手撕排序之堆排序
一、概念:
什么是逻辑结构、物理结构?
逻辑结构:是我们自己想象出来的,就像内存中不存在一个真正的树
物理结构(存储结构):实际上在内存中存储的形式。
堆的逻辑结构是一颗完全二叉树
堆的物理结构是一个数组
之前讲过二叉树可以用两种结构进行表示。
第一种就是链式结构,将一个一个结点进行链接。
第二种就是用数组表示。
数组表示意味着我们就是以数组为结构进行访问,但我们可以通过父子结点的下标关系将其看成树。
下面是孩子与结点的下标关系(需要记住!)
 、
、
思路:
我们将数组想象成一个完全二叉树——首先第一个表示树的根,接下来两个表示根的两个孩子,数组的下面4个表示树的两个孩子的下面一层,以此类推。最后一层不满,前面的都是连续的。
但是进行了上面的步骤后,还是不能将其称为堆。
堆分为两类:
- 大顶堆(大根堆):树中所有的父亲都大于等于孩子
- 小顶堆(小根堆):树中所有的父亲都小于等于孩子
一道经典例题(判断一串数字是否是堆)

解题方法:
将第一个数字看作二叉树的根,再往后取两个数字当作根的左右孩子,接着再取4个数,以此类推。直至还原成一个完全二叉树,接着看是不是属于堆的两种类型,如果既不是大顶堆,也不是小顶堆,那么这一串数字就不是堆。

堆的插入:
首先堆在逻辑结构上是一颗二叉树,但逻辑结构是我们自己想象出来的,本质上数据还是存储在数组中,所以我们应该对数组进行修改。
这里的插入我们选择尾插,尾插后有一下几种情况:
1、

直接尾插,不用改变任何顺序
2、

发现尾插顺序不满足大堆或者小堆,记住插入只影响自己的祖先,与其他的祖先没有关系!
所以我们只要改变孩子与祖先的关系,如何根据孩子找到父亲的下标呢?
parent = (child-1)/ 2 即可。
将这两个位置进行交换。
3、最坏的情况

最坏情况下可能会一直到根节点
因此每次交换完,都要进行孩子与父亲的比较。
时间复杂度:
我们看最坏的情况,执行次数就是树的高度次,也就是O(logN).
原码:
Swap(HeapDataType* a, HeapDataType* b)
{
HeapDataType tmp = *a;
*a = *b;
*b = tmp;
}
void AdujstUp(HeapDataType* a,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void HeapPush(HP* php,HeapDataType x)
{
assert(php);
//判断是否需要扩容
if (php->capcity == php->size)
{
int newCapcity = php->capcity == 0 ? 4 : php->capcity * 2;
//注意realloc的使用方法
HeapDataType* tmp = (HeapDataType*)realloc(php->a, sizeof(HeapDataType) * newCapcity);
if (tmp == NULL)
{
perror(realloc);
exit(-1);
}
php->a = tmp;
php->capcity = newCapcity;
}
php->a[php->size] = x;
php->size++;
//向上调整算法,跟祖先进行比较
AdujstUp(php->a, php->size-1);
}
堆的删除:
首先我们需要明确针对堆的删除,我们需要删除的是堆的根节点。
思路一(错误)
我们直接将数组的首元素删除,然后移动(memmove)后面的数据内容,但这样极大可能影响了大小堆的结构!
思路二:(向下调整算法)
我们直接将数组的首元素和数组的最后一个元素交换位置,然后size--,删除最后一个元素,也就是根节点。
这时候我们发现根节点的左右子树都是大堆/小堆
然后将根节点与左右节点的较小结点进行比较,如果还小,那么继续交换,直到叶节点为止
以此类推,堆顶的元素是最小的,继续pop,那么次小的元素又到堆顶……
原码:
void AjustDown(HeapDataType* a,int n,int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//确定最小孩子
if (child + 1 < n && a[child] < a[child + 1])//防止只有左叶子,访问右叶子会越界
child++;
if (a[parent] < a[child])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
void HeapPop(HP* php)
{
assert(php);
assert(php->size > 0);
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AjustDown(php->a,php->size,0);
}
小总结:(调整算法的前提)
向上调整算法的前提是:前面的数据内容都是大堆/小堆
向下调整算法的前提是:左右子树的数据内容都是大堆/小堆
TIP:
我们可以根据这个思路,可以实现一个排序算法,也就是堆排序。
时间复杂度:
跟插入一样,都是O(logN)。
堆排序:
1、建堆:
我们可以直接用向上寻找算法进行建堆。——为什么?
建堆有两种方式:
第一种就是向上建堆。
利用向上调整算法,每一个插入然后进行向上调整,完成建堆
时间复杂度:O(N) = N*logN
解析:

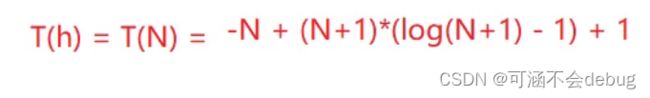
我们采取最差情况,得到O(h)的表达式,然后再用等式将h替换成n
总体的时间复杂度是O(N) = N*logN
第二种就是向下建堆。
从倒数第一个非叶子结点开始跳(也就是最后一个结点的父亲)
时间复杂度:O(N)
解析:
先假设h是树的高度,N是结点的个数
我们先用树的高度h作为自变量便于计算。最后再用等式进行替换。
考虑最坏的情况:
每层数据的个数 * 向下移动的层数
然后是等差*等比的数列求和,我们采用错位相减法计算。


最后的计算结果是2^h - 1- h.
因为2^h - 1 = n.
所以O(N) = N - log(N+1)
为什么向下调整算法要比向上调整复杂度低呢?
因为向下调整层数越低,向下调整的次数越多,所以是低*高
而向上调整层数越高,向上调整的次数就越多,所以是高*高,并且层数越高,占比越大,最后一层的结点个数就占了50%。
最后一层结点个数多并且向上调整的次数也多!
2、排序
如果我们排升序,建大堆。
排降序,建小堆。
原因:
建小堆有可能关系全乱了,剩下数据,看成新的完全二叉树,不一定是堆,重新建堆代价太大!
例子:
建大堆:
堆顶跟最后一个位置交换,最大的数据排好了,然后将最后一个元素不列入排序,剩下元素除了根节点其余是堆。剩下的数据由堆顶元素进行向下调整算法,选出次大的,代价是logN。
注意向上调整算法和向下调整算法的前提都是保证数据是堆!
以下是建小堆的堆排序算法
所以一共的时间复杂度O(N) = N*logN.
原码:
void HeapSort(int* a, int n)
{
//建堆
//建小堆/大堆
//向上调整建堆
//O(N*logN)
/*for (int i = 1; i < n; i++)
{
AdujstUp(a, i);
}*/
//向下调整建堆
//O(N),效率比向上调整高
for (int i = (n - 1 - 1) / 2; i >= 0; i--)//注意这里的n是数据个数,而公式中的n是下标
{
AjustDown(a, n, i);
}
//根节点的值要么最大,要么最小,可以进行排序
//这一部分的时间复杂度O(N) = N*logN
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AjustDown(a, end, 0);
end--;
}
}