【C++杂货铺】继承由浅入深详细总结

文章目录
- 一、继承的概念及定义
-
- 1.1 继承的概念
- 1.2 继承定义
-
- 1.2.1 定义格式
- 1.2.2 继承方式和访问限定符
- 1.2.3 继承基类成员访问方式的变化
- 二、基类和派生类对象赋值转换
- 三、继承中的作用域
- 四、派生类中的默认成员函数
-
- 4.1 默认构造函数
- 4.2 拷贝构造函数
- 4.3 赋值运算符重载函数
- 4.4 析构函数
- 五、继承与友元
- 六、继承与静态成员变量
- 七、复杂的菱形继承及菱形虚拟继承
-
- 7.1 虚拟继承解决数据冗余和二义性的原理
- 7.2 存偏移量的意义
- 7.2 虚继承解决数据冗余问题
- 八、继承的总结和反思
-
- 8.1 继承和组合
- 九、继承常见面试问题
- 十、结语
一、继承的概念及定义
1.1 继承的概念
继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称为派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计的复用。
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "peter";//姓名
int _age = 18;//年龄
};
class Student : public Person
{
protected:
int _stuid;//学号
};
class Teacher : public Person
{
protected:
int _jobid;//工号
};
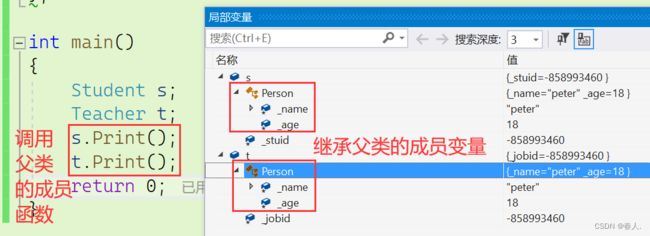
int main()
{
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
}
继承后父类 Person 的成员(成员函数 + 成员变量)都会变成子类的一部分。这里体现出了 Student 和 Teacher 复用了 Person 的成员。Student 除了继承了父类的成员外,它还有一个自己特有的属性 _stuid,表示学生的学号;Teacher 除了继承了父类的成员外,它也有一个自己特有的属性 _jobid,表示老师的工号。
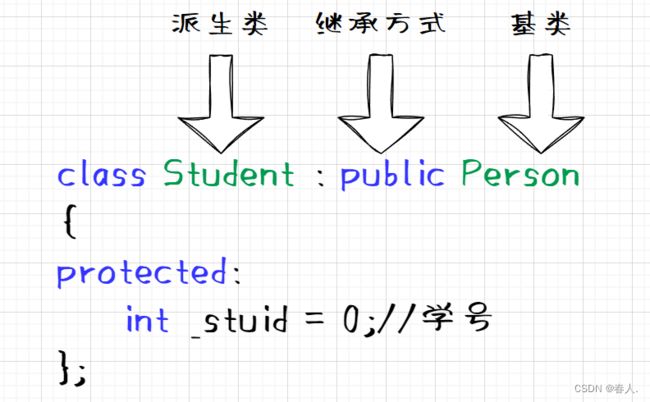
1.2 继承定义
1.2.1 定义格式
继承的定义格式如下图所示,其中 Person 是父类,也称作基类。Student 是子类,也称作派生类。
1.2.2 继承方式和访问限定符

1.2.3 继承基类成员访问方式的变化
| 类成员/继承方式 | public 继承 | protected 继承 | private 继承 |
|---|---|---|---|
| 基类的 public 成员 | 派生类的 public 成员 | 派生类的 protected 成员 | 派生类的 private 成员 |
| 基类的 protected 成员 | 派生类的 protected 成员 | 派生类的 protected 成员 | 派生类的 private 成员 |
| 基类的 private 成员 | 在派生类中不可见 | 在派生类中不可见 | 在派生类中不可见 |
总结:
-
基类 private 成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象,不管在类里面还是类外面都不能去访问它。
-
基类的 private 成员在派生类中是不能被访问的,如果基类成员不想在类外面直接被访问,但是需要在派生类中能访问,就定义为 protected。可以看出保护成员限定符是因为继承才出现的。
-
对上面的表格进行总结会发现,基类的私有成员在子类中都是不可见的。基类的其他成员在子类中的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected > private。
-
使用关键字 class 时默认的继承方式是 private,使用 struct 时默认的继承方式是 public,不过最好显示的写出继承方式。
-
在实际运用中一般使用都是 public 继承,几乎很少使用 protected 和 private 继承,也不提倡使用 protected 和 private 继承,因为 protected 和 private 继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
二、基类和派生类对象赋值转换
-
派生类对象可以赋值给基类的对象 、基类的指针、基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
-
基类对象不能赋值给派生类对象。
-
基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使用 RTTI (Run - Time Type Information)的 dynamic cast 来进行识别后进行安全转换。

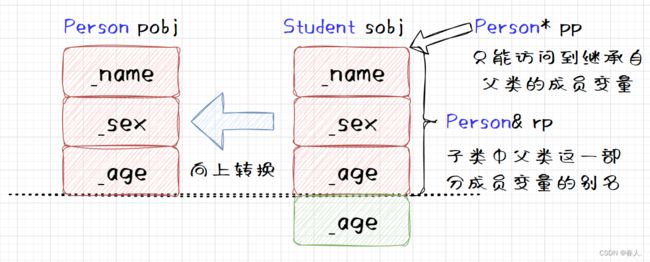
小Tips:这种将一个子类对象赋值给父类对象也叫做向上转换。将一个父类对象赋值给子类对象也叫做向下转换,是不被允许的。将一个子类对象赋值给父类对象,这种类型转换是不会产生中间的临时变量的。
class Person
{
protected:
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public:
int _No; // 学号
};
void Test()
{
Student sobj;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj;
Person* pp = &sobj;
Person& rp = sobj;
//2.基类对象不能赋值给派生类对象
//sobj = pobj;
}
小Tips:rp 此时就是子类对象中那部分父类成员的别名,并没有产生中间的临时变量。同理 pp 也指向子类对象 sobj,但是指针的类型决定了它能访问到的成员变量,因为 pp 是一个父类指针,因此 pp 就只能访问到子类对象中父类那部分成员变量。

小Tips:可以通过 rp 去修改其指向的子类对象中父类的那部分成员变量。
class Person
{
protected:
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public:
int _No; // 学号
};
void Test()
{
Student sobj;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj;
Person* pp = &sobj;
Person& rp = sobj;
//2.基类对象不能赋值给派生类对象
//sobj = pobj;
//3.基类的指针可以通过强制类型转换赋值给派生类的指针
pp = &sobj;
Student * ps1 = (Student*)pp; // 这种情况转换时可以的。
ps1->_No = 10;
pp = &pobj;
Student* ps2 = (Student*)pp; // 这种情况转换时虽然可以,但是会存在越界访问的问题
ps2->_No = 10;
}
小Tips:ps2->_No = 10; 会造成越界访问,而 ps1->_No = 10; 不会造成越界访问,原因在于 pp 指针的初始指向,以及指针的类型决定了该指针能访问到的内存空间。以上面的为例,pp 指针最初指向的是一个子类对象 sobj,并且 pp 指针是一个父类指针,这就决定了 pp 指针只能访问到子类对象中继承自父类的那部分成员变量,接着将 pp 指针进行强制类型转换,将它赋值给一个子类指针 ps1,此时 ps1 还是指向子类对象 sobj,但是 ps1 的类型却变成了 Student,这就决定了 ps1 可以访问到 sobj 中的所有成员变量(继承自父类的和子类特有的);而第二次类型转换,pp 指针作为一个父类指针,最初指向一个父类对象 pobj 这是没有任何问题的,接下来将 pp 指针进行强制类型转换,赋值给一个子类指针 ps2 ,此时 ps2 存的还是父类对象 pobj 的地址,指向 pobj,但它的类型是子类 Student,类型决定了它的访问范围,按说它可以访问到一个子类对象中的所有成员,但是它指向一个父类对象,该父类对象中就没有子类中的成员变量 _No,虽然它的类型决定了它可以访问到该成员变量,但是父类对象中没有,最终就会导致越界访问的问题。
三、继承中的作用域
-
在继承体系中基类和派生类都有独立的作用域。
-
子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫做隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
-
需要注意的是,如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
-
注意在实际继承里面,最好不要定义同名的成员。
小Tips:隐藏实际上是符合就近原则的,即对于一个变量,编译器默认先在当前成员函数的局部域去搜索,没找到接下来去当前成员函数所在的类域搜索。
// Student的_num和Person的_num构成隐藏关系,可以看出这样代码虽然能跑,但是非常容易混淆
class Person
{
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;//指定到父类中去找
cout << " 学号:" << _num << endl;//没有指定,现在局部域中找,局部域中没有 _num,接下来去当前的类域中找
}
protected:
int _num = 999; // 学号
};

// B中的fun和A中的fun不是构成重载,因为不是在同一作用域
// B中的fun和A中的fun构成隐藏,成员函数满足函数名相同就构成隐藏。
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
A::fun();
cout << "func(int i)->" << i << endl;
}
};
void Test()
{
B b;
//b.fun()//这样是不行的
b.A::func()//
b.fun(10);
};

小Tips:函数重载的前提是同一个作用域。重载底层使用了函数名修饰规则,在同一个作用域的同名函数如果不使用函数名修饰规则,编译器就无法区分这两个同名函数,而对于不同作用域的两个同名函数,编译器就直接根据域的查找规则就能进行区分。总结:父子类域中只要函数名相同就构成隐藏。如上面的代码所示,b.fun() 是不被允许的,编译器看到子类对象调用 fun 函数,会现在子类中进行查找,找到了但是发现少传一个参数,编译器会报错。一个子类对象如果想去调用父类中被隐藏(重定义)的函数,可以通过指定类域的方式去调用。
四、派生类中的默认成员函数
6个默认成员函数,“默认”的意思是指我们不写,编译器会帮我们自动生成一个,那么在派生类中,这几个成员函数是如何生成的呢?
-
派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
-
派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
-
派生类的
operator=必须要调用基类的operator=完成基类的复制。 -
派生类的析构函数会在被调用完成后,自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
-
派生类对象初始化先调用基类构造再调用派生类构造。
-
派生类对象析构清理先调用派生类析构再调用基类的析构。
-
因为后续一些场景析构函数需要构成重写,重写的条件之一是函数名相同。那么编译器会对析构函数名进行特殊处理,处理成
destrutor(),所以父类函数不加virtual的情况下,子类析构函数和父类析构函数构成隐藏关系。
4.1 默认构造函数
//默认构造函数
class Person
{
public:
Person(const char* name = "Peter", const char* sex = "男")
:_name(name)
,_sex(sex)
{
cout << "Person()" << endl;
}
protected:
string _name;//姓名
string _sex;
};
class Student : public Person
{
public:
Student(const char* name = "张三", const char* sex = "男", int num = 0)
:_num(num)
,Person(name, sex)
//, _name(name)//这样写是错的
{
cout << "Student()" << endl;
}
protected:
int _num;//学号
};
void Test()
{
Student s;
}
小Tips:不能在派生类构造函数的初始化列表中去初始化某一个单独的基类成员变量,即 _name(name) 是不允许的,只能进行整体初始化,像 Person(name, sex) 这样。 其次会先去调用基类的构造函数,说明继承自基类的成员变量一定是声明在派生类成员变量的前面的。
4.2 拷贝构造函数
//拷贝构造函数
class Person
{
public:
//默认构造函数
Person(const char* name = "Peter", const char* sex = "男")
:_name(name)
,_sex(sex)
{
cout << "Person()" << endl;
}
//拷贝构造函数
Person(const Person& p)
:_name(p._name)
,_sex(p._sex)
{
cout << "Person(const Person& p)" << endl;
}
protected:
string _name;//姓名
string _sex;//性别
};
class Student : public Person
{
public:
//默认构造函数
Student(const char* name = "张三", const char* sex = "男", int num = 0)
:_num(num)
,Person(name, sex)
//, _name(name)
{
cout << "Student()" << endl;
}
//拷贝构造函数
Student(const Student& s)
:Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
protected:
int _num;//学号
};
void Test()
{
Student s("张伟", "男", 213);//调用默认构造函数
Student s1(s);//调用拷贝构造函数
Student s2;
s2 = s1;//调用赋值运算符重载
//Person p = s1;
}
小Tips:派生类的拷贝构造函数也必须调用基类的构造函数,像这样 Person(s),这里用到了我们上面提到的一个知识点,即一个派生类对象可以赋值给一个基类的引用,该引用是派生类对象中基类那部分成员变量的别名。这里如果不写 Person(s),虽然这里是拷贝构造函数,但是编译器默认会去调用基类的默认构造函数,并不会去调用基类的拷贝构造函数。
4.3 赋值运算符重载函数
//赋值运算符重载
class Person
{
public:
//默认构造函数
Person(const char* name = "Peter", const char* sex = "男")
:_name(name)
,_sex(sex)
{
cout << "Person()" << endl;
}
//拷贝构造函数
Person(const Person& p)
:_name(p._name)
,_sex(p._sex)
{
cout << "Person(const Person& p)" << endl;
}
//赋值运算符重载
Person& operator=(const Person& p)
{
if (this != &p)
{
cout << "Person& operator=(const Person& p)" << endl;
_name = p._name;
_sex = p._sex;
}
return *this;
}
protected:
string _name;//姓名
string _sex;//性别
};
class Student : public Person
{
public:
//默认构造函数
Student(const char* name = "张三", const char* sex = "男", int num = 0)
:_num(num)
,Person(name, sex)
//, _name(name)
{
cout << "Student()" << endl;
}
//拷贝构造函数
Student(const Student& s)
:Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
//赋值运算符重载
Student& operator=(const Student& s)//与父类的赋值运算符重载构成隐藏
{
if (this != &s)
{
cout << "Student& operator=(const Student& s)" << endl;
Person::operator=(s);
_num = s._num;
}
return *this;
}
protected:
int _num;//学号
};
void Test()
{
Student s("张伟", "男", 213);//调用默认构造函数
Student s1(s);//调用拷贝构造函数
Student s2;
s2 = s1;//调用赋值运算符重载
}
小Tips:对于赋值运算符重载需要注意,因为赋值运算符重载的函数名都是 operator=,因此父类的复制运算符重载函数和子类的赋值运算符重载函数构成隐藏(重定义)关系。所以在子类的赋值运算符重载函数中要想调用父类的赋值运算符重载函数需要指定类域,像这样 Person::operator=(s);,告诉编译器这里调用的但是父类中的赋值运算符重载函数,如果不指定类域,编译器默认会去调用子类自己的赋值运算符重载,这就会产生无穷递归,导致栈溢出。
4.4 析构函数
class Person
{
public:
//默认构造函数
Person(const char* name = "Peter", const char* sex = "男")
:_name(name)
,_sex(sex)
{
cout << "Person()" << endl;
}
//拷贝构造函数
Person(const Person& p)
:_name(p._name)
,_sex(p._sex)
{
cout << "Person(const Person& p)" << endl;
}
//赋值运算符重载
Person& operator=(const Person& p)
{
if (this != &p)
{
cout << "Person& operator=(const Person& p)" << endl;
_name = p._name;
_sex = p._sex;
}
return *this;
}
//析构函数
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name;//姓名
string _sex;//性别
};
class Student : public Person
{
public:
//默认构造函数
Student(const char* name = "张三", const char* sex = "男", int num = 0)
:_num(num)
,Person(name, sex)
//, _name(name)
{
cout << "Student()" << endl;
}
//拷贝构造函数
Student(const Student& s)
:Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
//赋值运算符重载
Student& operator=(const Student& s)//与父类的赋值运算符重载构成隐藏
{
if (this != &s)
{
cout << "Student& operator=(const Student& s)" << endl;
Person::operator=(s);
_num = s._num;
}
return *this;
}
//析构函数
~Student()
{
cout << "~Student()" << endl;
//Person::~Person();//显示调用会导致析构两次的问题
}
protected:
int _num;//学号
};
void Test()
{
Student s("张伟", "男", 213);//调用默认构造函数
Student s1(s);//调用拷贝构造函数
Student s2;
s2 = s1;//调用赋值运算符重载
Person p = s1;//直接调用父类的拷贝构造函数
}
小Tips:对于析构函数来说,为了保证析构的顺序(对于一个子类对象来说,它里面的父类部分先调用构造,子类部分后调构造,从栈帧的创建顺序来说,后构造的要先析构,因此需要先去析构清理子类的资源,再去调用父类的析构函数,清理子类对象中父类中的那部分资源),编译器会自动去调用父类的析构函数,因此无需我们自己显示去调用父类的析构函数。其次,由于后面多态的原因,析构函数的函数名被特殊处理了,统一处理成 destructor,因此父类的析构函数与子类的析构函数本质上构成隐藏(重定义)关系,如果想要在子类的析构函数中显示调用父类的析构函数,需要指定类域,和赋值运算符重载函数一样。但是注意!注意!根本不需要我们自己在子类的析构函数中去显示调用父类的析构函数,即使我们显示调用了,编译器还是会去自动调用父类的析构函数,这就会导致子类中父类的那部分资源被释放了两次,这就会产生问题。先析构子类还有一个原因,即子类的析构函数中可以使用父类中的成员变量,如果先调用父类的析构函数,那么在子类的析构函数中就无法再使用父类中的成员变量。而在父类的析构函数中是不可能调用子类的成员变量,因此先调用父类的析构函数是没有任何问题的。
五、继承与友元
友元关系不能继承,也就是说基类中声明的友元函数不能访问子类中的私有和保护成员。
//友元关系不能继承
class Student;//先声明
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name = "Peter"; // 姓名
};
class Student : public Person
{
protected:
int _stuNum = 1111; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
//cout << s._stuNum << endl;//并不是子类的友元,因此不能在函数中访问子类的成员变量
cout << s._name << endl;
}
void Test()
{
Person p;
Student s;
Display(p, s);
}
小Tips:如上面的代码所示,Display 函数仅仅是父类 Person 的友元函数,并不是子类 Student 的友元函数,因此在 Display 函数中只能调用到父类中的成员变量,并不能调用子类中的成员变量,即在 Display 函数中 s._stuNum 是不被允许的。也可以调用一个子类对象中父类的那部分成员变量。
六、继承与静态成员变量
基类定义了 static 静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有这一个 static 成员实例。
class Person
{
public:
Person() { ++_count; }
protected:
string _name; // 姓名
public:
static int _count; // 统计人的个数。
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum; // 学号
};
class Graduate : public Student
{
protected:
string _seminarCourse; // 研究科目
};
void Test()
{
Student s1;
Student s2;
Student s3;
Graduate s4;
cout << "人数 :" << Person::_count << endl;
Student::_count = 0;
cout << "人数 :" << Person::_count << endl;
}

小Tips:静态成员属于父类和派生类(他俩共享),在派生类中不会单独拷贝一份,继承的是静态成员的使用权。上面这段代码用一个静态成员变量 _count 来统计创建出来的父类对象和子类对象的个数,只需要在父类的构造函数中执行 ++_count 即可,因为创建子类对象的过程中会去调用父类的构造函数。
七、复杂的菱形继承及菱形虚拟继承
单继承:一个子类只有一个直接父类时称这个继承关系为单继承。
多继承:一个子类有两个或两个以上的直接父类时称这个继承关系为多继承。
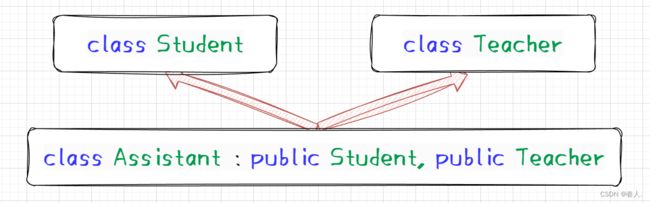
菱形继承:菱形继承是多继承的一种特殊情况。
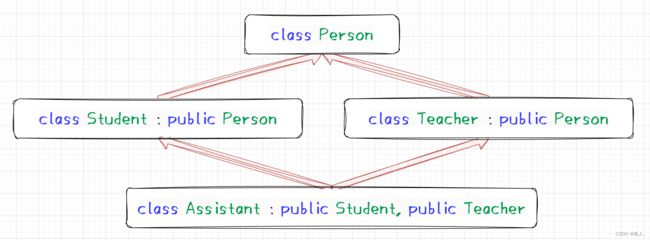
菱形继承存在的问题:从下面的对象成员模型构造,可以看出菱形继承有数据冗余和二义性的问题。在 Assistant 的对象中 Person 的成员变量会有两份。

class Person
{
public:
string _name;//姓名
int _age;//年龄
};
class Teacher : public Person
{
protected:
int _id;//职工号
};
class Student : public Person
{
protected:
int _num;//学号
};
class Assistant : public Teacher, public Student
{
protected:
string _majorCourse;//主修课程
};
void Test()
{
Assistant a;
a._age = 10;
}

小Tips:对 _age 访问不明确,其实就是二义性问题。想要解决二义性问题,我们可以通过指定类域去访问,像下面这样。
void Test()
{
Assistant a;
a.Teacher::_age = 10;
a.Student::_age = 18;
}

小Tips:上面这样虽然解决了二义性问题,但是对于面向对象的语言来说,这样是不符合逻辑的,因为一个人不可能同时拥有两个年龄。并且数据冗余还是没有得到解决。因此下面需要引入虚拟继承,虚拟继承可以解决菱形继承的二义性和数据冗余的问题。如上面的继承关系,在 Student 和 Teacher 继承 Person 时使用虚拟继承,即可解决问题。需要注意的是,虚拟继承不要在其它地方去使用。
class Person
{
public:
string _name = "Peter";//姓名
int _age = 0;//年龄
};
class Teacher : virtual public Person
{
protected:
int _id = 0;//职工号
};
class Student : virtual public Person
{
protected:
int _num = 0;//学号
};
class Assistant : public Teacher, public Student
{
protected:
string _majorCourse;//主修课程
};

7.1 虚拟继承解决数据冗余和二义性的原理
为了研究虚拟继承的原理,我们给出了一个简化的菱形继承体系,再借助内存窗口观察对象成员的模型。
class A
{
public:
int _a;
};
class B : public A
//class B : virtual public A
{
public:
int _b;
};
class C : public A
//class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
void Test()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
}

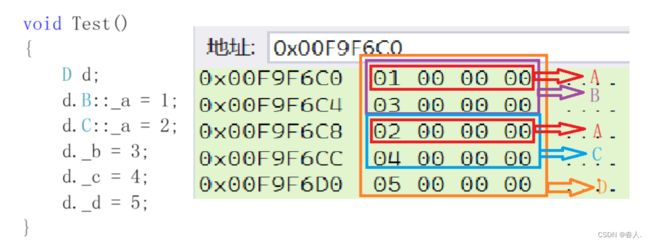
小Tips:上图是普通菱形继承的对象成员在内存中的模型。可以看出内存中存储了两个 _a 成员变量,一个是继承自 B 的,另一个是继承自 C 的。下面再来看看虚拟继承的对象成员在内存中的存储模型。
class A
{
public:
int _a;
};
class B : virtual public A
//class B : virtual public A
{
public:
int _b;
};
class C : virtual public A
//class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
void Test()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
d._a = 10;
}

小Tips:虚拟继承的对象成员在内存中的存储模型发生了很大的变化。首先 A 类型的成员变量 -a 从 B 类型和 C 类型中脱离了出来,普通的菱形继承,_a 会在 B 类型 和 C 类型中各自存储一份,造成数据冗余和二义性,而在菱形继承中,A 类型的成员变量 _a 只会在内存空间中存储一份。另一个变化是,B 类型和 C 类型中分别多出了一个数据,如 B 中的 00ff7bdc 和 C 中的 00ff7be4,这俩很明显都是地址,根据地址去查找对应内存空间中存储的数据,可以发现, B 类型中的这个地址空间中存储了一个 14,这里的 14 是十六进制,转化成十进制是 20,而 20 正好是 B 类型的首地址 0x00EFFBA0 和 A 类型首地址 0x00EFFBB4 之间的距离。同理,C类中的这个地址空间中存储的 0c 转化成十进制是 12,就是 C 类型的首地址 0x00EFFBA8 和 A 类型的首地址 0x00EFFBB4 之间的距离。这里可能就会有小伙伴想问,为什么不把这个相对距离直接存在 D 类型的对象中,而是单独在内存中开了块空间去存储。首先,因为这里不仅需要存储相对距离,还需要存储一些其它的信息。其次,我们可能同时创建多个 D 对象,对这多个 D 对象来说,它们的偏移量都相同,如果在所有的 D 类型对象中都存储一份,在数据量大的时候会造成极大地浪费,因此我们可以把这部分“固定不变”的信息提取出来,单独在内存中开辟一块空间去存储,然后在 D 类型的对象中存上该空间的地址即可,这样做可以在数据量大的时候,可以有效的节省空间,提高内存利用率。
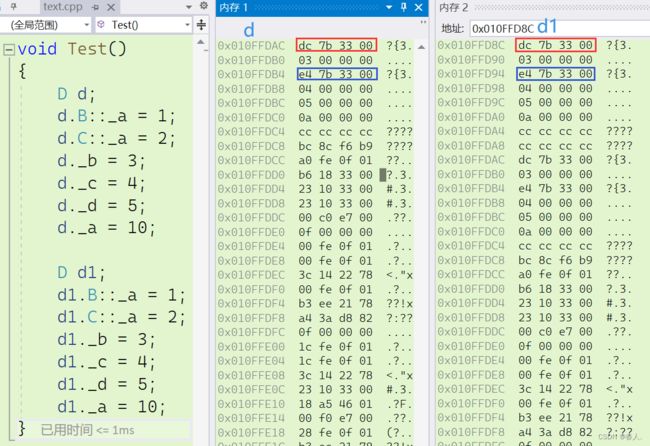
小Tips:如上图所示,我们同时创建了两个 D 类型的对象,d 和 d1,它们在内存空间中都存了相同的地址 0x00337bdc 和 0x00337be4,这两个地址空间中分别存储的是 B 类型 和 A 类型的相对距离,C 类型和 A 类型的相对距离。存储偏移量的这块空间也被形象的叫做虚基表(找基类偏移量的表),但是需要注意虚基表中不止会存储偏移量,还会存储一些其他信息,具体内容将在下一篇关于多态的文章中为大家揭晓,感兴趣的朋友们不妨先点一个关注。
7.2 存偏移量的意义
void Test()
{
D d;
d._a = 10;
}
如上面代码所示,定义一个普通的 D 类型对象 d,然后去访问它里面的成员变量 _a,这种情况下是用不到偏移量的。偏移量的作用是去找 D 对象中“爷爷类”的成员(即父类的父类,这也就是 A 类),对于普通的 D 类型对象 d 来说,在定义该对象的时候,编译器会根据声明顺序依次为成员创建栈帧(依次分配空间进行存储),所以对编译器来说,它知道 _a 这个成员变量就存储在哪,所以当我们执行 d._a = 10 的时候,编译器会直接找到这块内存空间,并不需要通过虚基表去查找偏移量。存偏移量的真正用途是为了下面这种情况。
void Test()
{
D d;
d._a = 1;
d._b = 2;
d._c = 3;
d._d = 4;
B b;
b._a = 1;
b._b = 2;
B* ptr = &b;
ptr->_a++;
ptr = &d;
ptr->_a++;
}
小Tips:这里我们首先需要明确一点,在虚继承体系中,B 对象成员在内存中的存储模型相较于普通的继承也发生了改变,它也会涉及到虚基表。
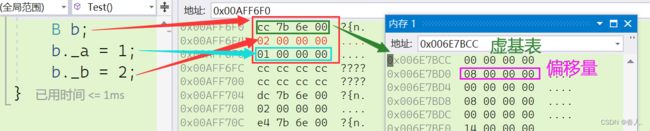
明确了这一点后,我们继续看看上面的代码,我们定义了一个 B 类型的指针 ptr,该指针可以指向一个 B 类型的对象,也可以指向一个 D 类型的对象(注意,只能访问到 D 类型对象中 B 中的成员)。虽然 ptr 可以指向不同类型的对象,但是 ptr 始终都是 B 类型,这就决定了,无论你 ptr 指向什么类型的对象,你都只能访问到 B 类中有的成员,即 ptr 最多只能访问到 _a 和 _b 这两个成员。ptr 作为一个指针变量,在转换成指令后,它并不知道它指向的是谁,它只是存了一个地址,如果 ptr 存的是一个 B 类型对象的地址,那它的 _a 和 _b 在内存空间上是连续的,但是如果 ptr 存的是一个 D 类对象的地址,那它的 _a 和 _b 在内存空间中并非连续的。中间可能隔着一些其他类型。而指针的工作原理是,首先指针一定存的是一个变量的首地址,其次指针的类型决定了它从该变量的首地址开始,可以访问到多少个连续的空间。以 int 型的指针为例,他可以访问到连续的四个字节,对 int 型的指针 +1,会自动跳过四个字节。再回到这里,当 ptr 存的是一个 D 类对象的首地址,ptr 可以访问到的成员并不连续,那指针就无法找到 _a 了,此时存偏移量的作用就体现出来了,ptr 可以通过虚基表,查找到偏移量,进而找到 _a 成员。此时无论 ptr 是指向 B 类型的对象还是指向 D 类型的对象,当 ptr 要去访问 _a 的时候,都会转化成先取偏移量,在计算 _a 在对象中的地址,再去访问。
7.2 虚继承解决数据冗余问题
还是以上面的代码为例,一个 D 类型对象中和 A 类型有关的成员变量的大小(字节数)在比较小的情况下,那么这个 D 类型对象在虚继承体系下的大小(字节数)可能还会大于普通继承体系下创建的 D 类型对象,上面的代码在普通继承体系下,一个 D 类型对象的大小是 20 字节,在虚继承体系下是 24 字节。

出现这种虚拟继承体系下创建的对象比普通继承体系下创建的对象大的主要原因是 A 类型中的成员变量太少了,所占用的内存空间太小了,导致虚拟继承的支出大于收益,如果 A 中的成员变量比较多,或者是一个大数组,那么,虚拟继承解决普通继承体系下的数据冗余功能就可以体现出来了。
八、继承的总结和反思
很多小伙伴觉得 C++ 语法复杂,其实多继承就是一个体现。有了多继承,就存在菱形继承,有了菱形继承就存在数据冗余和二义性问题,为了解决数据冗余和二义性问题,又引入了菱形虚拟继承,底层实现就很复杂。所以一般不建议设计出多继承,一定不要设计出菱形继承。否则在复杂度及性能上都有问题。多继承可以认为是 C++ 的缺陷之一,后来很多的 OO 语言都没有多继承,如 Java。
8.1 继承和组合
-
public 继承是一种 is-a 的关系。也就是说每个派生类对象都是一个基类对象。
-
组合是一种 has-a 的关系。即在 B 类里面声明一个 A 类型的成员变量。这样以来每个 B 对象中都有一个 A 对象。
-
优先使用对象组合,而不是继承。
-
继承允许我们根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见。继承在一定程度上破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类之间的依赖关系很强,耦合度高。
-
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组长或者组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为“黑箱复用”,因为对象的内部细节是不可见的。对象只是以“黑箱”的形式出现。组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助与我们保持每个类被封装。
-
实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。
九、继承常见面试问题
//下面这段代码的输出结果是?
class A {
public:
A(const char* s)
{
cout << s << endl;
}
~A()
{}
};
class B :virtual public A
{
public:
B(const char* s1, const char* s2)
:A(s1)
{
cout << s2 << endl;
}
};
class C :virtual public A
{
public:
C(const char* s1, const char* s2)
:A(s1)
{
cout << s2 << endl;
}
};
class D :public B, public C
{
public:
D(const char* s1, const char* s2, const char* s3, const char* s4)
:B(s1, s2)
,C(s1, s3)
,A(s1)
{
cout << s4 << endl;
}
};
int main() {
D* p = new D("class A", "class B", "class C", "class D");
delete p;
return 0;
}

小Tips:解决本题的关键在于我们要知道知道以下两点。第一点:对与虚拟继承来说,虽然 D 类看上去只继承了 B 类和 C 类,但是它是一种菱形继承,B 类和 C 类都继承了 A 类,所以从某种意义上讲,D 类也继承了 A 类,又因为这里是菱形虚拟继承,A 类中的成员变量在 D 类中只有一份。这里要求在 D 类构造函数的初始化列表中先去调用 A 类的构造函数,因此如果在 A 类没有默认构造函数的情况下就需要我们自己在初始化列表中显式的去写调用 A 类构造函数的语句。在第四小节中我们提到过:派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。第二点需要我们掌握的是:在派生类构造函数的初始化列表中成员变量的初始化顺序,是按照继承的先后顺序来的,先去调用第一个被继承的类的构造函数,再去调用第二个被继承的类,依此类推,最后再去初始化当前类自己的成员变量,以上面代码为例:class D :public B, public C,D 类先继承 B,再继承 C,但是需要注意,这是个菱形虚拟继承,B 类和 C 类都继承自 A 类,所以编译器最先去调用 A 类的构造函数,接下来再去调用 B 类的构造函数,然后再去调用 C 类的构造函数,这里还需要注意一点,虽然在 B 类和 C 类构造函数的初始化列表中都显示的写了调用了 A 类构造函数的语句,但是这是菱形虚拟继承,创建 D 对象的第一步就去调用了 A 类的构造函数,所以在调用 B 类和 C 类构造函数的过程中编译器并不会再去调用 A 类的构造函数。虽然在创建 D 对象的过程中编译器并不会去执行 B 类和 C 类构造函数中调用 A 类构造函数的语句,但是我们不能把这条语句给删了(除非 A 类有默认构造),因为这条语句不执行仅仅是在创建 D 类对象的过程中,我们也可能会去创建 B 类对象和 C 类对象,此时该语句就会被执行。有了上面这些知识储备就不难知道上面这段代码的打印结果了。
//p1、p2、p3它们三个的关系是什么?
class Base1
{
public:
int _b1;
};
class Base2
{
public:
int _b2;
};
class Derive : public Base1, public Base2
{
public:
int _d;
};
int main()
{
Derive d;
Base1* p1 = &d;
Base2* p2 = &d;
Derive* p3 = &d;
printf("p1:%p\n", p1);
printf("p2:%p\n", p2);
printf("p3:%p\n", p3);
return 0;
}

小Tips:这里的结果和继承顺序有关,p3 作为一个 Derive 类型的指针,它必定是指向 d 对象的首地址,首地址一定是存储当前对象的内存空间中地址编号最小的,即低地址处。从上面的代码中我们可以看出,Derive 对象先继承了 Base1,这就决定了一个 Derive 对象 d 在内存中 Base1 的成员变量一定是存储在最前面的,即低地址处,也就是 Derive 对象的首地址。p1 作为一个 Base1 类型的指针,它只能指向 d 对象中继承自 Base1 的成员变量,而 Base1 的成员变量就存在地址编号最小的那块内存空间上,因此 p1 == p3。Derive 第二个继承的是 Base2,存储 Base2 成员变量的空间依次往后,自然就不是 d 的首地址,这就导致了 p1 == p3 != p2。
十、结语
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,春人的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是春人前进的动力!