Spark基本概念以及环境搭建
Spark基本概念
一、什么是Spark

Apache Spark是用于大规模数据处理的统一分析引擎。
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark框架是基于Scala语言编写的。
二、Spark 和 Hadoop
Spark和Hadoop有什么关系?
从功能上来说:
Hadoop
- Hadoop是由java语言编写的,在分布式集群当中存储海量数据,并运行分布式应用的开源框架
- 作为 Hadoop 分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有的数据 ,支持着Hadoop的所有服务。它的理论基础源于Google的TheGoogleFileSystem这篇论文,它是GFS的开源实现。
- MapReduce是一种编程模型,Hadoop根据Google的MapReduce论文将其实现,作为Hadoop的分布式计算模型,是Hadoop的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了HDFS的分布式存储和MapReduce的分布式计算,Hadoop在处理海量数据时,性能横向扩展变得非常容易。
- HBase是对Google的Bigtable的开源实现,但又和Bigtable存在许多不同之处。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是Hadoop非常重要的组件。
Spark
- Spark是由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- SparkCore中提供了Spark最基础与最核心的功能
- SparkSQL是Spark用来操作结构化数据的组件。通过SparkSQL,用户可以使用SQL或者ApacheHive版本的SQL方言(HQL)来查询数据。
- SparkStreaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark 出现的时间相对较晚,主要功能主要是用于数据计算。而 Hadoop 中的HDFS、MapReduce、HBase可以分布式储存、计算。但是由于Spark主要是在内存中进行数据计算,Spark的计算速度会比MapReduce快上很多,也因为内存的问题,导致计算的不稳定。MapReduce计算虽然比较慢,但是计算的很稳定。
三、Spark核心模块

-
Apache Spark (Spark Core)
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX,MLlib 都是在 Spark Core 的基础上进行扩展的
-
Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
-
Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
-
Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
-
Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
Spark环境搭建
一、介绍

Spark的运行环境有Local模式、Standalone 模式、Yarn 模式、K8S & Mesos 模式、Windows 模式。
Standalone 模式、Yarn 模式、K8S & Mesos 模式,这三种模式就不介绍了,有兴趣的可以去官网查看。
二、Local模式和Windows 模式
Local模式
一般用于测试和教学,不适应开发,将下载好的文件,解压缩,进入解压缩后的目录中,运行bin/spark-shell,就启动了本地模式
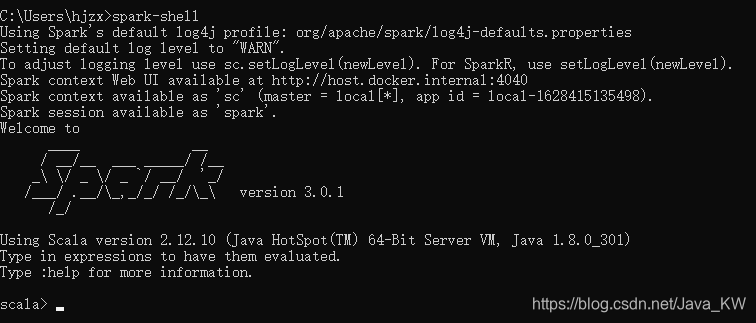
打开UI界面,如下:

启动之后,会自动创建一个SparkContext对象sc,使用它进行WordCount
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
可以输出WordCount。
Windows 模式
Spark支持Windows 环境运行Spark任务,以后大部分开发工作都是在这个模式下进行的,所以来进行配置一下。
要求:
- scala 2.12.11
- hadoop 2.7.1
- java 最好是1.8.0
- spark 3.0.1
将scala、hadoop、java、spark安装好,都添加到环境变量,接下来配置一下IDEA
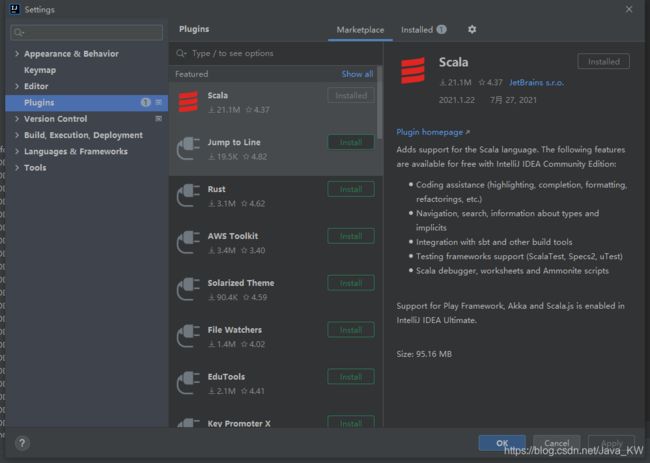
1、首先添加scala依赖
2、创建一个maven项目,sparkProject
3、修改pom.xml,添加相关依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>sparkProjectTextartifactId>
<version>1.0-SNAPSHOTversion>
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>apacheid>
<url>https://repository.apache.org/content/repositories/snapshots/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
<properties>
<maven.compiler.source>16maven.compiler.source>
<maven.compiler.target>16maven.compiler.target>
<encoding>UTF-8encoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<scala.version>2.12.11scala.version>
<spark.version>3.0.1spark.version>
<hadoop.version>2.7.5hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>${spark.version}version>
dependency>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.5.1version>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.18.1version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
4、新建一个文件夹scala
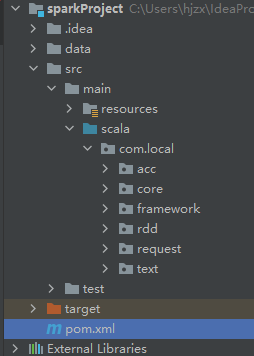
5、创建包,创建一个scala对象WordCount
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val words = lines.flatMap(_.split(","))
val wa = words.map((_, 1))
val res = wa.reduceByKey(_ + _)
res.foreach(println)
sc.stop()
}
}
6、运行一下,没有问题,就可以接下来的开发了
