xpath定位(全)
xpath定位(全)
- 简介
- XPATH在浏览器中的验证方式
- 1. 绝对定位:
- 2. 相对路径:
- 3. 标签属性定位:
- 4. 节点文本定位
- 5. XPath Axes(轴)和Step(步)
- 6. 函数
- 7. 数值比较
xpath是一种在xm文档中定位的语言,详细简介,请自行参照百度百科,本文主要总结一下xpath的使用方法,个人看法,如有不足和错误,敬请指出。
注意:xpath的定位 同一级别的多个标签 索引从1开始 而不是0
简介
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

示例

谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。

选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

示例

XPATH在浏览器中的验证方式
- 以百度首页定位为例,首先打开浏览器访问百度,按F12打开调试工具界面
- 定位到Element标签
- 按Ctrl+F打开搜索输入栏
- 输入xpath进行定位试验

1. 绝对定位:
此方法最为简单,具体格式为
xxx.find_element_by_xpath("绝对路径")
具体例子:
xxx.find_element_by_xpath("/html/body/div[x]/form/input")
x 代表第x个 div标签,注意,索引从1开始而不是0
此方法缺点显而易见,当页面元素位置发生改变时,都需要修改,因此,并不推荐使用。
2. 相对路径:
相对路径,以‘//'开头,具体格式为
xxx.find_element_by_xpath("//标签")
具体例子:
xxx.find_element_by_xpath("//input[x]")
定位第x个input标签,[x]可以省略,默认为第一个
相对路径的长度和开始位置并不受限制,也可以采取以下方法, [x]依然是可以省略的
xxx.find_element_by_xpath("//div[x]/form[x]/input[x]")
3. 标签属性定位:
3.1标签属性定位,相对比较简单,也要求属性能够定位到唯一一个元素,如果存在多个相同条件的标签,默认只是第一个,具体格式
xxx.find_element_by_xpath("//标签[@属性='属性值']")
属性判断条件:最常见为id,name,class等等,目前属性的类别没有特殊限制,只要能够唯一标识一个元素都是可以的
具体例子
xxx.find_element_by_xpath("//a[@href='/industryMall/hall/industryIndex.html']")
xxx.find_element_by_xpath("//input[@value='确定']")
xxx.find_element_by_xpath("//div[@class = 'submit']/input")
当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,具体例子
xxx..find_element_by_xpath("//input[@type='name' and @name='kw1']")
3.2 当标签属性很少,不足以唯一区别元素时,但是标签中间中间存在唯一的文本值,也可以定位,其具体格式
xxx.find_element_by_xpath("//标签[contains(text(),'文本值')]")
具体例子:
xxx.find_element_by_xpath("//iunpt[contains(text(),'型号:')]")
注意:尽量在html中复制此段文本,避免因为肉眼无法分辨的字符导致定位失败
3.3 其他的属性值如果太长,也可以采取模糊方法定位,直接上示例

xxx.find_element_by_xpath(“//a[contains(@href, ‘logout')]”)
3.4 XPath 关于网页中的动态属性的定位,例如,ASP.NET应用程序中动态生成id属性值,可以有以下四种方法:
- starts-with例子: //input[starts-with(@id,'ctrl')] 解析:匹配以ctrl开始的属性值
- ends-with 例子://input[ends-with(@id,'userName')] 解析:匹配以userName结尾的属性值
- contains() 例子://input[contains(@id,'userName')] 解析:匹配含有userName属性值
当然,如果上面的单一方法不能完成定位,也可以采取组合式定位 类似
("//input[@id='kw1']//input[start-with(@id,'nice']/div[1]/form[3])
3.5 .//和//的区别
//是指从全文上下文中搜索//后面的节点,而.//则是指从前面的节点的子节点中进行查找
3.6 选取若干路径|
这个符号用于在一个xpath中写多个表达式用,用|分开,每个表达式互不干扰,意思是一个xpath可以匹配多个不同条件的元素,例如如下xpath可以匹配到满足条件的i标签元素和满足条件的span标签元素
//i[@class='c-icon'] | //span[@class='hot-refresh-text']

4. 节点文本定位
4.1 text()与string()帮助定位
上面3.4小节的三个示例都是用的属性,所以@是对属性取值,接下来介绍的text()与string()是对显示的文字取值

//*[@id="hotsearch-content-wrapper"]/li/a/span[contains(text(),"孙兴")]
针对最小节点同样可以使用string()
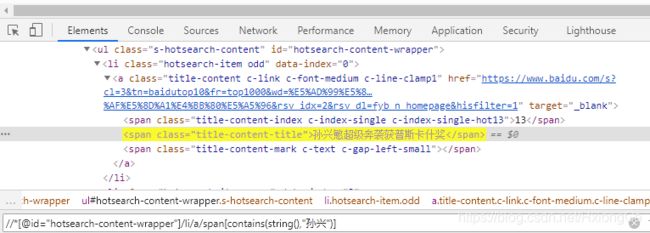
请看下面的区别,多层节点时区别就显示出来了


多层节点时的解释,
- string()是获取当前节点下所有的子节点文本,并组合成一个字符串;
- text()是获取当前节点下所有的子节点文本,并组合成一个字符串列表;
由于3.4节里的三个方法都是针对字符串,所以text()不能用于多层节点,此时可以使用string()
4.2 XPATH之normalize-space()
主要用法有二种:normalize-space(.)、normalize-space(text())
- . 是当前节点.如果您在需要字符串的地方使用它(即作为normalize-space()的参数),引擎会自动将节点转换为节点的字符串值,对于元素,该元素是连接元素中的所有文本节点
- text() 仅选择作为当前节点的直接子节点的文本节点
例如,给定XML:
<a>Foo
<b>Barb>
lish
a>
并假设< a>是你的当前节点,normalize-space(.)将返回Foo Bar lish,但normalize-space(text())将失败,因为text()返回两个文本节点(Foo和lish)的节点集,这是规范化空间()不接受。
简而言之,如果要对元素中的所有文本进行规范化,请使用“.”,如果要选择特定的文本节点,请使用text(),但始终记住,尽管名称如此,text()将返回nodeset,只有具有单个元素时才会自动转换为字符串。
5. XPath Axes(轴)和Step(步)
以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看xpath中支持的方法:
Axes(轴)
-
child 选取当前节点的所有子元素
-
parent 选取当前节点的父节点
-
descendant选取当前节点的所有后代元素(子、孙等)
-
ancestor 选取当前节点的所有先辈(父、祖父等)
-
descendant-or-self选取当前节点的所有后代元素(子、孙等)以及当前节点本身
-
ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
-
preceding-sibling选取当前节点之前的所有同级节点
-
following-sibling选取当前节点之后的所有同级节点
-
preceding选取文档中当前节点的开始标签之前的所有节点
-
following选取文档中当前节点的结束标签之后的所有节点
-
self 选取当前节点
-
attribute 选取当前节点的所有属性
-
namespace选取当前节点的所有命名空间节点
步(step)
包括:
- 轴(axis)
定义所选节点与当前节点之间的树关系 - 节点测试(node-test)
识别某个轴内部的节点 - 零个或者更多谓语(predicate)
更深入地提炼所选的节点集
步的语法:
轴名称::节点测试[谓语]
步 实例

实践
- descendant表示取当前节点的所有后代元素
定位百度首页的“百度一下”按钮

可以看到, 标签的父元素是标签,而标签的父元素是标签,所以可以通过先定位标签,然后利用descendant定位标签
xpath路径如下:
xpath= "//form[@id='form']/descendant::input[@id='su']"
//form[@id='form']表示找到id属性为'form'的<form>标签,
descendant::input表示找到<form>标签的所有后代<input>标签,
然后通过[@id='su']精准定位到id属性为'su'的<input>标签
把路径放到浏览器控制台,按下Ctrl+F,然后输入xpath路径,查看一下,确实定位到了标签(在执行程序之前,可以通过这种方式来验证一下写的xpath路径是否正确)

- following表示选取当前节点结束标签之后的所有节点
注意这里说的是“结束标签之后”,所以在用这个轴进行定位时要看清目标标签的与辅助定位标签的层级关系,所以上例中就不能通过标签结合following来定位,因为标签在标签里面;
分析一下:标签的上级是一个标签,这个标签上面也有一个标签,可以通过它来定位
xpath= "//span[@id='s_kw_wrap']/following::input[@id='su']"
//span[@id='s_kw_wrap']表示定位到id属性为s_kw_wrap的<span>标签,
/following::input[@id='su']表示找到<span>结束标签(即</span>)后的所有input标签,
然后通过[@id='su']精准定位到id属性为'su'的<input>标签

- parent可指定要查找的当前节点的直接父节点
例如,父节点是个div,即可写成parent::div,如果要找的元素不是直接父元素,则不可使用parent,可使用ancestor,代表父辈、祖父辈等节点,child::表示直接子节点元素,following-sibling只会标识出当前节点结束标签之后的兄弟节点,而不包含其他子节点;
以https://www.guru99.com/这个网站为例,
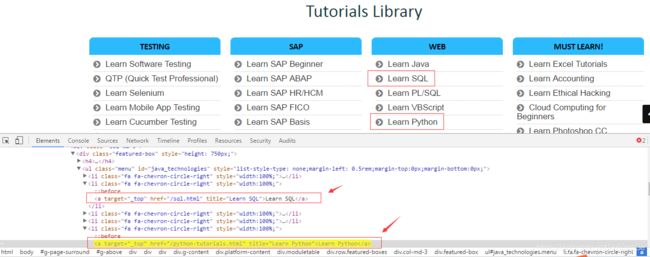
定位Learn Python,思路如下:先定位Learn SQL,然后找到Learn SQL的父节点li,然后再找li的兄弟节点,即包含Learn Python的那个li标签,然后再找li的孩子节点,也就是a标签
//a[text()='Learn SQL']/parent::li/following-sibling::li/child::a[text()='Learn Python']
也可以这样写
//a[text()='Learn SQL']/parent::li/following-sibling::li[3]/a
6. 函数
- count:统计
'count(//li[@data])' #节点统计
- concat:字符串连接
'concat(//li[@data="one"]/text(),//li[@data="three"]/text())'
- local-name:解析节点名称
'local-name(//*[@id="testid"])' #local-name解析节点名称,标签名称
- contains(string1,string2):如果 string1 包含 string2,则返回 true,否则返回 false
'//h3[contains(text(),"H3")]/a/text()')[0] #使用字符内容来辅助定位
- not:布尔值(否)
'count(//li[not(@data)])' #不包含data属性的li标签统计
- string-length:返回指定字符串的长度
#string-length函数+local-name函数定位节点名长度小于2的元素
'//*[string-length(local-name())<2]/text()')[0]
组合拳2
#contains函数+local-name函数定位节点名包含di的元素
'//div[@id="testid"]/following::div[contains(local-name(),"di")]'
- or:多条件匹配
'//li[@data="one" or @code="84"]/text()' #or匹配多个条件
#也可使用|
'//li[@data="one"]/text() | //li[@code="84"]/text()' #|匹配多个条件
- 组合拳3:floor + div除法 + ceiling
#position定位+last+div除法,选取中间两个
'//div[@id="go"]/ul/li[position()=floor(last() div 2+0.5) or position()=ceiling(last() div 2+0.5)]/text()'
- 组合拳4隔行定位:position+mod取余
#position+取余运算隔行定位
'//div[@id="go"]/ul/li[position()=((position() mod 2)=0)]/text()')
7. 数值比较
- <:小于 、 >:大于
#所有li的code属性小于200的节点
'//li[@code<200]/text()'
- div:对某两个节点的属性值做除法
'//div[@id="testid"]/ul/li[3]/@code div //div[@id="testid"]/ul/li[1]/@code'
- 组合拳4:根据节点下的某一节点数量定位
#选取所有ul下li节点数大于5的ul节点
'//ul[count(li)>5]/li/text()'