【计算机视觉】Image Feature Extractors方法介绍合集(一)
文章目录
-
- 一、Convolution
- 二、1x1 Convolution
- 三、Depthwise Convolution
- 四、Pointwise Convolution
- 五、Depthwise Separable Convolution
- 六、Grouped Convolution
- 七、Dilated Convolution
- 八、3D Convolution
- 九、Non-Local Operation
- 十、Deformable Convolution
- 十一、Switchable Atrous Convolution
- 十二、Invertible 1x1 Convolution
- 十三、1-Dimensional Convolutional Neural Networks
- 十四、Groupwise Point Convolution
- 十五、Masked Convolution
- 十六、Selective Kernel Convolution
- 十七、CoordConv
- 十八、(2+1)D Convolution
- 十九、Spatially Separable Convolution
- 二十、Octave Convolution
图像特征提取器是可用于从图像中学习表示的函数或模块。 最常见的特征提取器类型是卷积,其中内核在图像上滑动,从而实现参数共享和平移不变性。 您可以在下面找到不断更新的图像特征提取器列表。
一、Convolution
卷积是一种矩阵运算,由一个内核(一个小的权重矩阵)组成,它在输入数据上滑动,与其所在的输入部分执行元素级乘法,然后将结果求和到输出中。
直观上,卷积允许权重共享(减少有效参数的数量)和图像转换(允许在输入空间的不同部分检测到相同的特征)。

二、1x1 Convolution
1 x 1 卷积是具有一些特殊属性的卷积,因为它可用于降维、高效的低维嵌入以及在卷积后应用非线性。 它将输入像素及其所有通道映射到输出像素,该输出像素可以被压缩到所需的输出深度。 它可以被视为查看特定像素位置的 MLP。
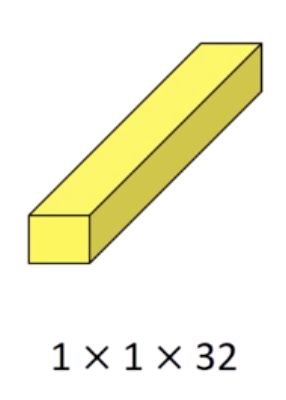
三、Depthwise Convolution
深度卷积是一种卷积,我们为每个输入通道应用单个卷积滤波器。 在多个输入通道上执行的常规 2D 卷积中,滤波器的深度与输入一样深,让我们可以自由混合通道以生成输出中的每个元素。 相反,深度卷积使每个通道保持分离。 总结一下这些步骤,我们:
将输入和滤波器拆分为通道。
我们将每个输入与相应的过滤器进行卷积。
我们将卷积输出堆叠在一起。
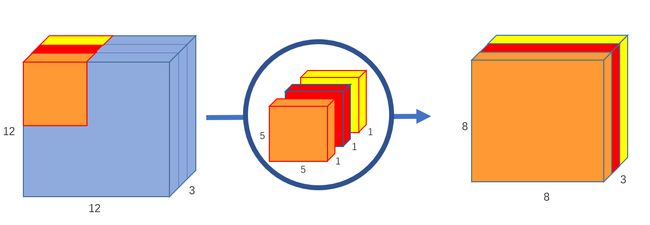
四、Pointwise Convolution
逐点卷积是一种使用 1x1 内核的卷积:迭代每个点的内核。 该内核的深度与输入图像的通道数相同。 它可以与深度卷积结合使用,生成一类高效的卷积,称为深度可分离卷积。
五、Depthwise Separable Convolution
标准卷积一步执行通道方向和空间方向计算,而深度可分离卷积将计算分为两个步骤:深度卷积对每个输入通道应用单个卷积滤波器,而逐点卷积用于创建输出的线性组合 深度卷积。 标准卷积和深度可分离卷积的比较如右图所示。
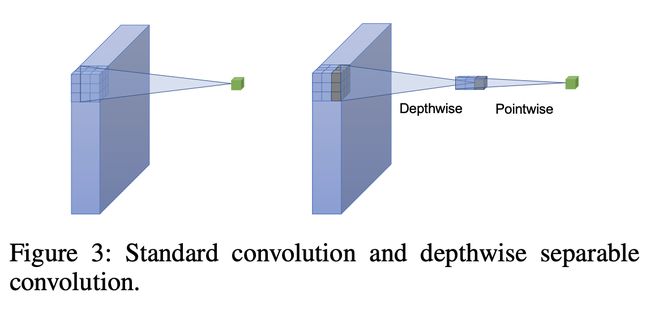
六、Grouped Convolution
分组卷积使用一组卷积 - 每层多个内核 - 导致每层多个通道输出。 这导致更广泛的网络帮助网络学习各种低级和高级特征。 在 AlexNet 中使用分组卷积的最初动机是将模型分布在多个 GPU 上,作为工程妥协。 但后来,ResNeXt 等模型表明该模块可用于提高分类精度。 具体来说,通过分组卷积、基数(变换集的大小)暴露新的维度,我们可以通过增加它来提高准确性。

七、Dilated Convolution
扩张卷积是一种通过在内核元素之间插入孔来“膨胀”内核的卷积类型。 一个附加参数l(膨胀率)表示内核加宽的程度。 通常有l-1在内核元素之间插入空格。
请注意,该概念在过去的文献中以不同的名称存在,例如,algorithme a trous,一种小波分解算法(Holschneider et al., 1987; Shensa, 1992)。
八、3D Convolution
3D 卷积是一种卷积类型,其中内核在 3 维上滑动,而不是 2D 卷积的 2 维上滑动。 一个示例用例是医学成像,其中使用 3D 图像切片构建模型。 此外,基于视频的数据比图像具有额外的时间维度,使其适合该模块。

九、Non-Local Operation
非本地操作是用于通过深度神经网络捕获远程依赖性的组件。 它是计算机视觉中经典非局部均值运算的推广。 直观上,非局部操作将某个位置的响应计算为输入特征图中所有位置的特征的加权和。 该组位置可以在空间、时间或时空中,这意味着这些操作适用于图像、序列和视频问题。
在非局部均值运算之后,深度神经网络的通用非局部运算定义为:



十、Deformable Convolution
可变形卷积将 2D 偏移添加到标准卷积中的规则网格采样位置。 它可以使采样网格自由变形。 偏移量是通过附加的卷积层从前面的特征图中学习的。 因此,变形以局部、密集和自适应的方式以输入特征为条件。
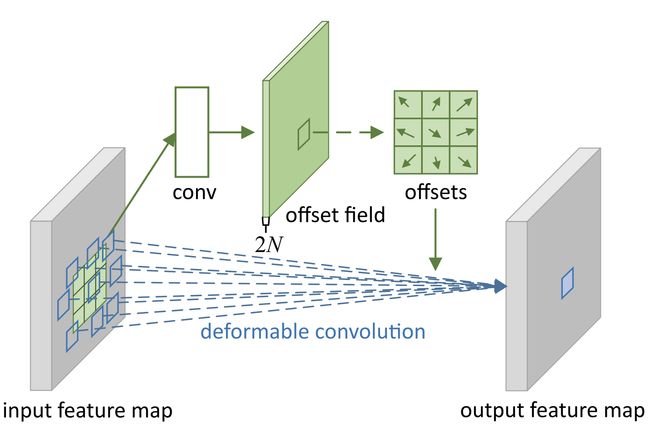
十一、Switchable Atrous Convolution
可切换空洞卷积 (SAC) 在不同空洞率之间软切换卷积计算,并使用开关函数收集结果。 开关功能是空间相关的,即特征图的每个位置可能有不同的开关来控制 SAC 的输出。 为了在检测器中使用 SAC,我们将自下而上主干中的所有标准 3x3 卷积层转换为 SAC。

十二、Invertible 1x1 Convolution
可逆 1x1 卷积是基于流的生成模型中使用的一种卷积类型,可反转通道的顺序。 权重矩阵被初始化为随机旋转矩阵。
计算起来很简单:
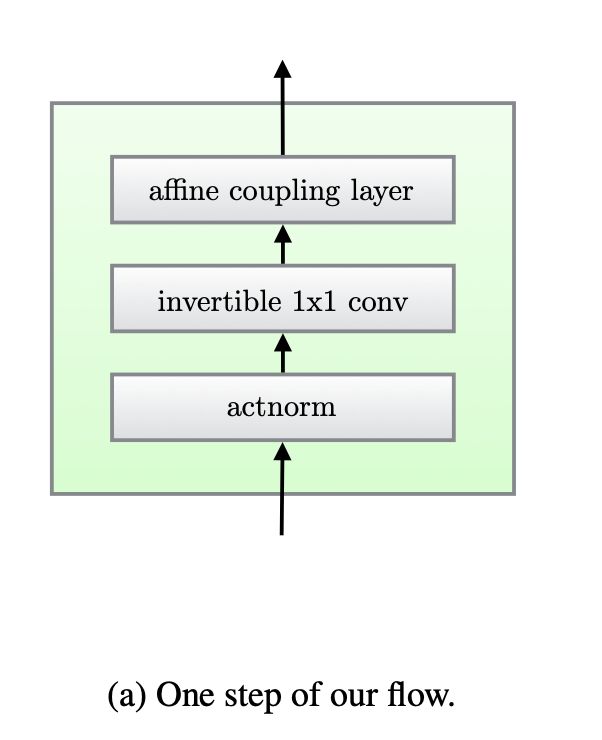
十三、1-Dimensional Convolutional Neural Networks
一维卷积神经网络与众所周知且更成熟的二维卷积神经网络类似。 一维卷积神经网络主要用于文本和一维信号。
十四、Groupwise Point Convolution
分组点卷积是一种卷积类型,我们按分组应用点卷积(使用不同的卷积滤波器组集)。
十五、Masked Convolution
屏蔽卷积是一种卷积类型,它屏蔽某些像素,以便模型只能根据已经看到的像素进行预测。 这种类型的卷积是在 PixelRNN 生成模型中引入的,其中图像是逐像素生成的,以确保模型仅以已访问的像素为条件。

十六、Selective Kernel Convolution
选择性核卷积是一种使神经元能够在具有不同核大小的多个核之间自适应调整其 RF 大小的卷积。 具体来说,SK 卷积有 3 个算子——Split、Fuse 和 Select。 使用由这些分支中的信息引导的 softmax 注意力来融合具有不同内核大小的多个分支。 对这些分支的不同关注会产生融合层神经元有效感受野的不同大小。

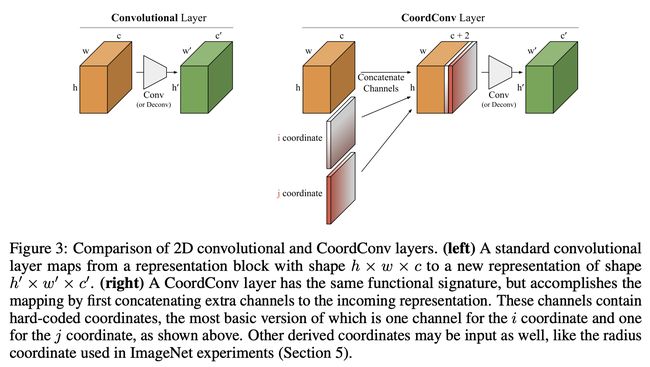
十七、CoordConv
CoordConv 层是标准卷积层的简单扩展。 它具有与卷积层相同的功能签名,但通过首先将额外通道连接到传入表示来完成映射。 这些通道包含硬编码坐标,其最基本的版本是用于i坐标和一个为j协调。
CoordConv 层保留了卷积的少量参数和高效计算的属性,但允许网络根据学习任务的需要学习保持或丢弃平移不变性。 这对于基于坐标变换的任务非常有用,因为常规卷积可能会失败。
十八、(2+1)D Convolution
(2+1)D 卷积是一种用于动作识别卷积神经网络的卷积类型,具有时空体积。 与在整个体积上应用 3D 卷积不同,(2+1)D 卷积将计算分成两个卷积:空间 2D 卷积,然后是时间 1D 卷积,这可能会导致计算成本高昂并导致过度拟合。

十九、Spatially Separable Convolution
空间可分离卷积将卷积分解为两个单独的操作。 在常规卷积中,如果我们有 3 x 3 内核,那么我们直接将其与图像进行卷积。 我们可以将 3 x 3 内核分为 3 x 1 内核和 1 x 3 内核。 然后,在空间可分离卷积中,我们首先对 3 x 1 内核进行卷积,然后对 1 x 3 内核进行卷积。 与常规卷积相比,这需要 6 个参数,而不是 9 个参数,因此参数效率更高(另外需要更少的矩阵乘法)。

二十、Octave Convolution
倍频卷积 (OctConv) 存储和处理在较低空间分辨率下空间变化“较慢”的特征图,从而减少内存和计算成本。 它接收包含两个相隔一个倍频程的频率张量的特征图,并直接从低频图中提取信息,而不需要将其解码回高频。 其动机是,在自然图像中,信息以不同的频率传递,其中较高频率通常用精细细节编码,而较低频率通常用全局结构编码。