【计算机视觉】Image Feature Extractors方法介绍合集(二)
文章目录
-
- 一、Mixed Depthwise Convolution
- 二、Deformable Kernel
- 三、Dynamic Convolution
- 四、Submanifold Convolution
- 五、CondConv
- 六、Active Convolution
- 七、Depthwise Dilated Separable Convolution
- 八、Involution
- 九、Dilated convolution with learnable spacings
- 十、Attention-augmented Convolution
- 十一、PP-OCR
- 十二、Displaced Aggregation Units
- 十三、Dimension-wise Convolution
- 十四、Local Relation Layer
- 十五、Lightweight Convolution
- 十六、Hamburger
- 十七、Span-Based Dynamic Convolution
- 十八、ShapeConv
一、Mixed Depthwise Convolution
MixConv(或混合深度卷积)是一种深度卷积,它自然地在单个卷积中混合多个内核大小。 它基于深度卷积将单个内核大小应用于所有通道的见解,MixConv 通过结合多个内核大小的优点来克服这一问题。 它通过将通道划分为组并向每个组应用不同的内核大小来实现此目的。

二、Deformable Kernel
可变形核是一种用于变形建模的卷积算子。 DK 学习内核坐标上的自由形式偏移,将原始内核空间变形为特定的数据模态,而不是重新组合数据。 这可以直接调整有效感受野(ERF),同时保持感受野不变。 它们可以用作刚性内核的直接替代品。

三、Dynamic Convolution
DynamicConv 是一种用于顺序建模的卷积,它的内核随着时间的推移而变化,作为各个时间步长的学习函数。 它基于 LightConv 构建并采用相同的形式,但使用时间步相关的内核:
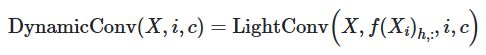

四、Submanifold Convolution

五、CondConv
CondConv(或条件参数化卷积)是一种卷积类型,它为每个示例学习专门的卷积核。
为了有效地增加 CondConv 层的容量,开发人员可以增加专家的数量。 这比增加卷积核本身的大小更具计算效率,因为卷积核应用于输入内的许多不同位置,而每个输入仅组合专家一次。

六、Active Convolution
主动卷积是一种没有固定感受野形状的卷积,可以采用更多样化的感受野形式进行卷积。 它的形状可以通过训练期间的反向传播来学习。 可以看作是卷积的推广; 它不仅可以定义所有常规卷积,还可以定义具有分数像素坐标的卷积。 我们可以自由改变卷积的形状,这为形成 CNN 结构提供了更大的自由度。 其次,卷积的形状是在训练时学习的,不需要手动调整

七、Depthwise Dilated Separable Convolution
深度扩张可分离卷积是一种将深度可分离性与扩张卷积的使用相结合的卷积类型。

八、Involution
卷积是深度神经网络的原子操作,它颠倒了卷积的设计原理。 卷积核在空间范围上是不同的,但在通道之间是共享的。 如果对合核被参数化为固定大小的矩阵(如卷积核)并使用反向传播算法进行更新,则学习到的对合核将无法在具有可变分辨率的输入图像之间传输。
作者认为对合相对于卷积有两个好处:(i)对合可以在更广泛的空间排列中总结上下文,从而克服对远程交互建模的困难; (ii)对合可以自适应地分配不同位置的权重,从而优先考虑空间域中信息最丰富的视觉元素。

九、Dilated convolution with learnable spacings
具有可学习间距的扩张卷积(DCLS)是一种卷积类型,允许在训练期间学习内核非零元素之间的间距。 这使得在不增加参数数量的情况下增加卷积的感受野成为可能,从而可以提高网络在需要长程依赖的任务上的性能。
扩张卷积是一种允许内核跳过某些输入特征的卷积。 这是通过在内核的非零元素之间插入零来完成的。 这样做的效果是在不增加参数数量的情况下增加卷积的感受野。
DCLS 通过允许在训练期间学习内核的非零元素之间的间距,将这一想法向前推进了一步。 这意味着网络可以根据手头的任务学习跳过不同的输入特征。 这对于需要远程依赖的任务特别有用,例如图像分割和对象检测。
DCLS 已被证明对多种任务有效,包括图像分类、对象检测和语义分割。 这是一种有前途的新技术,有潜力提高卷积神经网络在各种任务上的性能。

十、Attention-augmented Convolution
注意力增强卷积是一种具有二维相对自注意力机制的卷积,可以取代卷积作为图像分类的独立计算原语。 与变形金刚一样,它采用了缩放点积注意力和多头注意力。

与卷积类似,注意力增强卷积 1) 与平移等变,2) 可以轻松地对不同空间维度的输入进行操作。

十一、PP-OCR
PP-OCR是一个OCR系统,由文本检测、检测框校正和文本识别三部分组成。 文本检测的目的是定位图像中的文本区域。 在 PP-OCR 中,可微分二值化 (DB) 用作基于简单分割网络的文本检测器。 它集成了特征提取和序列建模。 它采用连接主义时间分类(CTC)损失来避免预测和标签之间的不一致。

十二、Displaced Aggregation Units
置换聚合单元用可学习的单元位置取代了 ConvNet 中的经典卷积层。 这引入了层次组合的显式结构,并带来了几个好处:
通过空间可调的滤波器单元实现完全可调和可学习的感受野
减少空间覆盖参数,实现高效推理
将参数与感受野大小解耦

十三、Dimension-wise Convolution


十四、Local Relation Layer
局部关系层是一种图像特征提取器,是卷积算子的替代品。 直觉上,卷积中的聚合基本上是一种应用固定滤波器的模式匹配过程,这在对具有不同空间分布的视觉元素进行建模时效率很低。 局部关系层根据局部像素对的组成关系自适应地确定聚合权重。 有人认为,通过这种关系方法,它可以以更有效的方式将视觉元素组合成更高级别的实体,从而有利于语义推理。

十五、Lightweight Convolution
LightConv 是一种用于顺序建模的深度卷积,它共享某些输出通道,并且使用 softmax 在时间维度上对权重进行归一化。 与自注意力相比,LightConv 具有固定的上下文窗口,它通过一组不随时间步长变化的权重来确定上下文元素的重要性。 LightConv 计算以下内容序列和输出通道中的第一个元素:


十六、Hamburger
Hamburger 是一个全局上下文模块,它采用矩阵分解将学习到的表示分解为子矩阵,从而恢复干净的低秩信号子空间。 关键思想是,如果我们将像全局上下文这样的归纳偏差表述为目标函数,则最小化目标函数的优化算法可以构造一个计算图,即我们在网络中需要的架构。

十七、Span-Based Dynamic Convolution
基于跨度的动态卷积是 ConvBERT 架构中使用的一种卷积类型,用于捕获标记之间的局部依赖关系。 内核是通过获取当前 token 的本地范围来生成的,这更好地利用了本地依赖并区分同一 token 的不同含义(例如,如果输入句子中“a”位于“can”前面,则“can”显然是 名词而非动词)。
具体来说,使用经典卷积,我们将为所有输入标记共享固定参数。 因此,动态卷积是更可取的,因为它在捕获不同标记的局部依赖性方面具有更高的灵活性。 动态卷积使用内核生成器为不同的输入标记生成不同的内核。 然而,这种动态卷积无法区分不同上下文中的相同标记并生成相同的内核(例如,图(b)中的三个“can”)。
因此,基于跨度的动态卷积被开发出来,通过接收输入跨度而不是仅接收单个标记来产生更具适应性的卷积核,这使得能够区分不同上下文中相同标记的生成核。 例如,如图(c)所示,基于跨度的动态卷积为不同的“can”标记生成不同的内核。

十八、ShapeConv
ShapeConv,即形状感知卷积层,是用于处理室内 RGB-D 语义分割中的深度特征的卷积层。 首先将深度特征分解为形状分量和基本分量,接下来引入两个可学习的权重来独立地与它们配合,最后对这两个分量的重新加权组合应用卷积。
