使用DeepSpeed加速大型模型训练(二)
使用DeepSpeed加速大型模型训练
在这篇文章中,我们将了解如何利用Accelerate库来训练大型模型,从而使用户能够利用DeeSpeed的 ZeRO 功能。
简介
尝试训练大型模型时是否厌倦了内存不足 (OOM) 错误?我们已经为您提供了保障。大型模型性能非常好[1],但很难使用可用的硬件进行训练。为了充分利用可用硬件来训练大型模型,可以使用 ZeRO(零冗余优化器)[2] 来利用数据并行性。
下面是使用 ZeRO 的数据并行性的简短描述以及此博客文章中的图表
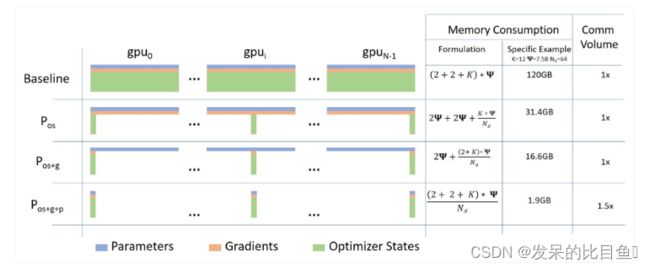
a. 第 1 阶段:分片优化器状态跨数据并行工作器/GPUs的状态
b. 第 2 阶段:分片优化器状态+梯度跨数据并行工作器/GPUs
c. 第 3 阶段:分片优化器状态+梯度+模型参数跨数据并行工作器/GPUs
d. 优化器卸载(Optimizer Offload):将梯度+优化器状态卸载到ZERO Stage 2之上的CPU/磁盘构建
e. 参数卸载(Param Offload):将模型参数卸载到ZERO Stage 3之上的CPU/磁盘构建
在这篇博文中,我们将看看如何使用ZeRO和Accelerate来利用数据并行性。DeepSpeed, FairScale和PyTorch fullyshardeddataparlparallel (FSDP)实现了ZERO论文的核心思想。伴随博客,通过DeepSpeed和FairScale 使用ZeRO适应更多和训练更快[4]和使用PyTorch完全分片并行数据加速大型模型训练[5], 这些已经集成在transformer Trainer和accelerate中。背后的解释可以看这些博客,主要集中在使用Accelerate来利用DeepSpeed ZeRO。
Accelerate :利用DeepSpeed ZeRO没有任何代码的变化
我们将研究只微调编码器模型用于文本分类的任务。我们将使用预训练microsoft/deberta-v2-xlarge-mnli (900M params) 用于对MRPC GLUE数据集进行微调。
代码可以在这里找到 run_cls_no_trainer.py它类似于这里的官方文本分类示例,只是增加了计算训练和验证时间的逻辑。让我们比较分布式数据并行(DDP)和DeepSpeed ZeRO Stage-2在多gpu设置中的性能。
要启用DeepSpeed ZeRO Stage-2而无需任何代码更改,请运行加速配置并利用 Accelerate DeepSpeed Plugin
ZeRO Stage-2 DeepSpeed Plugin 示例
配置
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
现在,运行下面的命令进行训练
accelerate launch run_cls_no_trainer.py \
--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \
--task_name "mrpc" \
--ignore_mismatched_sizes \
--max_length 128 \
--per_device_train_batch_size 40 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir "/tmp/mrpc/deepspeed_stage2/" \
--with_tracking \
--report_to "wandb" \
在我们的单节点多gpu设置中,DDP支持的无OOM错误的最大批处理大小是8。相比之下,DeepSpeed Zero-Stage 2允许批量大小为40,而不会出现OOM错误。因此,与DDP相比,DeepSpeed使每个GPU能够容纳5倍以上的数据。下面是wandb运行的图表快照,以及比较DDP和DeepSpeed的基准测试表。
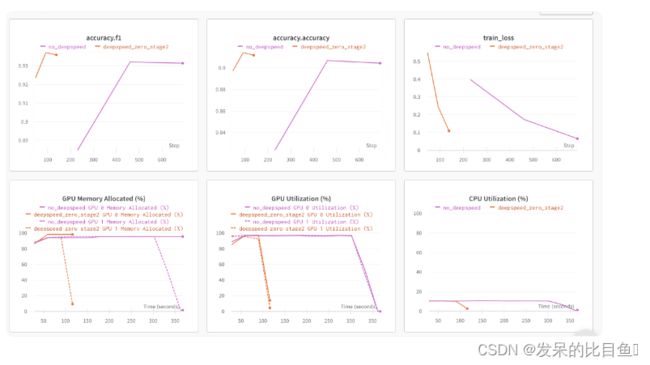
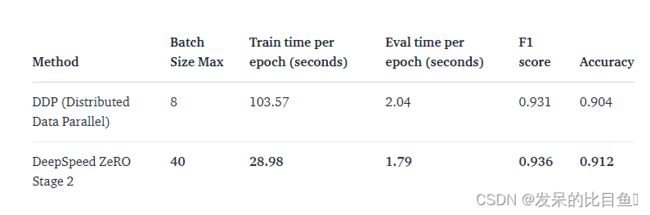
表1:DeepSpeed ZeRO Stage-2在DeBERTa-XL (900M)模型上的基准测试
使用更大的批处理大小,我们观察到总训练时间加快了3.5倍,而性能指标没有下降,所有这些都没有改变任何代码。
为了能够调整更多选项,您将需要使用DeepSpeed配置文件和最小的代码更改。我们来看看怎么做。
Accelerate :利用 DeepSpeed 配置文件调整更多选项
首先,我们将研究微调序列到序列模型以训练我们自己的聊天机器人的任务。具体来说,我们将facebook/blenderbot-400M-distill在smangrul/MuDoConv(多域对话)数据集上进行微调。该数据集包含来自 10 个不同数据源的对话,涵盖角色、基于特定情感背景、目标导向(例如餐厅预订)和一般维基百科主题(例如板球)。
代码可以在这里找到run_seq2seq_no_trainer.py。目前有效衡量聊天机器人的参与度和人性化的做法是通过人工评估,这是昂贵的[6]。对于本例,跟踪的指标是BLEU分数(这不是理想的,但却是此类任务的常规指标)。如果您可以访问支持bfloat16精度的gpu,则可以调整代码以训练更大的T5模型,否则您将遇到NaN损失值。我们将在10000个训练样本和1000个评估样本上运行一个快速基准测试,因为我们对DeepSpeed和DDP感兴趣。我们将利用DeepSpeed Zero Stage-2 配置 zero2_config_accelerate.json(如下所示)进行训练。有关各种配置特性的详细信息,请参阅DeeSpeed文档。
{
"fp16": {
"enabled": "true",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 15,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
要使用上述配置启用DeepSpeed ZeRO Stage-2,请运行accelerate config并提供配置文件路径。更多详细信息,请参考accelerate官方文档中的DeepSpeed配置文件。
ZeRO Stage-2 DeepSpeed配置文件示例
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero2_config_accelerate.json
zero3_init_flag: false
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
现在,运行下面的命令进行训练
accelerate launch run_seq2seq_no_trainer.py \
--dataset_name "smangrul/MuDoConv" \
--max_source_length 128 \
--source_prefix "chatbot: " \
--max_target_length 64 \
--val_max_target_length 64 \
--val_min_target_length 20 \
--n_val_batch_generations 5 \
--n_train 10000 \
--n_val 1000 \
--pad_to_max_length \
--num_beams 10 \
--model_name_or_path "facebook/blenderbot-400M-distill" \
--per_device_train_batch_size 200 \
--per_device_eval_batch_size 100 \
--learning_rate 1e-6 \
--weight_decay 0.0 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--num_warmup_steps 100 \
--output_dir "/tmp/deepspeed_zero_stage2_accelerate_test" \
--seed 25 \
--logging_steps 100 \
--with_tracking \
--report_to "wandb" \
--report_name "blenderbot_400M_finetuning"
当使用DeepSpeed配置时,如果用户在配置中指定了优化器和调度器,用户将不得不使用accelerate.utils.DummyOptim和accelerate.utils.DummyScheduler。这些都是用户需要做的小改动。下面我们展示了使用DeepSpeed配置时所需的最小更改的示例
- optimizer = torch.optim.Adam(optimizer_grouped_parameters, lr=args.learning_rate)
+ optimizer = accelerate.utils.DummyOptim(optimizer_grouped_parameters, lr=args.learning_rate)
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )
+ lr_scheduler = accelerate.utils.DummyScheduler(
+ optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
+ )
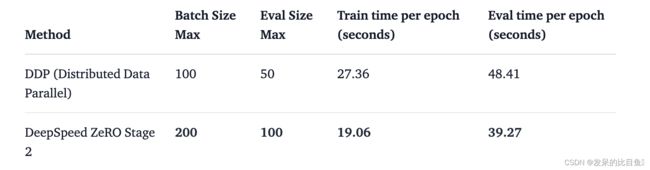
表2:DeepSpeed ZeRO Stage-2在BlenderBot (400M)模型上的基准测试
在我们的单节点多gpu设置中,DDP支持的无OOM错误的最大批处理大小是100。相比之下,DeepSpeed Zero-Stage 2允许批量大小为200,而不会出现OOM错误。因此,与DDP相比,DeepSpeed使每个GPU能够容纳2倍以上的数据。我们观察到训练加速了1.44倍,评估加速了1.23倍,因为我们能够在相同的可用硬件上容纳更多的数据。由于这个模型是中等大小,加速不是那么令人兴奋,但这将改善与更大的模型。你可以和使用Space smangrul/Chat-E上的全部数据训练的聊天机器人聊天。你可以给机器人一个角色,一个特定情感的对话,用于目标导向的任务或自由流动的方式。下面是与聊天机器人的有趣对话。您可以在这里找到使用不同上下文的更多对话的快照。
CPU/磁盘卸载,使训练庞大的模型将不适合GPU内存
在单个24GB NVIDIA Titan RTX GPU上,即使批量大小为1,也无法训练GPT-XL模型(1.5B参数)。我们将看看如何使用DeepSpeed ZeRO Stage-3与CPU卸载优化器状态,梯度和参数来训练GPT-XL模型。
我们将利用DeepSpeed Zero Stage-3 CPU卸载配置zero3_offload_config_accelerate.json (如下所示)进行训练。
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
ZeRO Stage-3 CPU Offload DeepSpeed配置文件示例
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero3_offload_config_accelerate.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
现在,运行下面的命令进行训练

表3:在GPT-XL (1.5B)模型上对DeepSpeed ZeRO Stage-3 CPU Offload进行基准测试
即使批大小为1,DDP也会导致OOM错误。另一方面,使用DeepSpeed ZeRO Stage-3 CPU卸载,我们可以以16个batch_size大小进行训练。
最后,请记住,Accelerate只集成了DeepSpeed,因此,如果您对DeepSpeed的使用有任何问题或疑问,请向DeepSpeed GitHub提交问题。