python学习之【包和内置模块】
前言
接上篇文章 python学习之【模块】,这篇文章接着学习python中的包。
python中的包
包是一种用“点式模块名”构造Python模块命名空间的方法。在包中存放着一些功能相近的模块。
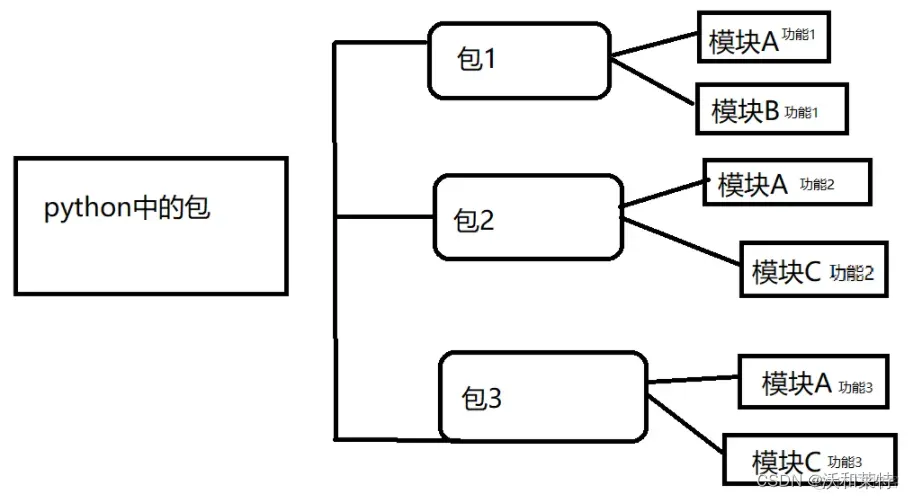
包的创建和导入
包的创建
我们可以在pytarm中创建一个package文件,当我们创建完成后会自动创建一个__init__.py文件,这时我们就完成了一个包文件的创建。
也就是这个__init__.py文件,可以让我们判断出哪些是python当中的包,目录中通常不含有__init__.py文件。
创建完成包文件以后,我们就可以在该文件目录下创建模块,当我们导入包的时候亦可导入包中所含的模块。
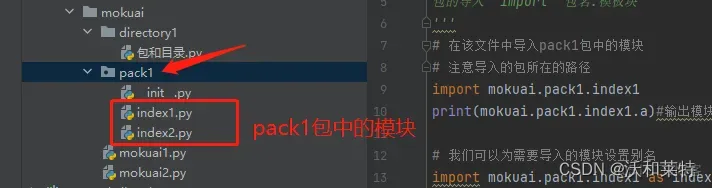
包的导入
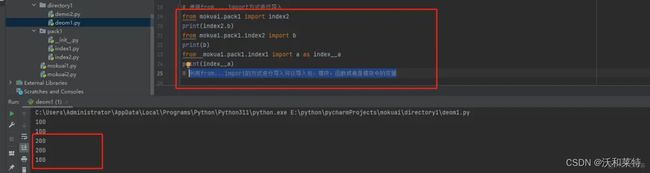
包的导入语法为:import 包名.模板块
假如我们在pack1包中的模块index1中写入a=100;在index2中写入b=200,然后在创建的目录
directory1中的文件demo1中进行包的导入:
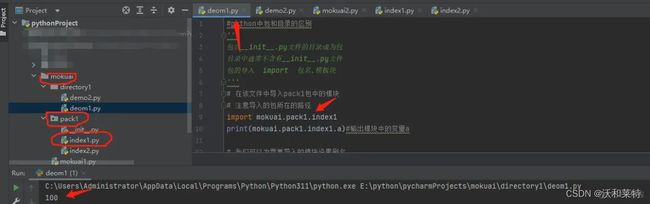
# 在该文件中导入pack1包中的模块
# 注意导入的包所在的路径
import mokuai.pack1.index1
print(mokuai.pack1.index1.a)#输出模块中的变量a
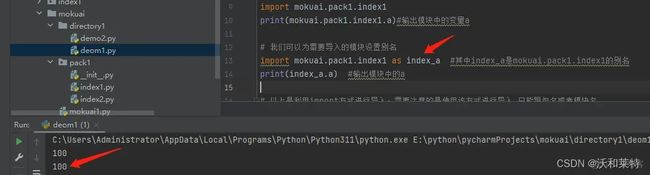
我们也可以为需要导入的模块进行别名:
需要注意的是利用import导入时,import后面只能跟包名或模块名;
当然我们也可以利用from...import的方式进行导入可以导入包,模块,函数或者是模块中的变量:
# 使用from....import方式进行导入
from mokuai.pack1 import index2
print(index2.b)
from mokuai.pack1.index2 import b
print(b)
from mokuai.pack1.index1 import a as index__a
print(index__a)
python中的内置模块
上篇文章中我们提到了python中的一部分内置函数,这里简单的运用下这些内置模块:

os模块
#os模块
import os
# 获取当前工作目录,也就是当前python脚本工作的目录路径
print(os.getcwd())
# 改变当前脚本工作目录,相当于shell下的cd
# print(os.chdir("dirname"))
# 返回当前目录
print(os.curdir)
# 返回当前目录的父目录字符串名
print(os.pardir)
# 生成多层递归目录
os.makedirs('dir1/dir2')
# 若指定目录为空,则删除并递归到上一级目录;如果也为空也进行删除,以此类推
os.removedirs('dirname')
# 创建一个新目录
os.mkdir('dirname')
# 删除空目录,若指定目录不为空就报错
os.rmdir('dirname')
# 删除一个文件
os.remove()
# 列举出指定目录下的所有文件和子目录,包括隐藏文件,并以列表的方式打印
print(os.listdir('dirname'))
# 遍历所有目录,包括子目录
os.walk('dirname')
# 重命名文件/目录
os.rename('old','new')
# 获取文件/目录信息
os.stat('path/filename')
![]()
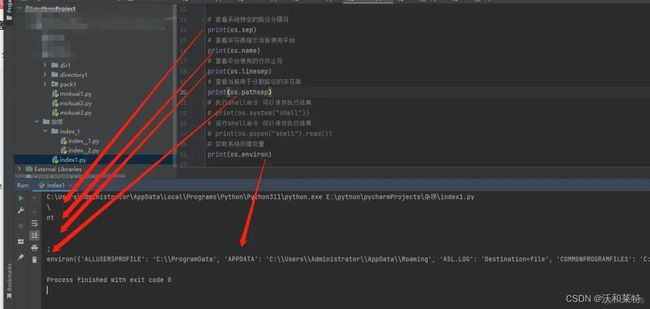
# 查看系统特定的路径分隔符
print(os.sep)
# 查看字符串指示当前使用平台
print(os.name)
# 查看平台使用的行终止符
print(os.linesep)
# 查看当前用于分割路径的字符串
print(os.pathsep)
# 执行shell命令 可以保存执行结果
print(os.system("shell"))
# 运行shell命令 可以保存执行结果
print(os.popen("shell").read())
# 获取系统环境变量
print(os.environ)
# 返回path规范化的绝对路径
print(os.path.abspath('filename/dirname'))
# 将path分割成目录和文件名按照元组返回
print(os.path.split("filename"))
# 返回path的目录,即os.path.split(path)的第一个元素
print(os.path.dirname("dirname"))
# 返回path最后的文件名,若path以/或者是\结尾会返回空值
print(os.path.basename("filename"))
# 如果path存在就返回True,如果path不存在就返回False
print(os.path.exists(''))
# 如果path是绝对路径,就返回True
print(os.path.isabs(""))
# 如果path是一个存在的文件就返回True,否则返回False
print(os.path.isdir("filename"))
# 如果path是一个存在的目录,就返回True,否则就返回False
print(os.path.isdir('dirname'))
# 将多个路径组合后返回,第一个路径之前的参数将会被忽略
print(os.path.join(''))
# 返回path所指向的文件或者是目录的最后存取时间
print(os.path.getatime('filename'))
# 返回path所指向的文件或者目录的最后修改时间
print(os.path.getmtime('filename'))
sys模块
python中的sys模块提供给访问解释器使用或维护的变量,和与解释器进行交互的函数。sys模块负责与python解释器的交互,提供了一系列的函数的和变量,用于操控python运行时的环境,sys模块也是python中默认的集成模块,被集成在解释器中。
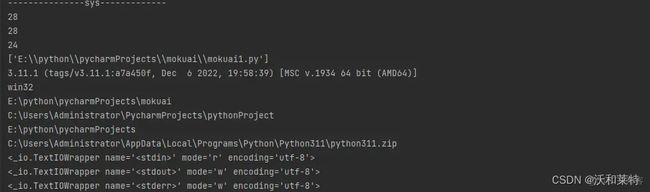
import sys
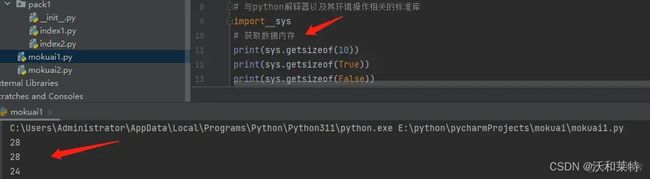
# 获取数据内存
print(sys.getsizeof(10))
print(sys.getsizeof(True))
print(sys.getsizeof(False))
# 获取命令行参数列表,第一个参数时程序本身的路径
print(sys.argv)
# 退出程序,正常退出时exit(0)
# print(sys.exit(0))
# 获取python解释器程序的版本信息
print(sys.version)
# 返回模块的搜索路径,初始化时使用python path环境变量的值
print(sys.platform)
# 遍历当前python文件的路径
print(sys.path[0])
print(sys.path[1])
print(sys.path[2])
print(sys.path[3])
# 输入相关
print(sys.stdin)
# 输出相关
print(sys.stdout)
# 错误相关
print(sys.stderr)
使用sys模块中的标准输出实现进度条:
print('-----------进度条------------')
# 使用标准输入和输出实现动态进度条
import sys
import time
def view_bar(num1,num2):
rate=num1/num2
rate_num=int(rate*100)
r='\r%s%d%%' % (">"*num1,rate_num)
sys.stdout.write(r)
sys.stdout.flush()
if __name__=='__main__':
for i in range(0,101):
time.sleep(0.1)
view_bar(i,100)
![]()
time模块
# time 提供与时间相关的各种函数
import time
print(time.time()) #输出当前的秒数
print(time.localtime(time.time())) #将输出的秒数转换为当前具体的时间
![]()
比如当我们利用os模块中的getmtime()函数返回修改某个文件过目录的时间时,我们就可以将返回的秒数格式化成年-月-日 时:分:秒的形式:
# 格式化时间
import time
seconds=os.path.getmtime('index_1')
timeArray=time.localtime(seconds)
Styletime=time.strftime("%y-%m-%d %H:%M:%S",timeArray)
print(Styletime)
# 23-02-25 18:55:06
我们也可以安装第三方模块,比如:可以安装第三方模块schedule,导入time模块,实现定时输出功能:
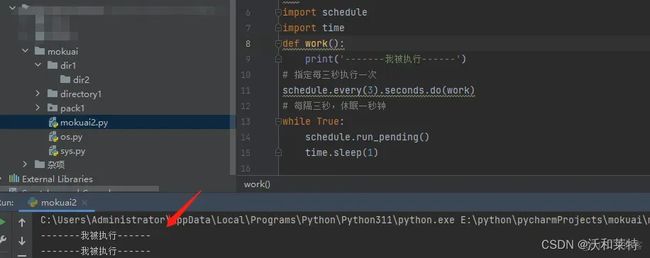
#安装第三方模块schedule,导入time模块,实现定时输出功能
import schedule
import time
def work():
print('-------我被执行------')
# 指定每三秒执行一次
schedule.every(3).seconds.do(work)
# 每隔三秒,休眠一秒钟
while True:
schedule.run_pending()
time.sleep(1)
random模块
random模块实现了一个伪随机数生成器,可以用来生成随机数以完成与随机数相关的功能。
import random
# 生成一个1——100的随机整数,包括1和100
print(random.randint(1,100))
# 55
# seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。
random.seed(10)
print('使用整数10种子生成随机数',random.random())
# 使用整数10种子生成随机数 0.5714025946899135
# 随机打乱列表元素排列
lis1=[1,2,3,4,5,6,7]
random.shuffle(lis1)
print(lis1)
# [3, 2, 6, 1, 5, 7, 4]
# 生成1--100之间的浮点数
print(random.uniform(1,100))
# 81.51880388437468
# 生成1——100之间的整数但是不包括10
print(random.randrange(1,100))
# 36
# 通过使用random.randint()函数,随机生成整数,字符,大小写等.
print(random.randint(1,100))
print(chr(random.randint(65,90))) #随机生成A——Z
print(chr(random.randint(48,57)))#随机生成0-9
print(chr(random.randint(97,122)))#随机生成a-z
# 从列表中随机弹出一个数据
string=['hello','world','你好世界']
print(random.choice(string))
# 你好世界
利用random模块生成验证码;
# 使用random函数生成验证码
lis2=[]
for i in range(5):
j = random.randint(0,5)
if j ==2 or i==4:
num=random.randrange(0,5)
lis2.append(str(num))
else:
temp=random.randrange(65,90)
num2=chr(temp)
lis2.append(num2)
result=''.join(lis2)
print(result)
#KHLN4
urllib包
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
注意,urllib是一个包,当我们导入这个包时系统会自动创建一个__init__.py的python文件,urllib这个包中含有__init__.py文件,并且包含一些内置模块。
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。我们引入urllib包中的request模块中的urlopen方法,可以让它返回所查询到的数据,它的语法为:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url:url 地址。 data:发送到服务器的其他数据对象,默认为 None。 timeout:设置访问超时时间。
cafile 和capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
cadefault:已经被弃用。 context:ssl.SSLContext类型,用来指定 SSL 设置。
如下,我们利用这个方法去读取百度服务器的返回数据:
read() 是读取整个网页内容,我们可以指定读取的长度:
# urllib 用于读取来自网上(服务器)的数据标准库
import urllib.request
print(urllib.request.urlopen('http://www.baidu.com').read(500))
我们使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。

除此之外,我们还可以使用:
readline() - 读取文件的一行内容
readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
当我们在对网页进行抓取时,经常需要判断网页是否可以正常访问,这时就可以使用 getcode() 函数获取网页状态码,返回 200 说明网页正常,返回 404 说明网页不存在:
import urllib.request
myURL1 = urllib.request.urlopen("https://www.baidu.com/")
print(myURL1.getcode()) # 200
try:
myURL2 = urllib.request.urlopen("https://www.baidu.com/no.html")
except urllib.error.HTTPError as e:
if e.code == 404:
print(404) # 404
每篇一语
最值得欣赏的风景,事自己前进的足迹!
如有不足,感谢指正!