分布式事务Seata
目录
1.分布式事务问题
1.1.本地事务
1.2.分布式事务
2.理论基础
2.1.CAP定理
2.1.1.一致性
2.1.2.可用性
2.1.3.分区容错
2.1.4.矛盾
2.2.BASE理论
2.3.解决分布式事务的思路
3.初识Seata
3.1.Seata的架构
3.2.部署TC服务
windows部署seataServer
1.下载
2.解压
3.修改配置
docker部署seataServer
二.在nacos添加配置
三.启动TC服务
四、微服务集成seata
1.引入依赖
2.修改配置文件
3.3.微服务集成Seata
3.3.1.引入依赖
3.3.2.配置TC地址
3.3.3.其它服务
4.动手实践
4.1.XA模式
4.1.1.两阶段提交
4.1.2.Seata的XA模型
4.1.3.优缺点
4.1.4.实现XA模式
4.2.AT模式
4.2.1.Seata的AT模型
4.2.2.流程梳理
4.2.3.AT与XA的区别
4.2.4.脏写问题
4.2.5.优缺点
4.2.6.实现AT模式
4.3.TCC模式
4.3.1.流程分析
4.3.2.Seata的TCC模型
4.3.3.优缺点
4.4.SAGA模式
4.4.1.原理
4.4.2.优缺点
4.5.四种模式对比
1.分布式事务问题
1.1.本地事务
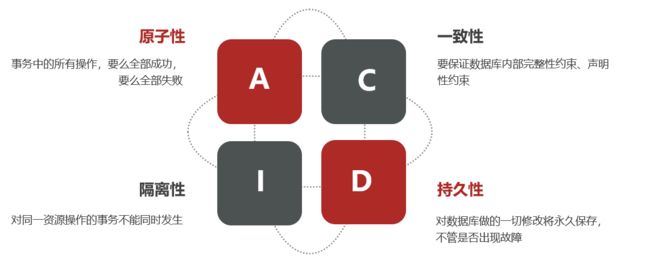
本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则:
1.2.分布式事务
分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
- 跨数据源的分布式事务
- 跨服务的分布式事务
- 综合情况
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为:
- 创建新订单
- 扣减商品库存
- 从用户账户余额扣除金额
完成上面的操作需要访问三个不同的微服务和三个不同的数据库。
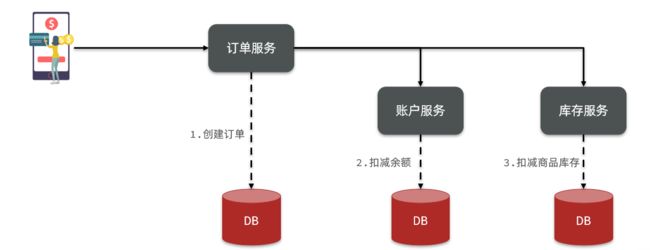
订单的创建、库存的扣减、账户扣款在每一个服务和数据库内是一个本地事务,可以保证ACID原则。
但是当我们把三件事情看做一个"业务",要满足保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务了。
此时ACID难以满足,这是分布式事务要解决的问题
2.理论基础
解决分布式事务问题,需要一些分布式系统的基础知识作为理论指导。
2.1.CAP定理
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)

它们的第一个字母分别是 C、A、P。
Eric Brewer 说,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
2.1.1.一致性
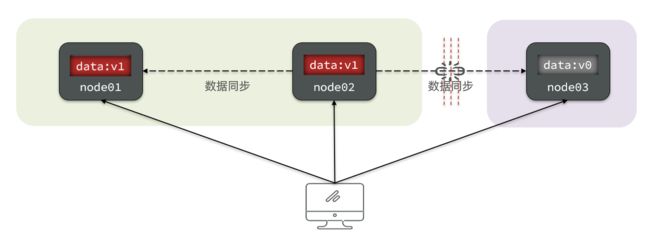
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
比如现在包含两个节点,其中的初始数据是一致的:
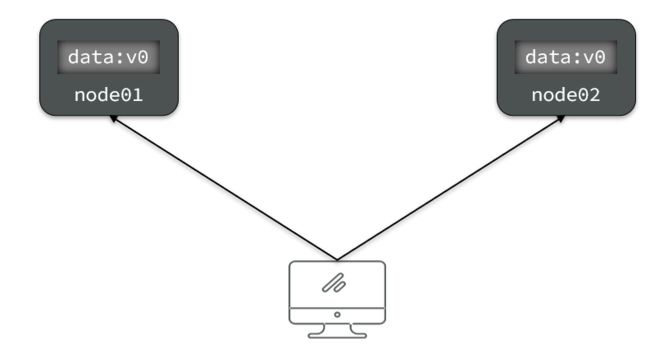
当我们修改其中一个节点的数据时,两者的数据产生了差异:
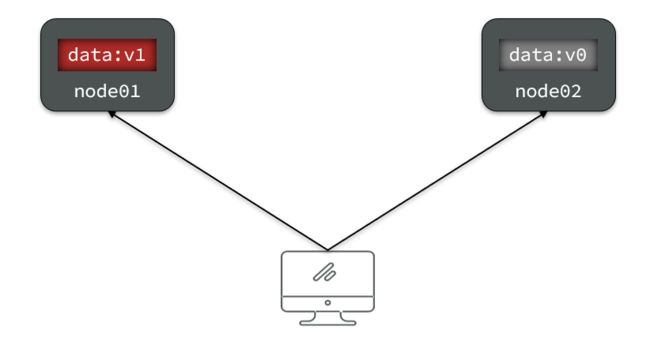
要想保住一致性,就必须实现node01 到 node02的数据 同步:
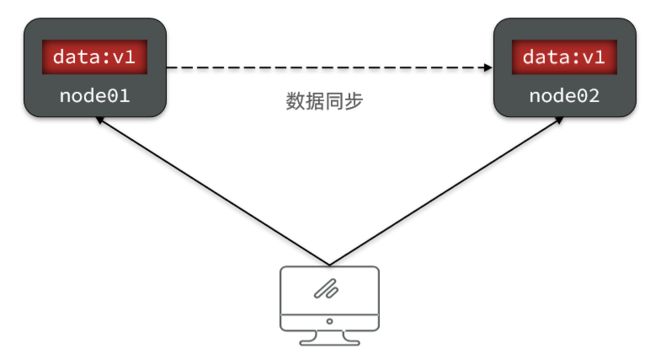
2.1.2.可用性
Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
如图,有三个节点的集群,访问任何一个都可以及时得到响应:

当有部分节点因为网络故障或其它原因无法访问时,代表节点不可用:
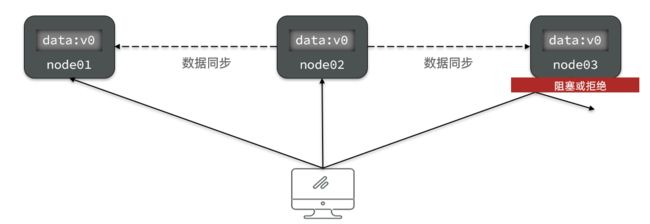
2.1.3.分区容错
Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
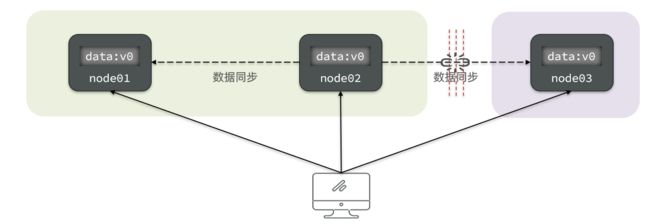
Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
2.1.4.矛盾
在分布式系统中,系统间的网络不能100%保证健康,一定会有故障的时候,而服务有必须对外保证服务。因此Partition Tolerance不可避免。
当节点接收到新的数据变更时,就会出现问题了:
如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用。
如果此时要保证可用性,就不能等待网络恢复,那node01、node02与node03之间就会出现数据不一致。
也就是说,在P一定会出现的情况下,A和C之间只能实现一个。
2.2.BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
2.3.解决分布式事务的思路
分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
但不管是哪一种模式,都需要在子系统事务之间互相通讯,协调事务状态,也就是需要一个事务协调者(TC):

这里的子系统事务,称为分支事务;有关联的各个分支事务在一起称为全局事务。
3.初识Seata
Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
官网地址:Seata | Seata,其中的文档、播客中提供了大量的使用说明、源码分析。
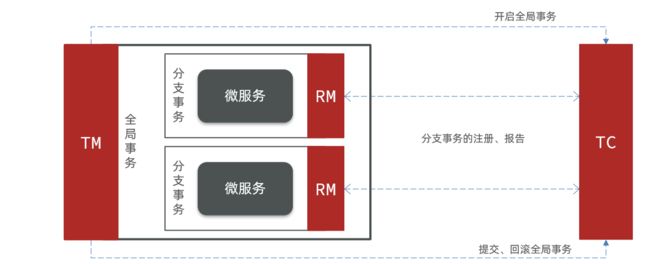
3.1.Seata的架构
Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) -事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) -事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) -资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
整体的架构如图:
Seata基于上述架构提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
无论哪种方案,都离不开TC,也就是事务的协调者。
3.2.部署TC服务
windows部署seataServer
1.下载
首先我们要下载seata-server包,地址在 下载中心
2.解压
在非中文目录解压缩这个zip包,其目录结构如下:

3.修改配置
修改conf目录下的registry.conf文件:

docker部署seataServer
创建并运行容器
docker run --name seata --restart=always -p 8091:8091 -e SEATA_IP=192.168.200.130 -e SEATA_PORT=8091 -v seata-config:/seata-server/resources -id seataio/seata-server:1.4.2
修改配置
# 进入挂载目录
cd /var/lib/docker/volumes/seata-config/_data
# 修改配置文件
vi registry.conf
:%d 清空文本内容内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义 spring.application.name
application = "seata-tc-server"
serverAddr = "192.168.200.130:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "SH"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "192.168.200.130:8848"
namespace = ""
group = "DEFAULT_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}二.在nacos添加配置
特别注意,为了让tc服务的集群可以共享配置,我们选择了nacos作为统一配置中心。因此服务端配置文件seataServer.properties文件需要在nacos中配好。
格式如下:
配置内容如下:
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://192.168.200.130:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=root
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898==其中的数据库地址、用户名、密码都需要修改成你自己的数据库信息。==
特别注意:tc服务在管理分布式事务时,需要记录事务相关数据到数据库中,你需要提前创建好这些表。
新建一个名为seata的数据库,运行sql文件:
CREATE DATABASE;
USE `seata`;
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`resource_group_id` varchar(32) DEFAULT NULL,
`resource_id` varchar(256) DEFAULT NULL,
`branch_type` varchar(8) DEFAULT NULL,
`status` tinyint(4) DEFAULT NULL,
`client_id` varchar(64) DEFAULT NULL,
`application_data` varchar(2000) DEFAULT NULL,
`gmt_create` datetime(6) DEFAULT NULL,
`gmt_modified` datetime(6) DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
KEY `idx_xid` (`xid`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) NOT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) DEFAULT NULL,
`transaction_service_group` varchar(32) DEFAULT NULL,
`transaction_name` varchar(128) DEFAULT NULL,
`timeout` int(11) DEFAULT NULL,
`begin_time` bigint(20) DEFAULT NULL,
`application_data` varchar(2000) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
KEY `idx_gmt_modified_status` (`gmt_modified`,`status`) USING BTREE,
KEY `idx_transaction_id` (`transaction_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) NOT NULL,
`xid` varchar(96) DEFAULT NULL,
`transaction_id` bigint(20) DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) DEFAULT NULL,
`table_name` varchar(32) DEFAULT NULL,
`pk` varchar(36) DEFAULT NULL,
`gmt_create` datetime DEFAULT NULL,
`gmt_modified` datetime DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
KEY `idx_branch_id` (`branch_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;这些表主要记录全局事务、分支事务、全局锁信息:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事务表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全局事务表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;三.启动TC服务
docker方式运行 重启容器即可
docker restart seata
进入bin目录,运行其中的seata-server.bat即可:
启动成功后,seata-server应该已经注册到nacos注册中心了。
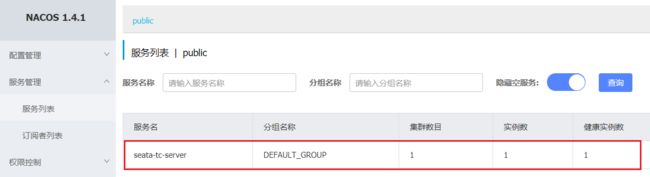
打开浏览器,访问nacos地址:http://localhost:8848,然后进入服务列表页面,可以看到seata-tc-server的信息:
四、微服务集成seata
1.引入依赖
首先,我们需要在微服务中引入seata依赖:
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
seata-spring-boot-starter
io.seata
io.seata
seata-spring-boot-starter
${seata.version}
2.修改配置文件
需要修改application.yml文件,添加一些配置:
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
# 参考tc服务自己的registry.conf中的配置
type: nacos
nacos: # tc
server-addr: 192.168.200.130:8848
namespace: ""
group: DEFAULT_GROUP
application: seata-tc-server # tc服务在nacos中的服务名称
tx-service-group: seata-demo # 事务组,根据这个获取tc服务的cluster名称
service:
vgroup-mapping: # 事务组与TC服务cluster的映射关系
seata-demo: SH3.3.微服务集成Seata
我们以order-service为例来演示。
3.3.1.引入依赖
首先,在order-service中引入依赖:
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
seata-spring-boot-starter
io.seata
io.seata
seata-spring-boot-starter
${seata.version}
3.3.2.配置TC地址
在order-service中的application.yml中,配置TC服务信息,通过注册中心nacos,结合服务名称获取TC地址:
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-tc-server # seata服务名称
username: nacos
password: nacos
tx-service-group: seata-demo # 事务组名称
service:
vgroup-mapping: # 事务组与cluster的映射关系
seata-demo: SH微服务如何根据这些配置寻找TC的地址呢?
我们知道注册到Nacos中的微服务,确定一个具体实例需要四个信息:
- namespace:命名空间
- group:分组
- application:服务名
- cluster:集群名
以上四个信息,在刚才的yaml文件中都能找到:

namespace为空,就是默认的public
结合起来,TC服务的信息就是:public@DEFAULT_GROUP@seata-tc-server@SH,这样就能确定TC服务集群了。然后就可以去Nacos拉取对应的实例信息了。
3.3.3.其它服务
其它两个微服务也都参考order-service的步骤来做,完全一样。
4.动手实践
下面我们就一起学习下Seata中的四种不同的事务模式。
4.1.XA模式
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
4.1.1.两阶段提交
XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:
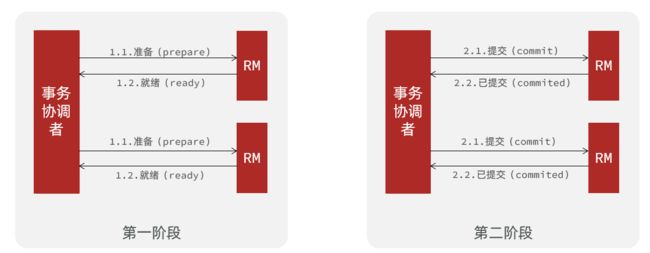
异常情况:

一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
-
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
4.1.2.Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:

RM一阶段的工作:
① 注册分支事务到TC
② 执行分支业务sql但不提交
③ 报告执行状态到TC
TC二阶段的工作:
- TC检测各分支事务执行状态a.如果都成功,通知所有RM提交事务b.如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
4.1.3.优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
4.1.4.实现XA模式
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
1)修改application.yml文件(每个参与事务的微服务),开启XA模式:
seata: data-source-proxy-mode: XA
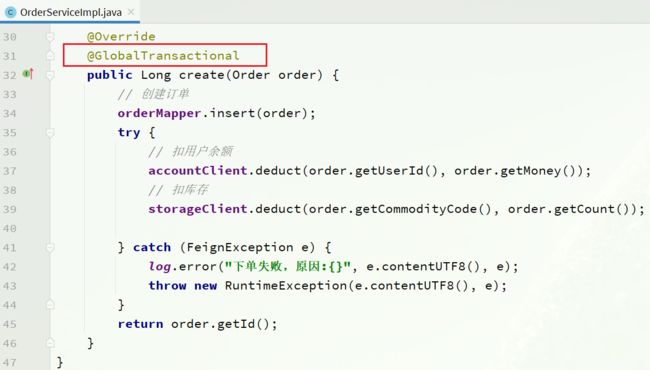
2)给发起全局事务的入口方法添加@GlobalTransactional注解:
本例中是OrderServiceImpl中的create方法.
3)重启服务并测试
重启order-service,再次测试,发现无论怎样,三个微服务都能成功回滚。
4.2.AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
4.2.1.Seata的AT模型
基本流程图:
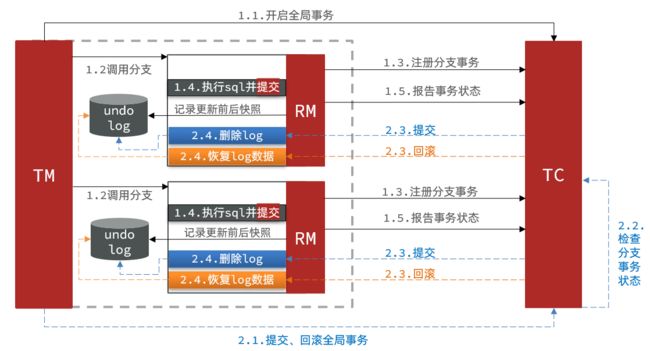
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
4.2.2.流程梳理
我们用一个真实的业务来梳理下AT模式的原理。
比如,现在又一个数据库表,记录用户余额:
| id |
money |
| 1 |
100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1AT模式下,当前分支事务执行流程如下:
一阶段:
1)TM发起并注册全局事务到TC
2)TM调用分支事务
3)分支事务准备执行业务SQL
4)RM拦截业务SQL,根据where条件查询原始数据,形成快照。
{
"id": 1, "money": 100
}5)RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
6)RM报告本地事务状态给TC
二阶段:
1)TM通知TC事务结束
2)TC检查分支事务状态
a)如果都成功,则立即删除快照
b)如果有分支事务失败,需要回滚。读取快照数据({"id": 1, "money": 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图:
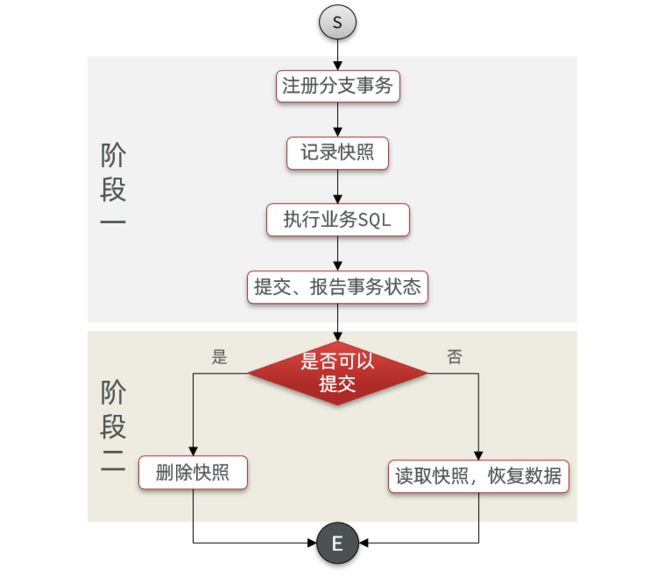
4.2.3.AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
4.2.4.脏写问题
在多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:

解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

4.2.5.优缺点
AT模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点:
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比XA模式要好很多
4.2.6.实现AT模式
AT模式中的快照生成、回滚等动作都是由框架自动完成,没有任何代码侵入,因此实现非常简单。
只不过,AT模式需要一个表来记录全局锁、另一张表来记录数据快照undo_log。
1)导入数据库表,记录全局锁
其中lock_table导入到TC服务关联的数据库,undo_log表导入到微服务关联的数据库:
CREATE DATABASE;
USE `db_account`;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) unsigned DEFAULT '0',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
insert into `account_tbl`(`id`,`user_id`,`money`) values (1,'user202103032042012',1000);
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) NOT NULL COMMENT 'global transaction id',
`context` varchar(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='AT transaction mode undo table';2)修改application.yml文件,将事务模式修改为AT模式即可:
seata:
data-source-proxy-mode: AT # 默认就是AT3)重启服务并测试
4.3.TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
- Try:资源的检测和预留;
- Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
- Cancel:预留资源释放,可以理解为try的反向操作。
4.3.1.流程分析
举例,一个扣减用户余额的业务。假设账户A原来余额是100,需要余额扣减30元。
- 阶段一( Try ):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30
初识余额:

余额充足,可以冻结:

此时,总金额 = 冻结金额 + 可用金额,数量依然是100不变。事务直接提交无需等待其它事务。
- 阶段二(Confirm):假如要提交(Confirm),则冻结金额扣减30
确认可以提交,不过之前可用金额已经扣减过了,这里只要清除冻结金额就好了:

此时,总金额 = 冻结金额 + 可用金额 = 0 + 70 = 70元
- 阶段二(Canncel):如果要回滚(Cancel),则冻结金额扣减30,可用余额增加30
需要回滚,那么就要释放冻结金额,恢复可用金额:

4.3.2.Seata的TCC模型
Seata中的TCC模型依然延续之前的事务架构,如图:

4.3.3.优缺点
TCC模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理
4.4.SAGA模式
Saga 模式是 Seata 即将开源的长事务解决方案,将由蚂蚁金服主要贡献。
其理论基础是Hector & Kenneth 在1987年发表的论文Sagas。
Seata官网对于Saga的指南:Seata Saga 模式
4.4.1.原理
在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
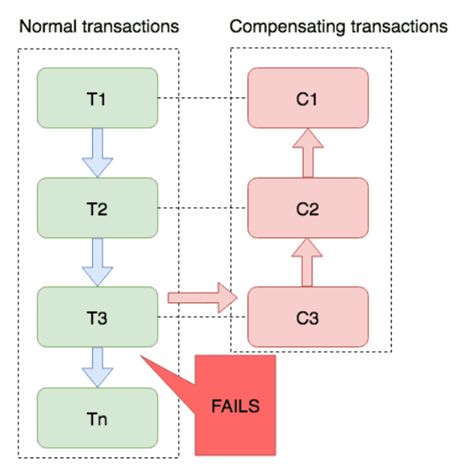
Saga也分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
4.4.2.优缺点
优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
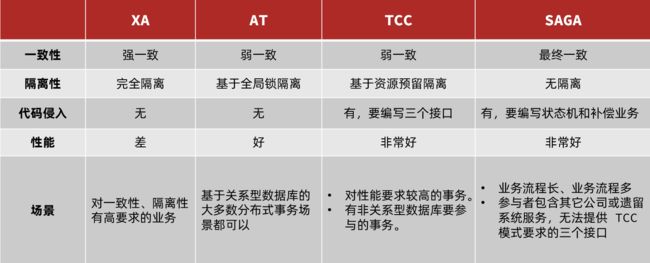
4.5.四种模式对比
我们从以下几个方面来对比四种实现:
- 一致性:能否保证事务的一致性?强一致还是最终一致?
- 隔离性:事务之间的隔离性如何?
- 代码侵入:是否需要对业务代码改造?
- 性能:有无性能损耗?
- 场景:常见的业务场景
如图: