kubernetes部署(kubeadmin)
文章目录
-
-
- 1.环境准备
- 2. 安装dokcer
- 3.部署cri-docker
- 4.各个节点安装kubeadm等
- 5.整合kubelet和cri-dockerd
-
- 配置cri-dockerd
- 配置kubelet
- 6.初始化集群
-
1.环境准备
环境和软件版本
OS : ubuntu 20.04
container runtime: docker CE 20.10.22
kubernetes 1.24.17
CRI:cri-dockerd v0.2.5
配置主机名
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-node01
hostnamectl set-hostname k8s-node02
hostnamectl set-hostname k8s-node03
配置hosts
192.168.1.180 k8s-master01.luohw.com k8s-master01
192.168.1.181 k8s-node01.luohw.com k8s-node01
192.168.1.183 k8s-node02.luohw.com k8s-node02
192.168.1.185 k8s-node03.luohw.com k8s-node03
拷贝配置文件到其他节点
scp /etc/hosts 192.168.1.181:/etc/
禁用Swap设备
swapoff -a
vi /etc/fstab 注释swap行
~# systemctl --type swap
而后,将上面命令列出的每个设备,使用systemctl mask命令加以禁用。
~# systemctl mask SWAP_DEV
2. 安装dokcer
添加docker源
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get -y update
#sudo apt-get -y install docker-ce
apt-cache madison docker-ce
apt-get -y install docker-ce=5:20.10.22~3-0~ubuntu-focal #安装指定版本docker
配置docker
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://2abfrd78.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "200m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
systemctl restart docker
这段代码片段是Docker的配置文件中的一部分,具体解释如下:
-
"exec-opts": ["native.cgroupdriver=systemd"]:这是指定Docker使用systemd作为cgroup驱动程序的配置选项。cgroup是用于在Linux系统中限制和控制进程资源的机制之一。 -
"log-driver": "json-file":这是指定Docker使用json-file作为日志驱动程序的配置选项。它将容器的日志输出以JSON格式写入文件。 -
"log-opts": {"max-size": "200m"}:这是指定Docker日志驱动程序的一些选项。在这个例子中,max-size选项将日志文件的最大大小限制为200MB,当日志文件达到该大小时,将会被截断或进行滚动。 -
"storage-driver": "overlay2":这是指定Docker使用overlay2作为存储驱动程序的配置选项。存储驱动程序负责管理和存储Docker容器的镜像和容器数据。
这些配置选项可以根据具体需求进行调整和修改,以满足不同的应用场景和要求。
3.部署cri-docker
各个节点部署cri-docker
ubuntu下载对应安装包
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.2.5/cri-dockerd_0.2.5.3-0.ubuntu-focal_amd64.deb
scp cri-dockerd_0.2.5.3-0.ubuntu-jammy_amd64.deb 192.168.1.183:/root/
dpkg -i cri-dockerd_0.2.5.3-0.ubuntu-jammy_amd64.deb
4.各个节点安装kubeadm等
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt install kubelet=1.24.17-00 kubeadm=1.24.17-00 kubelet=1.24.17-00
5.整合kubelet和cri-dockerd
配置cri-dockerd
修改此行
cat /usr/lib/systemd/system/cri-docker.service
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --cni-bin-dir=/opt/cni/bin --cni-cache-dir=/var/lib/cni/cache --cni-conf-dir=/etc/cni/net.d
--network-plugin=cni 网络接口使用cni
--cni-bin-dir=/opt/cni/bin cni在哪个目录下
--cni-cache-dir cni的缓存目录
--cni-conf-dir cni的各组件的默认配置文件目录
systemctl daemon-reload && systemctl restart cri-docker.service
配置kubelet
添加配置文件
mkdir /etc/sysconfig
vim /etc/sysconfig/kubelet
KUBELET_KUBEADM_ARGS=“–container-runtime=remote --container-runtime-endpoint=/run/cri-dockerd.sock”
scp -rp /etc/sysconfig/ k8s-node01:/etc
scp -rp /etc/sysconfig/ k8s-node02:/etc
6.初始化集群
###查看1.24.17所需要的镜像
kubeadm config images list --kubernetes-version v1.24.17
registry.k8s.io/kube-apiserver:v1.24.17
registry.k8s.io/kube-controller-manager:v1.24.17
registry.k8s.io/kube-scheduler:v1.24.17
registry.k8s.io/kube-proxy:v1.24.17
registry.k8s.io/pause:3.6
registry.k8s.io/etcd:3.5.6-0
registry.k8s.io/coredns/coredns:v1.8.6
提示:无法访问grc.io时,可以在上面的命令中使用“–image-repository=registry.aliyuncs.com/google_containers”选项,以便从国内的镜像服务中获取各Image;
命令回顾
删除registry.k8s.io
sed -i ‘s/registry.k8s.io//p’ images_v1.24.17.sh
行首添加/registry.cn-hangzhou.aliyuncs.com/google_containers
sed -ri ‘s#^#registry.cn-hangzhou.aliyuncs.com/google_containers#’ images_v1.24.17.sh
提前下载镜像
bash images_v1.24.17.sh
root@k8s-master01:~# cat images_v1.24.17.sh
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.24.17
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.24.17
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.24.17
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.24.17
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.6-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
root@k8s-master01:~# kubeadm config images pull --kubernetes-version v1.24.17 --cri-socket unix:///run/cri-dockerd.sock
failed to pull image "registry.k8s.io/kube-apiserver:v1.24.17": output: time="2023-09-17T01:05:30+08:00" level=fatal msg="validate service connection: CRI v1 image API is not implemented for endpoint \"unix:///run/cri-dockerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.ImageService"
能是由于 Kubernetes 使用的容器运行时版本与 Kubernetes 版本不兼容导致的。
初始化集群
kubeadm init \
--control-plane-endpoint="kubeapi.luohw.com" \
--kubernetes-version=v1.24.17 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--cri-socket unix:///run/cri-dockerd.sock \
--upload-certs
问题1
root@k8s-master01:~#
kubeadm init \
--control-plane-endpoint="kubeapi.luohw.com" \
--kubernetes-version=v1.24.17 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--cri-socket unix:///run/cri-dockerd.sock \
--upload-certs \
--image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers
[init] Using Kubernetes version: v1.24.17
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time=“2023-09-17T01:28:50+08:00” level=fatal msg=“validate service connection: CRI v1 runtime API is not implemented for endpoint “unix:///run/cri-dockerd.sock”: rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService”
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with --ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
kubernetes 版本与容器运行时版本不匹配导致
v1.24.17是3周前发布的,但是使用的cri-docker是版本cri-dockerd_0.2.5.3是2022年8月,下载新版cri-dockerd_0.3.3.3-0.ubuntu-focal_amd64.deb后初始化正常
问题2
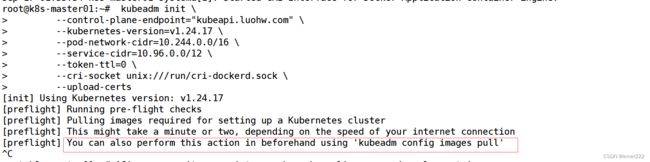
一直卡在这里,添加 --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers 指定为阿里云镜像服务
初始化完成
root@k8s-master01:~# kubeadm init \
> --control-plane-endpoint="kubeapi.luohw.com" \
> --kubernetes-version=v1.24.17 \
> --pod-network-cidr=10.244.0.0/16 \
> --service-cidr=10.96.0.0/12 \
> --token-ttl=0 \
> --cri-socket unix:///run/cri-dockerd.sock \
> --upload-certs \
> --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers
[init] Using Kubernetes version: v1.24.17
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master01 kubeapi.luohw.com kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.1.180]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.1.180 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.1.180 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///run/cri-dockerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///run/cri-dockerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher