络高时延、频抖动、窄带宽的环境下,用户使用趋于碎片化、高频度,且请求响应又一次性往返居多、较频繁发起等特征,建链成本显得尤其显著。因此,我们建议在链路创建后可以保持一段时间,比如HTTP 短链接可以通过HTTP Keep-Alive,私有协议可以通过心跳等方式来保持链路。
b.区分网络类型的超时管理
在不同的网络类型时,我们的链路超时管理要做精细化的区别对待。链路管理中共有三类超时,分别是连接超时、IO 超时和任务超时。我们有一些经验建议,提出来共同探讨:
1) 连接超时:2G/3G/4G 下5 ~ 10 秒,WIFI 下5 秒(给TCP 三次握手留下1次超时重传的机会,可以研究一下《TCP/IP 详解 卷一:协议》中TC P 的超时与重传部分);
2) IO 超时:2G/3G/4G 下15 ~ 20 秒(无线网络不稳定,给抖动留下必要的恢复和超时重传时间),WIFI 下15 秒(1 个MSL);
3) 任务超时:根据业务特征不同而差异化处理,总的原则是前端面向用户交互界面的任务超时要短一些(尽量控制在30 秒内并有及时的反馈),后台任务可以长一些,轻数据可以短一些,重数据可以长一些;
4) 超时总是伴随着重试,我们要谨慎小心的重试,后面会讨论;超时时间宜短不宜长,在一个合理的时间内令当前链路因超时失效,从而驱动调度FSM 状态的快速变迁,效率要比痴痴的等待高得多,同时,在用户侧也能得到一个较好的正反馈。
各类超时参数最好能做到云端可配可控。
c.轻重链路分离
轻重链路分离,也可以说是信令和数据分离,目的是隔离网络通讯的过程,避免重数据通讯延迟而阻塞了轻数据的交互。在用户角度看来就是信息在异步加载,控制指令响应反馈及时。移动端大部分都是HTTP 短链接模式工作,轻重数据的目标URL 本身就不同,比较天然的可以达到分离的要求,但是还是要特别做出强调,是因为实践中有些轻数据协议设计里面还会携带类似头像、验证码等的实体数据。
d.长链接
长链接对于提升应用网络交互的及时性大有裨益,一方面用户使用时,节省了三次握手的时间等待,响应快捷;另一方面服务器具备了实时推送能力,不但可以及时提示用户重要信息,而且能通过推拉结合的异步方案,更好的提升用户体验。长链接的维护包括链接管理、链接超时管理、任务队列管理等部分,设计实施复杂度相对高一些,尤其是在移动网络环境下。为了保持链路还需要做心跳机制(从另外一个角度看,这也是针对简单信息一个不错的PULL/PUSH 时机,,但需注意数据传输要够轻,比如控制在0.5KB 以内),而心跳机制是引入长链接方案复杂度的一个重要方面,移动网络链路环境复杂,国内网关五花八门,链路超时配置各有千秋,心跳时长选择学问比较大,不但要区分网络类型,还得区分不同运营商甚至不同省市,历史上曾经实践了2 分钟的心跳间隔,最近比较多的产品实践选择4.5 分钟的心跳间隔。而且长链接除了给移动网络尤其是空中信道带来负担外,移动设备自身的电量和流量也会有较大的消耗,同时还带来后端带宽和服务器投入增加。所以,除了一些粘性和活跃度很高、对信息到达实时性要求很高的通讯类APP 外,建议谨慎使用长链接。
e.小心重试
自动重试是导致后台雪崩的重要因素之一。在移动网络不稳定的条件下,大量及时的重试不但不能达到预期,反而无谓的消耗移动设备的电量甚至流量。因此,我们在重试前要有一些差异化的考虑:
1) 当前移动设备的网络状况如何,如果没有网络,则不必重试;
2) 重试设定必要的时间间隔,因为移动接入网络抖动到恢复可能需要一点时间,马上重试并非最佳策略,反而可能无谓的消耗电量。实践中,可以在一次连接或IO 失败(立即失败或超时)时,过3 ~ 5 秒后再试;
3) 重试应设定必要的总时限,因为三个服务器列表比较长,每个服务器地址都要重试和等待若干次,最终可能导致接入调度FSM 和服务器列表调度FSM 流转耗时过长,此时用户侧体验表现为长时间等待无响应。总时限参数可以参考前述区分网络类型的超时管理中的任务超时值。一旦某次重试成功,重试总时限计时器要归零;
4) 服务器下发特定错误码(比如服务器故障、过载或高负载)时,提示客户端停止重试并告知安抚用户,我们在强监控这个主题下有详细的讨论;每个目标服务器地址的重试次数、重试总时限和重试时间间隔最好能做到云端可
配可控。特别需要提出的一点是,移动APP 采用HTTP 短链接模式实现CS 交互时,广泛的使用了系统原生组件或者开源组件,这些友好的模块把超时和重试都封装起来,其缺省值是否适合自己的业务特点,需要多多关注。使用前,最好能知其然更知其所以然。
f.及时反馈
透明和尊重,会带来信任和默契,家庭如此、团队如此、用户亦如此。欲盖弥彰和装傻充愣也许短暂取巧,拉长时间轴来看,肯定要付出惨重的代价。及时和真诚的告知状况,赢得谅解和信任,小付出,大回报,试过都知道。当发现因为网络不存在或者其它属于移动端设备链路的异常时,应该及时和显著的提示用户,让用户注意到当前有诸如网络不存在、FREE WIFI 接入认证页面需确认等等问题,使用户可以及时处理或理解问题状态。当发现是服务器问题时,应及时、显著和真诚的告知用户,争取用户的谅解。网络异常提示或服务器故障通告等信息的呈现要做到一目了然,无二义和二次交互。
- IO管理
基于一个快速和高效管理的链路之上,做好IO 调度和控制,也是提升效能和改善用户体验的重要环节。要探讨的内容包括:
a.异步IO
异步化IO 的目的就是避免资源的集中竞争,导致关键任务响应缓慢。我们在后面差异服务个大的分类中会重点探讨。这里特别先提出来,是建议在程序架构顶层设计时,要在整体机制上支持异步化,设计必要的异步总线来联系各个层级模块,总线可能会涉及包括队列管理(优先级、超时、CRUD 等)、事件驱动、任务调度等。
异步IO 除了网络方面外,对移动设备,我们还特别要考虑一下磁盘IO 的异步。因为频繁、大吞吐量的磁盘IO 会造成APP 的UI 卡顿,从用户体验上看就是交互响应迟钝或者滑动帧率下降。一般来说,磁盘IO 异步会选用空间换时间的方案,即缓存数据批量定时写入磁盘。
b.并发控制
有了异步IO,并发控制就显得尤为重要。把异步机制当作银弹任意使用,就如同我们给移动APP 设计了一个叫“发现”的地方一样,很可能各种膨胀的需求、不知道如何归类的需求就纷至沓来,期待有朝一日被“发现”。异步IO 提供了一个很好的发射后不用管的机制,这就会造成使用者的膨胀,无论是否必要、无论轻重缓急,把请求一股脑的丢给异步队列,自己潇洒的转身就走。这样不但会带来效率和交互响应性能的下降,也会造成资源的无谓消耗。在后面多异步这个大分类的讨论中会涉及到轻重缓急的话题,在前述异步IO 的磁盘IO 的时空效率转换话题中,还应该包括IO 并发的控制,我们即不能因为并发过多的链路造成网络带宽的独占消耗影响其它APP 的使用,也不可因快速、大量的异步数据造成缓写机制形同虚设或是占用过大的内存资源。
c.推拉结合
PUSH 机制应该是苹果公司在移动设备上取得辉煌成就的最重要两个机制之一,另外一个是移动支付体系。我们这里的讨论不包括iOS 和APPLE 移动设备的拟人化交互体验,只侧重根基性的机制能力。APNS 解决了信息找人的问题,在过去,只有运营商的短信有这个能力,推送和拉取使得我们具备了实时获取重要信息的能力。为何要推拉结合。因为系统级的推送体系也必须维持一个自己的链路,而这个链路上要承载五花八门的APP 推送数据,如果太重,一方面会在设计上陷入个性化需求的繁琐细节中,另外一方面也会造成这条链路的拥堵和性能延迟。因此,通过PUSH 通知APP,再由APP 通过自己的链路去PULL 数据,即有效的利用了PUSH 机制,又能使得APP 能按需使用网络,不但简化了链路管理,而且节省了电量和流量。
d.断点续传
一方面,在讨论链路管理时,我们建议了优质网络下的并发链路来完成同一个重数据拉取任务。这就会涉及到任务的拆分和并行执行,基础是后台能支持断点续传。
另外一方面,从客户端的角度而言,移动网络的不稳定特点,可能会造成某个重数据拉取任务突然失败,无论是自动重试还是用户驱动的重试,如果能从上次失效的上下文继续任务,会有省时间、省电量和省流量的效果,想想也会觉得十分美好。
2.轻往复
“技”止此尔。强调网络交互的“少”,更应强调网络交互的“简”。 我们在一条高时延易抖动的通道上取得效率优势的关键因素就是减少在其上的往复交互,最好是老死不相往来(过激),并且这些往复中交换的数据要尽量的简洁、轻巧,轻车简从。这个概念是不是有点像多干多错,少干少错,不干没错。把我们实践过的主要手段提出来探讨:
- 协议二进制化
二进制比较紧凑,但是可读性差,也因此形成可维护性和可扩展性差、调测不便的不良印象。这也造成了大量可见字符集协议的出现。计算机是0 和1 的世界,她们是程序猿的水和电,任何一个整不明白,就没法愉快的生活了。
- 高效协议
高效的协议可以从两个层面去理解,一是应用层标准协议框架,二是基于其上封装的业务层协议框架,有时候也可以根据需要直接在TCP 之上把这两个层面合并,形成纯粹的业务层私有协议框架。不过,为了简化网络模块的通讯机制和一些通用性、兼容性考虑,目前大多数情况下,我们都会选择基于HTTP 这个应用层标准协议框架之上承载业务层协议框架。下面我们针对上述个层面展开探讨。
首先是应用层的标准协议优化,比如HTTP/1.1 的Pipeline、WebSocket(在HTML5 中增加)、SPDY(由Google 提出)、HTTP/2 等,其中特别需要关注的是处在试验阶段的SPDY 和草案阶段的HTTP/2。SPDY 是Google 为了规避HTTP/1.1 暨以前版本的局限性开展的试验性研究,
主要包括以下四点:
1) 链路复用能力,HTTP 协议最早设计时,选择了一问一答一连接的简单模式,这样对于有很多并发请求资源或连续交互的场景,链路建立的数量和时间成本就都增加了;
2) 异步并发请求的能力,HTTP 协议最早的设计中,在拉取多个资源时,会对应并发多个HTTP 链路(HTTP/1.1 的Pipeline 类似)时,服务端无法区分客户端请求的优先级,会按照先入先出(FIFO)的模式对外提供服务,这样可能会阻塞客户端一些重要优先资源的加载,而在链路复用的通道上,则提供了异步并发多个资源获取请求指令的能力,并且可以指定资源加载的优先级,比如CSS 这样的关键资源可以比站点ICON 之类次要资源优先加载,从而提升速度体验;
3) HTTP 包头字段压缩(注:特指字段的合并删减,并非压缩算法之意)精简,HTTP 协议中HEAD 中字段多,冗余大,每次请求响应都会带上,在不少业务场景中,传递的有效数据尺寸远远小于HEAD 的尺寸,带宽和时间成本都比较大,而且很浪费;
4) 服务器端具备PUSH 能力,服务器可以主动向客户端发起通信向客户端推送数据;HTTP/2 由标准化组织来制定,是基于SPDY 的试验成果开展的HTTP 协议升级标准化工作,有兴趣了解详细情况可以参考HTTP/2 的DRAFT 文档。其次是业务层的协议框架优化,它可以从三个方面考察,一是协议处理性能和稳定性好,包括诸如协议紧凑占用空间小,编码和解码时内存占用少CPU 消耗小计算快等等,并且bad casae 非常少;二是可扩展性好,向下兼容自不必说,向上兼容也并非不能;三是可维护性强,在协议定义、接口定义上,做到可读性强,把二进制协议以可读字符的形式展示,再通过预处理转化为源码级文件参与工程
编译。可能会有同学强调协议调测时的可阅读、可理解,既然读懂01 世界应该是程序员的基本修养,这一项可能就没那么重要了。
高效的业务层协议框架从分布式系统早期代表Corba 的年代就有很多不错的实践项目,目前最流行的开源组件应属ProtoBuf,可以学习借鉴。正所谓殊途同归、心有灵犀、不谋而合,英雄所见略同......,说来说去,高效协议的优化思路也都在链路复用、推拉结合、协议精简、包压缩等等奇技淫巧的范畴之内。
- 协议精简
协议精简的目的就是减少无谓的数据传输,提升网络效能。俗话说“千里不捎针”,古人诚不我欺也。我们实践总结以下三点供参考:
1) 能不传的就不传。把需要的和希望有的数据都列出来,按照对待产品需求的态度,先砍掉一半,再精简一半,估计就差不多了。另外,高效协议提供了比较好的扩展性,预留字段越少越好,移动互联网演化非常快,经常会发现前瞻的预留总是赶不上实际的需求;
2) 抽象公共数据。把各协议共性的属性数据抽象出来,封装在公共数据结构中,即所谓包头一次就传一份,这个想法不新鲜,TCP/IP 的设计者们早就身体力行了。除了带来数据冗余的降低外,还降低了维护和扩展的复杂度,一石二鸟,且抽且行;
3) 多用整数少用字符,数字比文字单纯,即简洁又清晰,还不需要担心英文不好被后继者BS;
4) 采用增量技术,通知变化的数据,让接收方处理差异,这是个很好的设计思想,实践中需要注意数据一致性的校验和保障机制,后面会有专门的细节讨论;
- 协议合并
协议合并的目标是通过将多条交互指令归并在一个网络请求中,减少链路创建和数据往复,提升网络效能。把实战总结的六点提出来供参考:
1) 协议合并结合协议精简,效率翻番;
2) 协议合并的基础是业务模型的分析,在分类的基础上去做聚合。首先得区分出来缓急,把实时和异步的协议分类出来分别去合并;其次得区分出来轻重,协议请求或协议响应的数据规模(指压缩后),尽量确保在一个数据报文中可完成推拉;
3) 协议合并在包的封装上至少有两种选择,一是明文协议合并后统一打包(即压缩和解密);二是明文协议分别打包,最后汇总;前者效率高一些,在实战中用的也较普遍;后者为流式处理提供可能;
4) 协议合并对服务器的异步处理架构和处理性能提出了更高的要求,特别需要权衡网络交互效率和用户对后台处理返回响应期待之间的取舍;
5) 协议间有逻辑顺序关系时,要认真考虑设计是否合理或能否合并;
6) 重数据协议不要合并;
- 增量技术
增量技术准确分类应该算是协议精简的一个部分,它与业务特点结合的非常紧密,值得单独讨论一下。增量技术在CS 数据流交互比较大的时候有充分发挥的空间,因为这个技术会带来客户端和服务器计算、存储的架构复杂度,增加资源消耗,并且带来许多保障数据一致性的挑战,当然,我们可以设计的更轻巧,容许一些不一致。
我们用一个案例来看看增量技术的运用。
在应用分发市场产品中,都有一个重要功能,叫更新提醒。它的实现原理很简单,以Android 设备为例,客户端把用户移动设备上安装的APP 包名、APP 名称、APP 签名、APP 版本号等信息发送到服务器,服务器根据这些信息在APP 库中查找相应APP 是否有更新并推送到客户端。这个过程非常简单,但如果用户手机上装了50 个APP,网络上交互的数据流就非常客观了,即浪费流量和电量,又造成用户体验的缓慢,显得很笨重。
这个时候,增量技术就可以派上用场了,比如下面的方案:
1) 每个自然日24 小时内,客户端选择一个时间(优先选择驻留在后台的时候)上报一次全量数据;
2) 在该自然日24 小时的其它时间,客户端可以定时或在用户使用时发送增量数据,包括卸载、安装、更新升级等带来的变化;
3) 作为弱一致性的保障手段,客户端在收到更新提示信息后,根据提醒的APP列表对移动设备上实际安装和版本情况做一次核对;
4) 上述择机或定时的时间都可以由云端通过下发配置做到精细化控制;
- 包压缩
前面精打细算完毕,终于轮到压缩算法上场了。选择什么算法,中间有哪些实战的总结,下面提出来一起探讨:
1) 压缩算法的选择,我们比较熟悉的压缩算法deflate、gzip、bzip2、LZO、Snappy、FastLZ 等等,选择时需要综合考虑压缩率、内存和CPU 的资源消耗、压缩速率、解压速率等多个纬度的指标,对于移动网络和移动设备而言,建议考虑使用gzip。另外需要注意的是,轻数据与重数据的压缩算法取舍有较大差异,不可一概而论;
2) 压缩和加密的先后秩序,一般而言,加密后的二进制数据流压缩率会低一些,建议先压缩再加密;
3) 注意一些协议组件、网络组件或数据本身是否已经做过压缩处理,要避免重复工作,不要造成性能和效率的下降。比如一些图片格式、视频或APK 文件都有自己的压缩算法。说到这,问题又来了,如果应用层标准协议框架做了压缩,那么基于其上封装的业务层协议框架还需要压缩吗,压缩技术到底哪家强?这个问题真不好回答,考虑到HTTP/2 这样的应用层标准协议框架定和普及尚需时日,建议在业务层协议框架中做压缩机制。或者追求完美,根据后端应用层标准协议框架响应是否支持压缩及在支持时的压缩算法如何等信息,动态安排,总的原则就是一个字:只选对的,不选贵的;
强监控
可监方可控,我们在端云之间,要形成良好的关键运营数据的采集、汇总和分析机制,更需要设计云端可控的配置和指令下发机制。本篇重点讨论与主题网络方面相关关键指标的“监”和“控”。以就快接入为例来探讨一下强监控能力的构建和使用。
1) 接入质量监控,客户端汇总接入调度FSM 执行过程元信息以及业务请求响应结果的元信息,并由此根据网络类型不同、运营商不同、网络接入国家和省市不同分析接入成功率、业务请求成功率(还可细化按业务类型分类统计)、前述二者失败的原因归类、接入302 重定向次数分布暨原因、接入和业务请求测速等;
2) 建设云端可控的日志染色机制,便于快速有针对性的定点排查问题;
3) 终端硬件、网络状态的相关参数采集汇总;
4) 建设云端可控的接入调度(比如接入IP 列表等)和网络参数(比如连接超时、IO 超时、任务超时、并发链接数、重试间隔、重试次数等)配置下发能力;
5) 服务器根据汇总数据,通过数据分析,结合服务器自身的监控机制,可以做
到:
a. 支持细粒度的接入调度和网络参数的优化云控;
b. 支持服务器的部署策略优化;
c. 发现移动运营商存在的一些差异化问题比如URL 劫持、网络设备超时配置不当等问题便于推动解决;
d. 发现分省市服务器服务质量的异常情况,可以动态云端调度用户访问或者降级服务,严重时可以及时提示客户端发出异常安抚通告,避免加剧服务器的负载导致雪崩。安民告示的快速呈现能力,考验了一个团队对可“控”理解的深度,我们在实践中,提供了三级措施来保障:第一级是服务器端通过协议或跳转URL下发的动态通告,这在非IDC 公网故障且业务接入服务器正常可用时适用;第二级是预埋静态URL(可以是域名或IP 形式,优先IP)拉取动态通告,适用其它故障,静态URL 部署的IP 地址最好同本业务系统隔离,避免因为业务服务所在IDC 公网故障不可用时无法访问;第三级是客户端本地预埋的静态通告文案,内容会比较模糊和陈旧,仅作不时之需;
e. 支持异步任务的云端可配可控,比如下载类APP 的下载时间、下载标的和下载条件约束(磁盘空间、移动设备电量、网络类型等)的差异化配置,通过错峰调度,达到削峰平谷并提升用户体验的效果;特别需要注意的是,客户端数据报告一定要有数据筛选控制和信息过滤机制,涉及用户隐私的敏感信息和使用记录必须杜绝采样上报。在我们的日志染色机制中要特别注意,为了排查问题极可能把关键、敏感信息记录报告到后端,引入安全风险。
多异步
经过前面不懈的努力,初步打造了一个比较好的技术根基,好马配好鞍,好车配风帆,怎么就把领先优势拱手送与特斯拉了。
用户欲壑难平,资源供不应求,靠“术”并无法优雅的解决。跳出来从产品角度去观察,还有些什么能够触动我们思考的深度呢。根据不同的需求和使用场景,用有损服务的价值观去权衡取舍,用完美的精神追求不完美,此乃道的层面。所谓大道至简,完美之道,不在无可添加,而在无可删减。通过多异步和各类缓存机制,提供区分网络、区分业务场景下的差异化服务,是我们孜孜以求的大“道”。
下面通过一些实践案例的总结,来探索简洁优雅的弱联网体验改善之道(开始肆无忌惮的吹嘘了)。
- 网络交互可否延后
微博客户端某个版本启动时,从闪屏加载到timeline 界面需要6 秒+。这样的体验是无法接受的,与用户2 秒以内的等待容忍度是背道而驰的。从技术角度去分析,很容易发现问题,诸如我们在启动时有10+个并发的网络请求(因为是HTTP 短链接,意味着10+个并发的网络链接)、闪屏加载、主UI 创建、本地配置加载、本地持久化数据加载至Cache 等等程序行为,优化的目标很自然就集中在网络请求和本地配置、持久化数据加载上。梳理并发网络请求,可以从以下三个方面考察:
1) 哪些请求是要求实时拉取的,比如timeline & 提及 & 私信的数字、身份校验;
2) 哪些请求是可以异步拉取的,比如timeline、用户Profile、云端配置、双向收听列表、闪屏配置、timeline 分组列表、相册tag 列表等;
3) 哪些请求是可以精简或合并的,比如timeline & 提及 & 私信的数字与身份校验合并;
此时,取舍就非常简单和清晰了,启动时1~2 个网络请求足够应对。所做的仅仅是把一些请求延后发起,这是一种异步机制。
在移动APP 里面还有大量类似的场景,比如用户更新了APP 的某个设置项或者自己Profile 的某个字段,是停在界面上转菊花等网络交互返回后再提示结果,亦或是把界面交互马上还给用户,延后异步向服务器提交用户请求,这里面的价值取向不同,“快”感也便不同。
- 网络内容可否预先加载
微博客户端在timeline 刷新时,用户向上快速滑屏,到达一个逻辑分页(比如30 条微博消息)时,有两个取舍,一是提前预加载下个分页内容并自动拼接,给用户无缝滑动的体验;二是等到用户滑动到达分页临界点时现场转菊花,卡不卡看当时的网络状况。实践中选择了方案一。用户在滑动浏览第一个逻辑分页时,APP 就利用这个时间窗主动预先拉取下一个逻辑分页的内容,使得用户能享受一个顺畅的“刷”的体验。所做的仅仅是把一个请求提前发起了,这也是一种异步机制。思考的要点是:
1) 预先加载的内容是用户预期的吗,预先加载和自动下载之间,失之毫厘谬以千里;
2) 预先加载的内容对用户移动设备的资源(比如流量、电量等)和后端服务器的资源(比如带宽、存储、CPU 等)消耗要做好估算和判断,体贴和恶意之间,也就一步之遥;
3) 预先加载区分轻重数据,轻数据可以不区分网络状况,重数据考虑仅限优质网络下执行,最好这些策略云端可以控制;
4) 预先通过网络拉取加载或存储的过程中,不要打搅用户的正常使用;在移动APP 中,预加载有大量的实践,比较典型的就是升级提醒,大家都采用了先下载好升级包,再提示用户有新版本的策略,让你顺畅到底。
- 用户体验可否降级
微博客户端在香港公共WIFI 下刷新timeline 总是失败,通过后台用户接入请求和响应日志分析,判断是香港IDC 到香港公共WIFI 的汇接口带宽窄、时延大,此时该如何应对。
从前面探讨的TCP/IP 网络知识,可以知道,在一个窄带宽高时延网络中,吞吐量BDP 必然很小,也就是说单位大小的数据传输所需的时间会很长。如果按照通常一次下发一个逻辑分页timeline 数据的策略,那么从服务器到客户端传输,整个数据需要拆分成多个TCP 数据报文,在缓慢的传输过程中,可能一个数据报文还未传输完成,客户端的链路就已经超时了。如果在弱网络(需要在应用层有测速机制,类似TCP/IP 的RTT 机制,测速时机可以是拉取微博消息数字时)下,把逻辑分页的微博消息数由30 调整为5 会如何,如果方案成立,用户刷微博的体验是不是会下降,因为滑动一屏就要做一次网络交互,即便是配合预加载,也可能因为网络太慢,操控太快而又见菊花。外团在香港实测了这个版本,感叹,终于可以刷了。在饥渴难耐和美酒佳肴之间,似乎还有很多不同层级的体验。聊胜于无,这个词很精准的表述了服务分层,降级取舍的重要性。思考的要点是:
1) 产品的核心体验是什么,即用户最在乎的是什么,在做宏观分层设计时要充分保障核心体验;
2) 每个产品交互界面中,什么数据是无法容忍短时间不一致的,即什么是用户不能容忍的错误,在做微观分层设计时要充分考虑正确性;
3) 在宏观和微观分层的基础上,开始设想在什么条件下,可以有什么样的降级取舍,来保障可用,保障爽快的体验;
4) 分层不宜太多太细,大部分产品和场景,3 层足矣;在移动弱网络条件下,处处可见降级取舍的案例。比如网络条件不佳时,降低拉取缩略图的规格,甚至干脆不自动拉取缩略图等等,分层由心,降级有意。
- 端和云孰轻孰重
移动APP 时代,绝对的轻端重云或者轻云重端都是不可取的,只有端云有机的配合,才能在一个受限的网络通道上做出更好的用户体验。正所谓东家之子,胖瘦有致。
比如移动网游APP,如取向选择轻端重云,那么玩家的战斗计算就会大量的通过网络递交给服务器处理并返回,卡顿家常便饭,操控感尽失。比如微博客户端,如果取向选择重端轻云,微博timeline 所有的消息都拉取元数据(比如微博正文包括文字、各类URL、话题、标签、@、消息的父子关系、消息中用户profile、关系链等等),由客户端实时计算拼装,不但客户端用户需
要消耗大量流量计算量,而且给后端服务器带来巨大的带宽成本和计算压力,如果过程中网络状况不佳,还会非常卡顿。通过实践总结,端和云孰轻孰重,取舍的关键是在数据计算规模可控和数据安全有保障的前提下:
1) 减少网络往复,要快;
2) 减少网络流量,要轻;端云有机结合,可以很好的演绎机制与策略分离的设计思想,从而使系统具备足够的柔韧性。不得不再次特别提到的一点是,缓存技术是异步化的基础,它渗透在性能和体验提升的方方面面,从持久化的DB、文件,到短周期的内存数据结构,从业务逻辑数据,到TCP/IP 协议栈,它无所不在。缓存涉及到数据结构组织和算法效能(耗时、命中率、内存使用率等)、持久化和启动加载、更新、淘汰、清理方案等,有机会我们可以展开做专题的介绍。牢记一个字,缓存是让用户爽到极致的利器,但千万别留下垃圾。提倡多异步,实际上是要求团队认真审视产品的核心能力是什么,深入思考和发现什么是用户最关心的核心体验,把有限的资源聚焦在它们身上。通过考察用户使用产品时的心理模型,体验和还原用户使用场景,用追求完美的精神探索不完美之道。
互联网服务核心价值观之一“不要我等”,在移动互联网时代仍应奉为圭臬,如何面对新的挑战,需要更多的学习、思考、实践和总结,这篇文章即是对过去实践的总结,亦作为面对未来挑战的思考基点。
5.服务端其他优化手段:
游戏同步
网络游戏同步,常用的两种方案是帧同步和状态同步。
帧同步是同步玩家的指令,服务器负责转发客户端的操作,每个客户端以固定的逻辑帧执行所有客户端的操作指令,通过在严格一致的时间轴上执行同样的命令序列获得同样的结果。
状态同步跟帧同步的最大区别是服务器不在进行切逻辑帧,而是同步玩家状态信息,比如位置、属性、跟玩法相关的数据。通常主逻辑在服务器运行,客户端只是作为一个显示。采用状态同步的游戏有CFM、LOL 等。
帧同步的网络流量较小,但防外挂、断线重连的难度比较大。状态同步中服务器有所有玩家的状态,安全性较高,游戏运营更可控。是否选择状态同步,需要看同步的实体数量。在大场景中,同步的单位比较多时,往往会放弃状态同步。比如星际争霸中玩家可操作的实体多达上百个,如采用状态同步的话网络流量将非常大。
- 例子:
2014 年底酷跑推出了实时同屏多人对战模式的玩法。玩家要努力战胜对手,将速度最大化,用最短的时间跑完全程。多人战分经典战和道具战两种,经典战比拼速度,道具战通过道具增加或减少各种效果,玩家可以利用各种功能各异的道具保护自己,干扰对手。
多人战属于同步PVP,4 个玩家匹配到一起后即可开局。由于对战中玩家数不多,同时服务器需要做一些逻辑,这里选用了状态同步的同步方案。游戏过程中玩家上报自己的操作、位置和状态给服务器,服务器做一些逻辑处理,再把该玩家上报的包广播给其他玩家,其他玩家收到包后,知道该玩家的状态,做相应的逻辑。游戏过程中,根据游戏场景,动态调节同步频率,达到节省同步包量,降低服务器负载的目的。玩家在游戏中平均每秒1 次左右的同步。

- 思考fifaol3
因为最多游戏人数为3v3,所以可以使用状态同步,即所有玩家将当前的操作、状态、位置等发到服务器,服务器做一些逻辑处理后,广播给其余玩家,这样的好处是防外挂、断线重连比较容易实现。(游戏中我卡了,其他玩家看到我操控的球员是一直往一个方向跑的,即一直执行我的最后一次操作),针对不同的场景可以动态调整同步的频率如每15帧同步一次或者更多,达到节省同步包量,降低服务器负载的目的。
6.DOS攻击和DDOS攻击
DOS:是Denial of Service的简称,即拒绝服务,不是DOS操作系统,造成DoS的攻击行为被称为DoS攻击,其目的是使计算机或网络无法提供正常的服务。最常见的DoS攻击有计算机网络带宽攻击和连通性攻击。
DDOS:分布式拒绝服务(DDoS:Distributed Denial of Service)攻击指借助于客户/服务器技术,将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDoS攻击,从而成倍地提高拒绝服务攻击的威力。
DDoS攻击它的原理说白了就是群殴,用好多的机器对目标机器一起发动DoS攻击,但这不是很多黑客一起参与的,这种攻击只是由一名黑客来操作的。这名黑客不是拥有很多机器,他是通过他的机器在网络上占领很多的"肉鸡",并且控制这些"肉鸡"来发动DDoS攻击,要不然怎么叫做分布式呢。还是刚才的那个例子,你的机器每秒能发送10个攻击数据包,而被攻击的机器每秒能够接受100的数据包,这样你的攻击肯定不会起作用,而你再用10台或更多的机器来对被攻击目标的机器进行攻击的话,那结果就可想而知了。
事实上DOS的攻击方式有很多种,比如下面的常见的:
- 1. SYN-Flood
DDoS究竟如何攻击?目前最流行也是最好用的攻击方法就是使用SYN-Flood进行攻击,SYN-Flood也就是SYN洪水攻击。SYN-Flood不会完成TCP三次握手的第三步,也就是不发送确认连接的信息给服务器。这样,服务器无法完成第三次握手,但服务器不会立即放弃,服务器会不停的重试并等待一定的时间后放弃这个未完成的连接,这段时间叫做SYN timeout,这段时间大约30秒-2分钟左右。若是一个用户在连接时出现问题导致服务器的一个线程等待1分钟并不是什么大不了的问题,但是若有人用特殊的软件大量模拟这种情况,那后果就可想而知了。一个服务器若是处理这些大量的半连接信息而消耗大量的系统资源和网络带宽,这样服务器就不会再有空余去处理普通用户的正常请求(因为客户的正常请求比率很小)。这样这个服务器就无法工作了,这种攻击就叫做:SYN-Flood攻击。

- 2.IP欺骗DOS攻击
这种攻击利用RST位来实现。假设现在有一个合法用户(1.1.1.1)已经同服务器建立了正常的连接,攻击者构造攻击的TCP数据,伪装自己的IP为1.1.1.1,并向服务器发送一个带有RST位的TCP数据段。服务器接收到这样的数据后,认为从1.1.1.1发送的连接有错误,就会清空缓冲区中建立好的连接。这时,如果合法用户1.1.1.1再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。
攻击时,伪造大量的IP地址,向目标发送RST数据,使服务器不对合法用户服务。
- 3.带宽DOS攻击
如果你的连接带宽足够大而服务器又不是很大,你可以发送请求,来消耗服务器的缓冲区消耗服务器的带宽。这种攻击就是人多力量大了,配合上SYN一起实施DOS,威力巨大。不过是初级DOS攻击。
- 4.自身消耗的DOS攻击
这是一种老式的攻击手法。说老式,是因为老式的系统有这样的自身BUG。比如Win95 (winsock v1), Cisco IOS v.10.x, 和其他过时的系统。
这种DOS攻击就是把请求客户端IP和端口弄成主机的IP端口相同,发送给主机。使得主机给自己发送TCP请求和连接。这种主机的漏洞会很快把资源消耗光。直接导致当机。这中伪装对一些身份认证系统还是威胁巨大的。
上面这些实施DOS攻击的手段最主要的就是构造需要的TCP数据,充分利用TCP协议。这些攻击方法都是建立在TCP基础上的。还有其他的DOS攻击手段。
- 5.塞满服务器的硬盘
通常,如果服务器可以没有限制地执行写操作,那么都能成为塞满硬盘造成DOS攻击的途径,比如:
发送垃圾邮件。一般公司的服务器可能把邮件服务器和WEB服务器都放在一起。破坏者可以发送大量的垃圾邮件,这些邮件可能都塞在一个邮件队列中或者就是坏邮件队列中,直到邮箱被撑破或者把硬盘塞满。
让日志记录满。入侵者可以构造大量的错误信息发送出来,服务器记录这些错误,可能就造成日志文件非常庞大,甚至会塞满硬盘。同时会让管理员痛苦地面对大量的日志,甚至就不能发现入侵者真正的入侵途径。
向匿名FTP塞垃圾文件。这样也可以塞满硬盘空间。
7.网络编程中的粘包问题
《后台开发核心技术与实践》一书中给出了一般解决方案:
在发送的数据前面加上固定4字节,用来存放数据包长度。接收方先接收4字节,解析出数据的长度,再进行收包。
直接上例子:
1.发送字符串
客户端代码,注意点见代码中2处注释
#include
#include
#include
#include
#include
#include
#include
#include
#include
int MySend( int iSock, char * pchBuf, size_t tLen){
int iThisSend;
unsigned int iSended=0;
if(tLen == 0)
return(0);
while(iSended 服务端代码:注意点见代码中2处注释
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
int MyRecv( int iSock, char * pchBuf, size_t tCount){
size_t tBytesRead=0;
int iThisRead;
while(tBytesRead < tCount){
do{
iThisRead = read(iSock, pchBuf, tCount-tBytesRead);
} while((iThisRead<0) && (errno==EINTR));
if(iThisRead < 0){
return(iThisRead);
}else if (iThisRead == 0)
return(tBytesRead);
tBytesRead += iThisRead;
pchBuf += iThisRead;
}
}
#define DEFAULT_PORT 6666
int main( int argc, char ** argv){
int sockfd,acceptfd; /* 监听socket: sock_fd,数据传输socket: acceptfd */
struct sockaddr_in my_addr; /* 本机地址信息 */
struct sockaddr_in their_addr; /* 客户地址信息 */
unsigned int sin_size, myport=6666, lisnum=10;
if ((sockfd = socket(AF_INET , SOCK_STREAM, 0)) == -1) {
perror("socket" );
return -1;
}
printf("socket ok \n");
my_addr.sin_family=AF_INET;
my_addr.sin_port=htons(DEFAULT_PORT);
my_addr.sin_addr.s_addr = INADDR_ANY;
bzero(&(my_addr.sin_zero), 0);
if (bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr )) == -1) {
perror("bind" );
return -2;
}
printf("bind ok \n");
if (listen(sockfd, lisnum) == -1) {
perror("listen" );
return -3;
}
printf("listen ok \n");
char recvMsg[10];
sin_size = sizeof(my_addr);
acceptfd = accept(sockfd,(struct sockaddr *)&my_addr,&sin_size);
if (acceptfd < 0) {
close(sockfd);
printf("accept failed\n" );
return -4;
}
ssize_t readLen = MyRecv(acceptfd, recvMsg, sizeof( int)); //先接收4字节
if (readLen < 0) {
printf("read failed\n" );
return -1;
}
int len=( int)ntohl(*( int*)recvMsg);
printf("len:%d\n",len);
readLen = MyRecv(acceptfd, recvMsg, len); //再接收总数据
if (readLen < 0) {
printf("read failed\n" );
return -1;
}
recvMsg[len]='\0';
printf("recvMsg:%s\n" ,recvMsg);
close(acceptfd);
return 0;
}
例子2:收发结构体
客户端:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "define.h"
#define DEFAULT_PORT 6666
int main( int argc, char * argv[]){
int connfd = 0;
int cLen = 0;
struct sockaddr_in client;
if(argc < 2){
printf(" Uasge: clientent [server IP address]\n");
return -1;
}
client.sin_family = AF_INET;
client.sin_port = htons(DEFAULT_PORT);
client.sin_addr.s_addr = inet_addr(argv[1]);
connfd = socket(AF_INET, SOCK_STREAM, 0);
if(connfd < 0){
printf("socket() failure!\n" );
return -1;
}
if(connect(connfd, (struct sockaddr*)&client, sizeof(client)) < 0){
printf("connect() failure!\n" );
return -1;
}
Pkg mypkg;
mypkg.head.num=1;
mypkg.head.index=10001;
mypkg.content.sex='m';
mypkg.content.score=90;
char * temp="guangzhou and shanghai";
strncpy(mypkg.content.address,temp,sizeof(mypkg.content.address));
mypkg.content.age=18;
ssize_t writeLen;
int tLen=sizeof(mypkg); //数据总长度
printf("tLen:%d\n" ,tLen);
int iLen=0;
char * pBuff= new char [1000];
*(int*)(pBuff+iLen)= htonl(tLen); //数据总长度
iLen+=sizeof( int);
*(int*)(pBuff+iLen)= htonl(mypkg.head.num); //第一个成员长度
iLen+=sizeof( int);
*(int*)(pBuff+iLen)= htonl(mypkg.head.index); //第二个成员长度
iLen+=sizeof( int);
memcpy(pBuff+iLen,&mypkg.content.sex,sizeof( char)); //第三个成员长度
iLen+=sizeof( char);
*(int*)(pBuff+iLen)= htonl(mypkg.content.score); //第四个成员长度
iLen+=sizeof( int);
memcpy(pBuff+iLen,mypkg.content.address,sizeof(mypkg.content.address)); //第五个成员长度
iLen+=(sizeof(mypkg.content.address));
*(int*)(pBuff+iLen)= htonl(mypkg.content.age); //第六个成员长度
iLen+=sizeof( int);
writeLen= MySend(connfd, pBuff, iLen); //iLen一直在累加
if (writeLen < 0) {
printf("write failed\n" );
close(connfd);
return 0;
}
else{
printf("write sucess, writelen :%d, iLen:%d, pBuff: %s\n",writeLen,iLen,pBuff);
}
close(connfd);
return 0;
}
服务端:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "define.h"
#define DEFAULT_PORT 6666
int main( int argc, char ** argv){
int sockfd,acceptfd; /* 监听socket: sock_fd,数据传输socket: acceptfd */
struct sockaddr_in my_addr; /* 本机地址信息 */
struct sockaddr_in their_addr; /* 客户地址信息 */
unsigned int sin_size, myport=6666, lisnum=10;
if ((sockfd = socket(AF_INET , SOCK_STREAM, 0)) == -1) {
perror("socket" );
return -1;
}
printf("socket ok \n");
my_addr.sin_family=AF_INET;
my_addr.sin_port=htons(DEFAULT_PORT);
my_addr.sin_addr.s_addr = INADDR_ANY;
bzero(&(my_addr.sin_zero), 0);
if (bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr )) == -1) {
perror("bind" );
return -2;
}
printf("bind ok \n");
if (listen(sockfd, lisnum) == -1) {
perror("listen" );
return -3;
}
printf("listen ok \n");
char recvMsg[1000];
sin_size = sizeof(my_addr);
acceptfd = accept(sockfd,(struct sockaddr *)&my_addr,&sin_size);
if (acceptfd < 0) {
close(sockfd);
printf("accept failed\n" );
return -4;
}
ssize_t readLen = MyRecv(acceptfd, recvMsg, sizeof(int));
if (readLen < 0) {
printf("read failed\n" );
return -1;
}
int len=(int)ntohl(*(int*)recvMsg);
printf("len:%d\n",len);
readLen = MyRecv(acceptfd, recvMsg, len);
if (readLen < 0) {
printf("read failed\n" );
return -1;
}
char * pBuff=recvMsg;
Pkg RecvPkg;
int iLen=0;
memcpy(&RecvPkg.head.num , pBuff + iLen, sizeof( int));
iLen += sizeof(int);
RecvPkg. head. num = ntohl(RecvPkg.head.num);
printf("RecvPkg.head.num:%d\n" ,RecvPkg.head.num);
memcpy(&RecvPkg.head.index , pBuff + iLen, sizeof( int));
iLen += sizeof(int);
RecvPkg. head. index = ntohl(RecvPkg.head.index);
printf("RecvPkg.head.index:%d\n" ,RecvPkg.head.index);
memcpy(&RecvPkg.content.sex , pBuff + iLen, sizeof( char));
iLen += sizeof(char);
printf("RecvPkg.content.sex:%c\n" ,RecvPkg.content.sex);
memcpy(&RecvPkg.content.score , pBuff + iLen, sizeof( int));
iLen += sizeof(int);
RecvPkg. content.score = ntohl(RecvPkg. content.score );
printf("RecvPkg.content.score:%d\n" ,RecvPkg.content.score);
memcpy(&RecvPkg.content.address, pBuff + iLen, sizeof(RecvPkg.content.address ));
iLen += sizeof(RecvPkg.content.address);
printf("RecvPkg.content.address:%s\n" ,RecvPkg.content.address);
memcpy(&RecvPkg.content.age , pBuff + iLen, sizeof( int));
iLen += sizeof(int);
RecvPkg.content.age = ntohl(RecvPkg.content.age );
printf("RecvPkg.content.age:%d\n" ,RecvPkg.content.age);
close(acceptfd);
return 0;
}
use:注意第一句话
#pragma pack(1) //修改字节对齐方式为1字节
struct Header {
int num ;//包id
int index ;//学生编号
};
struct PkgContent {
char sex ;//性别
int score ;//分数
char address [100];//地址
int age;
};
struct Pkg {
Header head;
PkgContent content ;
};
int MySend( int iSock, char * pchBuf, size_t tLen){
int iThisSend;
unsigned int iSended=0;
if(tLen == 0)
return 0;
while(iSended