HDFS的存储原理
1、存储原理
1.1、HDFS分布式文件存储
将文件分为集群节点的部分数,分别存入每个节点中。
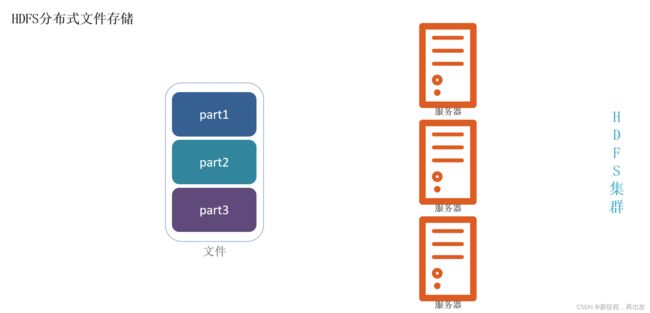

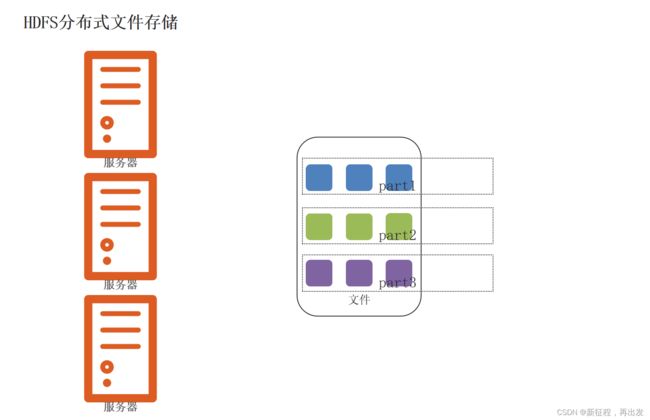
1.2、问题:文件大小不一,不利于统一管理
1.2.1、问题:文件大小不一,不利于统一管理


1.2.2、解决:设定统一的管理单位,block块

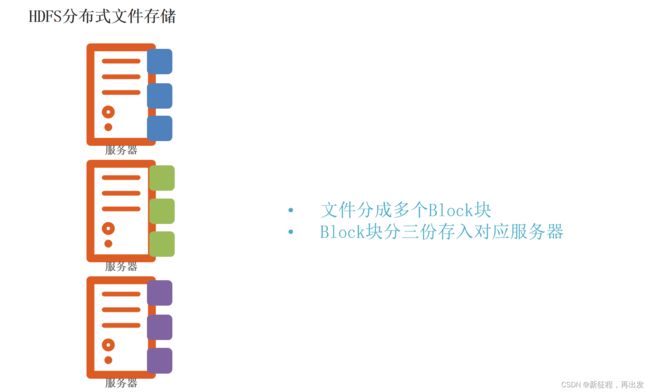
1.3、问题:如果丢失或损坏了某个Block块呢?
1.3.1、问题:如果丢失或损坏了某个Block块
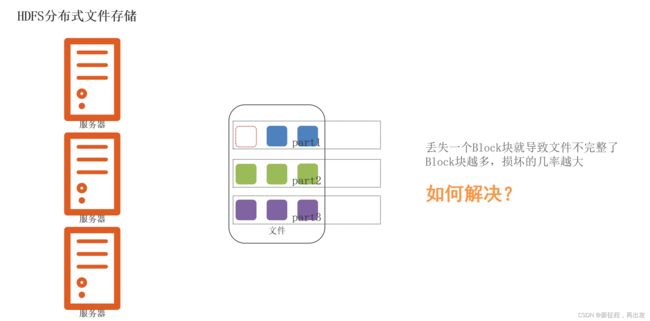
1.3.2、解决:通过副本(备份)

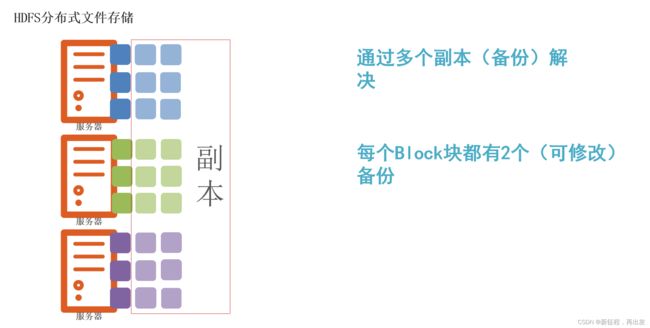
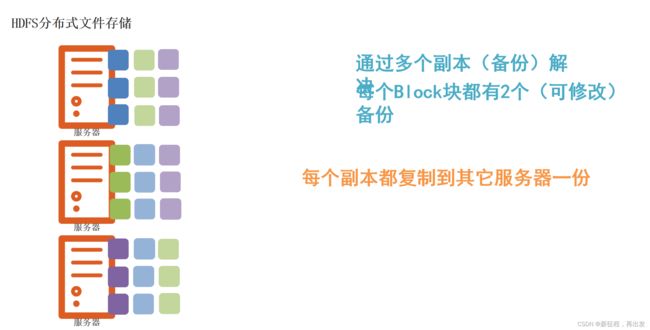


2、fsck命令
2.1、HDFS副本块数量的配置
2.1.1、系统设置
在前面我们了解了HDFS文件系统的数据安全,是依靠多个副本来确保的。
如何设置默认文件上传到HDFS中拥有的副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.replicationname>
<value>3value>
property>
这个属性默认是3,一般情况下,我们无需主动配置(除非需要设置非3的数值)。
如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性。
2.1.2、上传时命令设置
除了配置文件外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。
hadoop fs -D dfs.replication=2 -put text.txt /tmp/
![]()
如上命令,就可以在上传test.txt的时候,临时设置其副本数为2。
2.1.3、对已存在的文件修改
对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path


如上命令,指定path的内容将会被修改为2个副本存储。
-R选项可选,使用-R表示对子目录也生效。
2.2、fsck命令检查文件的副本数
我们可以使用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
fsck可以检查指定路径是否正常
2.2.1、列出路径内的文件状态
-files可以列出路径内的文件状态
hdfs fsck /it/fb -files

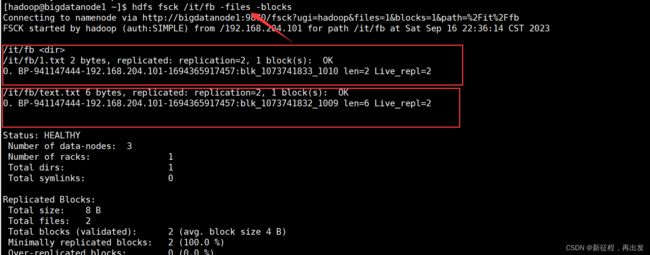
2.2.2、输出文件块报告
-files -blocks 输出文件块报告(有几个块,多少副本)
hdfs fsck /it/fb -files -blocks
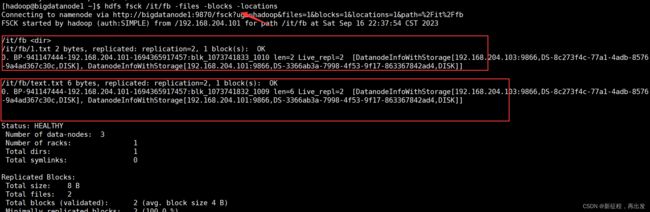
2.2.3、输出每一个block的详情
-files -blocks -locations 输出每一个block的详情
hdfs fsck /it/fb -files -blocks -locations
2.3、block配置
可以看到通过fsck命令我们验证了:
- 文件有多个副本
- 文件被分成多个块存储在hdfs
对于块(block),hdfs默认设置为256MB一个,也就是1GB文件会被划分为4个block存储。
块大小可以通过参数:
<property>
<name>dfs.blocksizename>
<value>268435456value>
<description>设置HDFS块大小,单位是bdescription>
property>
如上,设置为256MB
3、NameNode元数据
3.1、edits文件
在hdfs中,文件是被划分了一堆堆的block块,那如果文件很大、以及文件很多,Hadoop是如何记录和整理文件和block块的关系呢?
答案就在于NameNode
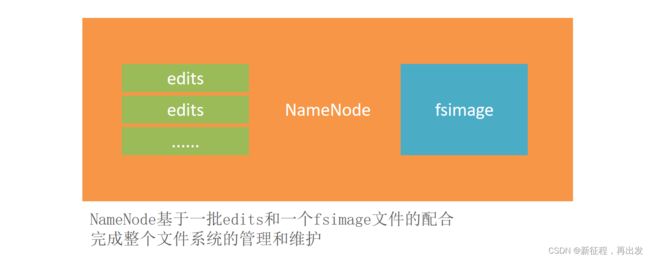
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block。
edits记录每一次HDFS的操作逐渐变得越来越大。


问题在于,当用户想要查看某文件内容,如:/tmp/data/test.txt
就需要在全部的edits中搜索(还需要按顺序从头到尾,避免后期改名或删除),效率非常低。
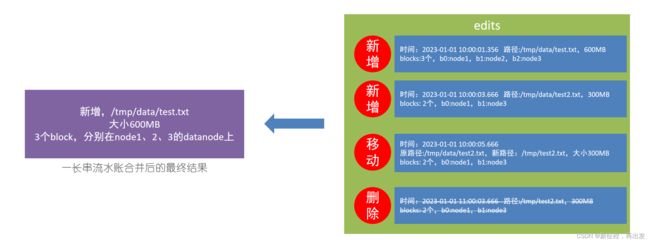
3.2、fsimage文件
将全部的edits文件,合并为最终结果,即可得到一个FSImage文件。

3.3、NameNode元数据管理维护
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
- 每次对HDFS的操作,均被edits文件记录
- edits达到大小上线后,开启新的edits记录
- 定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage。
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage。
3.4、元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
- dfs.namenode.checkpoint.period,默认3600(秒)即1小时
- dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个达到条件就执行。
检查是否达到条件,默认60秒检查一次,基于:
- dfs.namenode.checkpoint.check.period,默认60(秒),来决定
3.5、SecondaryNameNode的作用
对于元数据的合并,还记得HDFS集群有一个辅助角色:SecondaryNameNode吗?
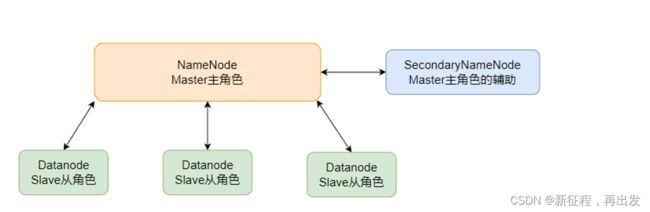
没错,合并元数据的事情就是它干的
- SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
- 然后合并完成后提供给NameNode使用。
4、HDFS数据的读写流程
4.1、数据写入流程
- 客户端向NameNode发起请求
- NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
- 客户端向指定的DataNode发送数据包
- 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
- 如图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
- 写入完成客户端通知NameNode,NameNode做元数据记录工作。

关键信息点:
- NameNode不负责数据写入,只负责元数据记录和权限审批。
- 客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个。
- 数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)。
4.2、数据读取流程
- 客户端向NameNode申请读取某文件。
- NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表。
- 客户端拿到block列表后自行寻找DataNode读取即可。

结束!!!!!!
hy:35
不要对人性抱以过高的期待,永远要警惕人性深处的幽暗,法治的前提就是对人性败坏的假设。