PyTorch深度学习实战——基于ResNet模型实现猫狗分类
PyTorch深度学习实战——基于ResNet模型实现猫狗分类
-
- 0. 前言
- 1. ResNet 架构
- 2. 基于预训练 ResNet 模型实现猫狗分类
- 相关链接
0. 前言
从 VGG11 到 VGG19,不同之处仅在于网络层数,一般来说,神经网络越深,它的准确率就越高。但并非仅增加网络层数,就可以获得更准确的结果,随着网络层数的增加可能会出现以下问题:
- 梯度消失和爆炸:在网络层次过深的情况下,反向传播可能会面临梯度消失和爆炸的问题,导致训练网络时无法收敛
- 过拟合:增加网络深度会带来更多的参数,如果数据样本过少或网络过于复杂,会导致网络过拟合,降低模型的泛化能力
总之,在构建的神经网络过深时,有两个问题:前向传播中,网络的最后几层几乎没有学习到有关原始图像的任何信息;在反向传播中,由于梯度消失(梯度值几乎为零),靠近输入的前几层几乎没有任何梯度更新。
深度残差网络 (ResNet) 的提出就是为了解决上述问题。在 ResNet 中,如果模型没有什么要学习的,那么卷积层可以什么也不做,只是将上一层的输出传递给下一层。但是,如果模型需要学习其他一些特征,则卷积层将前一层的输出作为输入,并学习完成目标任务所需的其它特征。
1. ResNet 架构
ResNet 通过残差结构解决网络过深时出现的问题,让模型能够训练得更深。经典的 ResNet 架构如下所示:
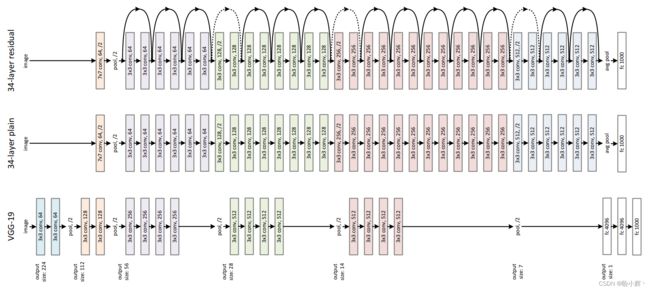
残差结构的基本思想是:每一个残差块都不是直接映射输入信号到输出信号,而是通过学习残差映射来实现:
F ( x ) = H ( x ) − x F(x)=H(x)−x F(x)=H(x)−x
其中, x x x 是输入, H ( x ) H(x) H(x) 是一个表示所需映射的基本块,而 F ( x ) F(x) F(x) 是残差块学习到的映射。换句话说,输入 x x x 通过卷积层,得到特征变换后的输出 F ( x ) F(x) F(x),与输入 x x x 进行逐元素的相加运算,得到最终输出 H ( x ) H(x) H(x):
H ( x ) = x + F ( x ) H(x) = x + F(x) H(x)=x+F(x)
如果某个基本块为恒等映射,则残差块的学习目标就变为学习 F ( x ) = 0 F(x)=0 F(x)=0,也就是让输入信号直接到达残差块的输出层。这样就可以解决梯度消失的问题,可以训练更深的神经网络。
实现过程中 ResNet 中使用 Shortcut Connection (也称跳跃连接, Skip Connection )在残差块中实现跨层连接,从而实现信息的直接传递,跨层连接可以绕过一个或多个卷积层,直接将网络中的浅层信息传递到深层中。
在 ResNet 的残差块中,Shortcut Connection 经常与卷积层或批归一化 (Batch Normalization) 相结合。通过该连接,残差块的激活张量可以直接和下一层的输出相加,理论上,即使是最后一层可能拥有原始图像的全部信息,并且反向传播过程中梯度将可以在几乎没有修改的情况下自由地流向浅层。典型的残差块如下所示:
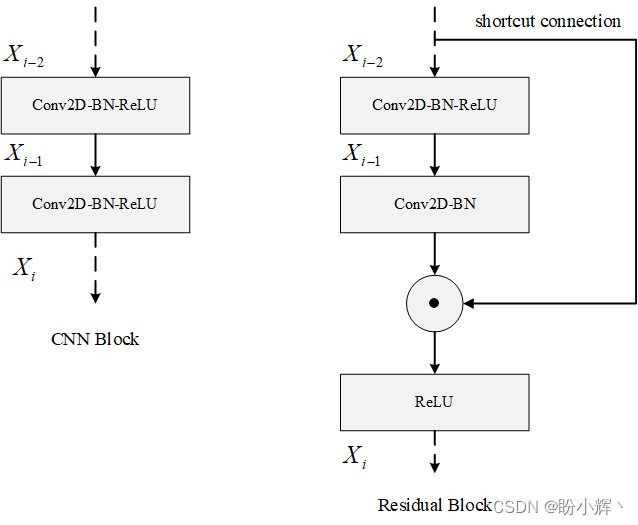
在传统中顺序堆叠的神经网络中,神经网络通常直接学习 F ( x ) F(x) F(x),其中 x 是来自前一层的输出值,而在残差网络中,利用跳跃连接,将残差信号 F ( x ) F(x) F(x) 加上恒等映射 x x x 得到最终的输出 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x。接下来,我们通过在 PyTorch 中构建残差块来深入了解残差网络。
2. 基于预训练 ResNet 模型实现猫狗分类
(1) 在 __init__ 方法中定义一个带有卷积操作的类:
from torch import nn
class ResLayer(nn.Module):
def __init__(self,ni,no,kernel_size,stride=1):
super(ResLayer, self).__init__()
padding = kernel_size - 2
self.conv = nn.Sequential(
nn.Conv2d(ni, no, kernel_size, stride,
padding=padding),
nn.ReLU()
)
在以上代码中,为了确保通过卷积后输出的尺寸保持不变,以便于将输入与卷结果相加,我们通过 padding 控制卷积时输出的尺寸。
(2) 定义 forward 方法:
def forward(self, x):
return self.conv(x) + x
在以上代码中,得到的输出是通过卷积操作的输入和原始输入之和。
在 PyTorch 中预训练的基于残差块的 ResNet18 架构如下:

该架构有 18 个可训练网络层,因此被称为 ResNet18 架构。此外,需要注意的是,ResNet18 并不是每个卷积层都会添加跳跃连接,而是在每两层之后使用跳跃连接。
了解了 ResNet 架构之后,构建一个基于预训练 ResNet18 架构的模型来执行狗猫分类任务。构建分类器的流程可以参考在迁移学习中使用预训练 VGG16 模型构建的猫狗分类器。
(3) 加载预训练 ResNet18 模型并检查模型中的模块:
model = models.resnet18(pretrained=True)
ResNet18 模型架构包含以下组件:
- 卷积层
- 批归一化
ReLU激活- 最大池化层
4个ResNet块- 平均池化 (
avgpool) 层 - 全连接层 (
fc) 层
冻结特征提取模块的网络权重,仅替换 avgpool 和 fc 层并更新其中的参数。
(4) 定义模型架构、损失函数和优化器:
def get_model():
model = models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.avgpool = nn.AdaptiveAvgPool2d(output_size=(1,1))
model.fc = nn.Sequential(nn.Flatten(),
nn.Linear(512, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 1),
nn.Sigmoid())
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-3)
return model.to(device), loss_fn, optimizer
在模型中,fc 模块的输入形状为 512,因为 avgpool 的输出形状为 batch size x 512 x 1 x 1。定义了模型后,训练模型,随着 epoch 的增加,模型训练和验证准确率的变化(对应模型分别为 ResNet18、ResNet34、ResNet50、ResNet101 和 ResNet152) 如下:

仅对 1000 张图像进行训练时,模型的准确率就可以达到 98% 左右,且准确率随着 ResNet 层数的增加而增加。
相关链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习