热修复Class流派和Dex流派实现原理
Class流派原理
基本原理:加载类的时候是找element,每个element对于一个dex。我要把我修复的那个类单独放到dex插入dexlist前面,在你做类加载从前往后找优先从你的dex加载加载的就是你修复后的class.这就是
实现代码
-
通过context拿到pathClassLoader,根据你下发的dex生成一个dexclassloader。
-
拿到两个的pathlist,在拿到两个pathlist的element,然后把生成的dexclassloader的element放到pathclassloader的element前面。然后把合并后的element赋值给pathclassloader的element
Davlik虚拟机上遇到的问题
unexpectDex崩溃
davlik虚拟机上会抛出unexpectDex崩溃()
业务情况:A引用了待修复的B类(下发的类)
抛出unexpectDex崩溃同时满足的三个条件
抛出这个崩溃需要同时满足三个条件: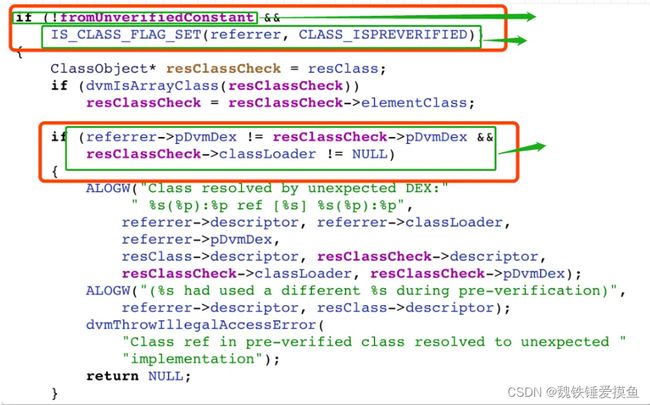
- 补丁类不是通过静态类或者instance of的方式被引用
- 引用下发补丁的类在dexopt阶段verify成功,引用类被打上了CLASS_ISPERVRIFYIED的标志
- 这两个类不在一个dex上
在你app加载被引用类的时候(A引用B,也就是加载B类的时候)会做这样一个校验,如果你同时满足这三个条件就会崩溃
由于补丁类是单独的放在一个dex中所以第三个条件没法变。只能从1和2入手
应用安装的时候需要一个dexopt阶段,会对你的dex进行优化成odex后续运行加载的odex才能运行
dexopt阶段的过程
检查静态方法,私有方法,构造函数,虚方法所调用的类是否根当前类在同一个dex中(A在调用上面方法时调用的BCDE类是否和A类在同一个dex上)
在同一个dex上,虚拟机就会对A类做一些优化并打上CLASS_ISPREVERIFIED标志
比如A引用B。并且A和B在一个dex里的时候A类会打上CLASS_ISPERVRIFYIED标志
何时抛出异常
在之后加载A类(dexopt阶段标记的类)的时候虚拟机会检查Verfiy标记的结果进行反向做verfiy的校验
当校验的时候同时满足上面三个条件的话就不通过抛出unexceptDex异常,只有校验通过才会吧类加载上来
QZone插桩组织preverify方案
这个方案肯定不满足第三个条件,所以只能从第一个或第二个条件下手
QZone从第二个条件入手通过插妆阻止preverify
解决思路:当上面那些特殊方法(构造函数,静态函数...)调用的是同一个dex上的类会被标志,那么我跨dex访问就不会打上标志。最简单的就是在构造函数里面进行访问跨dex即可,这样不在同一个dex就不会打标志
实现:
创建一个空的类放到一个独立的dex上
在所有类的构造函数里面都去访问那个独立dex里面空的类,所有的类都存在一个跨dex的访问,所以整个app里面的所有类都不会被打伤标志
但是独立的dex需要先被加载进来,因为APP的PathClassLoader找不到这个类。利用双亲委派模型机制(加载类的时候先从缓冲中找)先把这个空类加载进来后续就可以访问到这个类了。
缺点:
影响了odex的校验和优化过程存在一个性能的问题
降低APP启动性能,运行内存增加
Qfix提前constclass引用方案
从抛出的第一个条件入手
针对静态类调用和instanceof这两种方式以外的方式会抛异常
如果我以静态类来调用补丁类的话即使存在跨dex调用被打伤标志也不会抛出异常,同时classloader加载类的时候只要加载过会优先从缓存里面读利用这个机制。
davlik虚拟机加载类的过程:
先会从dex的缓存里面找如果有就直接返回不会有后续的校验和加载过程,后面加载和校验完成后也会放到dex的缓存里面
实现思路
APP启动的时候把补丁类放进来以后,提前以静态方式引用补丁类,这个引用不会抛异常(静态类引用方式)同时会让这个补丁类提前加载到虚拟机的缓存中,后面的访问即使是非静态的即使有标志冲突的也不需要进行校验了。可以直接返回后续从缓冲中读到这个类
实现代码:
- 在application最开始的地方用静态类方式加载补丁类,但是我们并不知道要修复哪个类,所以不可能在application里面把所有的类都加载一遍(哈哈哈,不科学)
- QFix通过nativehook直接调用虚拟机加载类的native方法,APP打包的时候保存了各个类的dexId和classId。在运行的时候找到补丁类所在的dexid和classid在jni侧主动调用虚拟机解析class的方法(设置formUnverifedConstant参数为true代表这次的调用是以constantof或者是以instanceof的方式调用进来,这个为true就不会做preverify的校验),这一次调用你的补丁就在缓存里面了,后续使用就直接从缓存里面找就可以,也不需要进行校验了
因为调用的是虚拟机的native方法加载类,所以在不同虚拟机上有较多的适配,同时会有稳定性的问题。分享文档里面说出来在在X86上有问题
Art虚拟机上遇到的问题
不仅仅是下面级联优化的问题,还有其他问题在dex流派上在标注
Art虚拟机上由于方法内联会带来更大的问题,不管是哪个虚拟机在安装阶都有个dex优化的过程
不同安卓版本有不同的odex编译器,早期编译器用的是QuickCompile后面用的比较多的是OptimizingCompare
不同的编译器进行方法内联时有不同的方法条件,并且Optiminzing有级联优化操作(method1调用method2里面调用method3里面调用method4)如果这些调用的方法都满足虚拟机的内联条件。
最终编译后的method1里面直接包含了method2method3method4的代码(方法
2包含3和4的代码,3包含4的代码),内联的意思是把代码直接写进来而不是通过方法id进行调用
问题
假如ClassA正好要引用你的补丁类,而补丁类之前在虚拟机优化的时候满足内联条件,那么老的方法已经被写到引用类里面了。这时候在下发新的class修复的时候可以正常加载class,但是方法的调用并没有调用到你的新类class上来,因为你的实现已经被写到引用类里面了。就会存在问题
由于内联,执行流程并未跳转到新的方法里面,引用类里面的方法是用的老的方法。对于引用类来说用的还是老方法中局部变量表存放的内容 所以查找成员字符串都是用的旧方法的索引。但是新的补丁类索引是可能发生变化的引用类访问的时候就会出现crash出错的问题。
解决方法
由于级联优化的存在因此把你要修复的类,你的子类,调用你的类都必须整个放到patch里面,下发整个patch,所以整个patch会很大
Dex流派热修复原理
class是干扰的系统api较为底层所以存在适配和兼容性问题。
后来tinker走上了dex存量热修复的路径
原理:进行全量dex的替换,但是不可能吧整个dex下发,所以下发的是dex的diff。
新老dex的diff在服务端生成,通过diff算法:
Sigma用的是比较常见的BsDiff
tinker做的比较深入依据dex结构发明了一个dexdiff算法,让你diff差异包更小,合成效率更高
步骤
- 服务端生成了新老dex的diff之后就会生成差异包。差异包会被你的patch进程请求到和本地依据安装的dex进行merge成新的dex也就是通过patch还原成新的dex
- 通过新dex创建出一个新的dexclassloader,把这个新dexclassloader设置成App的pathclassloader的parent。根据双亲委派模型你加载的就是新的dexclassloader,也就是修复后的类
修复为什么要在独立进程做?
- 即使业务进程无线崩溃,patch进程也能修复你的问题
- 业务进程可能在做迭代,做合并可能会出现crash
- 独立进程中做的话不依赖于主进程启动,其他业务进程的启动也可以吧patch进程拉起来进行统一的修复
注意点
parch进程中PathCore合并核心代码中的一些操作是和Application一起由PathClassLoader加载的,如果你的pathcore调用了你的业务逻辑没有做解耦的话, 那么这个时候path会加载你的旧业务的类(由pathclassloader加载),由于双亲委派模型后续这些旧业务的类是从pathClassLoader缓存拿的而不是从你patch进程做完合并后的dexclassloader拿的就会出现问题导致调用类和加载类不一致,所以需要进行和业务解耦。
就是如果在生成新的dex替换pathclassloader的parent之前访问了之前的类,那么是由pathClassLoader加载的,就会导致加载的类是旧的dex。而因为有缓存,一直是拿的pathClassLoader加载的类而不是合并后修复完成的dexClassLoader的类
基本的共性问题
dex的热修复有一些基本典型的问题需要解决:
- patch的入口和patch的核心业务需要和业务进行隔离
- patch合并需要放到独立进程做
- 每次打包的mapping会变化:如果不对混淆进行干预,每次打包的混淆规则是会变化的,所以会导致哪怕是很小的改动也会导致两个包的dex差异非常大所以需要对混淆的mapping进行保存,在打新包的时候apply这个mapping就会保持混淆一致不会导致差异
- 每次打包的分包结果会变化:如果APP大的话,会存在跨dex访问(针对这种多dex情况哪怕你没有修改也会导致他的分包结果不一样)。所以在打基准包的时候也要把他的分包结果保存下来(打新包时按照这个结果进行分包)
- patch进程做完patch合并之后,主进程利用patch的时候会立马黑屏或者anr。虚拟机是不会直接访问dex的有个dexopt阶段(应用安装时候做的,动态加载dex时也会做这个阶段)。dexopt是由系统触发的。所以会黑屏就是因为你的主进程直接用得动态加载的dex触发了dexopt导致黑屏。所以在patch进程合并完新的dex之后应该立刻去触发dexopt.
如何触发dexopt
直接手动new一个dexclassloader,然后虚拟机就会做全量的dexopt在独立进程中(虽然dexopt过程放到了独立的patch进程做,但是还是会存在部分anr,后面问题在列出)
Art dex2oat对热修复影响
dex2oat是对dex进行编译的一个进程。在art虚拟机上你的dex是需要编译成机器码以后才能被虚拟机加载和运行的
dex2oat编译模式
编译过程有十几种模式,比较关心的只有三种:
- interpret only:该模式在first boot或者install的时候(第一次启动或者安装)进行。只会做verify,代码还是解释执行,不做机器码的编译操作。性能是和davlik虚拟机保持一致
- speed:该模式在new DexClassLoader的时候触发。会做全量的机器码编译
- speed profile:该模式在系统做oat升级的时候或者混合编译(有一个background的dexopt在系统idle的时候会唤醒做dexopt)的时候,他只编译你app对应的profile里保存的热代码,只编译这部分热代码。
全量编译机器码:art虚拟机为了提高性能,会对代码做全量机器码编译。这个过程会在ClassLoader加载类的时候发现传入进来的opt路径上不存在odex文件的时候就会自动触发。因为是第一次newclassloader之前没有做过编译也就没有odex文件所以就会做全量编译
解决方案演进
- 所以如果主进程启动直接做全量编译直接挂
- 如果在patch进行全量编译,由于dex2oat过程非常长在部分机型达到几分钟好的机型上也得等二三十秒而且非常占资源就有可能你的整个apt过程没做完来不及。比如用户总是点开新闻看几秒就杀掉导致你一直做不完优化,修复就一直用不上可能会拖慢主进程导致ARN
- tinker的方案:所以patch进程先进行轻量编译,如果做完了就用,做不完的话应用老的先让用户能用,并且避免全量编译(你都用的是老的了,就没必要做过多的全量编译了可能会导致占用资源过多业务进程也卡)。如果patch做轻量量编译可以用就用,不能用避免全量编译先让用户跑起来(如何避免全量编译稍后介绍)
轻量编译也有一定耗时,导致首次启动慢。而且你轻量编译之后你的独立进程也是无限制的在做全量编译可能抢资源导致主进程拖满然后ANR(概率较小tinker准备忽略,因为APP性能足够好)
- App在前台运行也有可能会导致patch进程抢占资源导致anr。所以在这个基础上面进一步优化:patch进程拉倒patch后先进行轻量编译,主进程优先用轻量编译后的patch。找合适的时机做全量编译(合适时机:我的APP退倒后台,其他APP在前台的时候/锁屏)系统做background dexopt也是系统不用的时候去做
避免全量编译
有三种方案:
- Atlas方案:在Native侧修改Art虚拟机的执行模式,直接用DexFile底层接口加载Dex文件(影响同进程下的dex加载并且DexFile在O版本以上被废弃)存在可用性和兼容问题
- Tbs方案:发现如果在new DexClassLoader的时候optDir传入为null的时候会置空oat_location就不会对你做全量编译(8.0上系统会忽略你传入的这个路径)
- Tinker方案:dexopt就是执行虚拟机的一个命令行,所以在你系统触发全量编译之前手动去调用dex2oat命令执行编译方式intercept-only只做清凉的编译。先用你轻量编译达到的结果首次启动或者首次安装完以后的运行效果和虚拟机一样的效果让他先跑起来也是出现问题之后的优化方案
Android N混合编译对热修复影响
混合编译:AOT,解释,JIT三种模式并存。
用户真正使用到的类可能只有很少部分,我们为什么要为了百分之二三十的代码去做全量编译呢?没有必要
N之前的Art虚拟机上安装是做的全量编译,所以安装的时候会等很久,做Jit及时编译又会很慢
在N上解决了这个问题通过混合编译缩短安装时间,系统OAT升级更快: 安装和首次启动用intervept-only的方式没有编译(和davlik虚拟机一样的效果),对哪些代码做编译,什么时候做编译呢:来看N上的增量编译过程:
Android N虚拟机增量编译过程
虚拟机会在APP代码运行过程中收集运行到的代码放到profile文件上,系统会通过jobSchedule启动BackgroundDexOptService。这个Service会在灭屏/充电的状态下启动。晚上睡觉或者其他手机空闲的情况时就会启动任务把收集到的代码给编译好(这些热代码是经常跑的所以会快)。后面启动的时候就会很块,通过这种方式给APP做增量的编译。编译完之后会生成base.odex和base。art(称之为App的image)
虚拟机认为这是热代码所以在你APP启动的时候就提前帮你吧这部分代码加载起来。在ClassLoader创建ClassLinker的时候一次性加载到dexcache上
所以就是你刚启动Application里面什么都还没做就已经加载了一些类(以前编译好的热代码)
Art混合编译对热修复的三种情况影响分析
- 要修复的类不在appimage中: Dex流派采用的是双亲委派预期的是通过parent去加载如果你要修复的类正好不在appimage里面也就是没有被提前加载那么这个机制就没错补丁可以生效
- 要修复的类有一部分在appimage中: 如果你有一部分在appimage里面。就导致一部分用的新的,一部分用的老的。这样访问就会出现地址错乱出现crash
- 要修复的类已经在appimage中:如果你全部都在appimage里面,你修复的这些正好之前都被收集了,那么你这个patch是不会生效的
解决方案
在N以上的设备抛弃设置parent的模式,做全量的直接替换吊我们的pathclassloader而不是设置他的parent
实现步骤
- 创建补丁dex的DexClassLoader
- 通过contextimpl拿到loadkedApk在拿到持有的PathClassLoader对象。就是系统帮我们创建的pathClassloader
- 通过反射替换这个属性为补丁的classloader
原理:因为系统的appimage提前加载是加载到系统的pathClassloader缓存上的。而我们后续运行的是用我们替换的classloader,所以这个新的classloader上没有了appimage的存在了
影响:由于没有了appimage的存在所以性能上会有牺牲但是是能达到修复的目的,统计下来影响是非常小的
本文为转载文章
原文链接:热修复Class流派和Dex流派实现原理 - 掘金 (juejin.cn)