学习Node js:raw-body模块源码解析
raw-body是什么
raw-body的主要功能是处理HTTP请求体的原始数据。它提供了以下核心功能:
- 解析请求体:可以从HTTP请求中提取原始数据,包括文本和二进制数据。
- 配置选项:通过配置项,可以设置请求体的大小限制、编码方式等参数。
- 异常处理:模块能够处理异常情况,如请求体超出限制。
- 编码转换:支持将原始数据解码为指定编码的字符串,或者返回
Buffer实例。
express中的body-parser中间件就使用了raw-body来处理请求
raw-body基础用法
安装:
npm install raw-body
引入:
var getRawBody = require('raw-body')
getRawBody函数签名如下:
getRawBody(stream, [options], [callback])
stream是需要解析的流。
options是一些配置项。
length- 流的长度。limit- 请求体的大小限制。比如1000、'500kb'或'3mb'。encoding- 用于将请求体解码为字符串的编码。默认情况下,如果未指定编码,将返回Buffer实例。最有可能的是,您需要utf-8,因此将encoding设置为true将解码为utf-8
callback是解析完成之后的回调函数。
结合express一起使用的例子如下:
var contentType = require('content-type')
var express = require('express')
var getRawBody = require('raw-body')
var app = express()
app.use(function (req, res, next) {
getRawBody(req, {
length: req.headers['content-length'],
limit: '1mb',
encoding: contentType.parse(req).parameters.charset
}, function (err, string) {
if (err) return next(err)
req.text = string
next()
})
})
// 可以在后续的express中间件中访问 req.text
也可以使用promise风格调用getRawBody:
var getRawBody = require('raw-body')
var http = require('http')
var server = http.createServer(function (req, res) {
getRawBody(req)
.then(function (buf) {
res.statusCode = 200
res.end(buf.length + ' bytes submitted')
})
.catch(function (err) {
res.statusCode = 500
res.end(err.message)
})
})
server.listen(3000)
raw-body v0.0.3源码阅读
我们选择的版本是v0.0.3,选择这个版本的原因非常简单:代码量非常少,只有70行
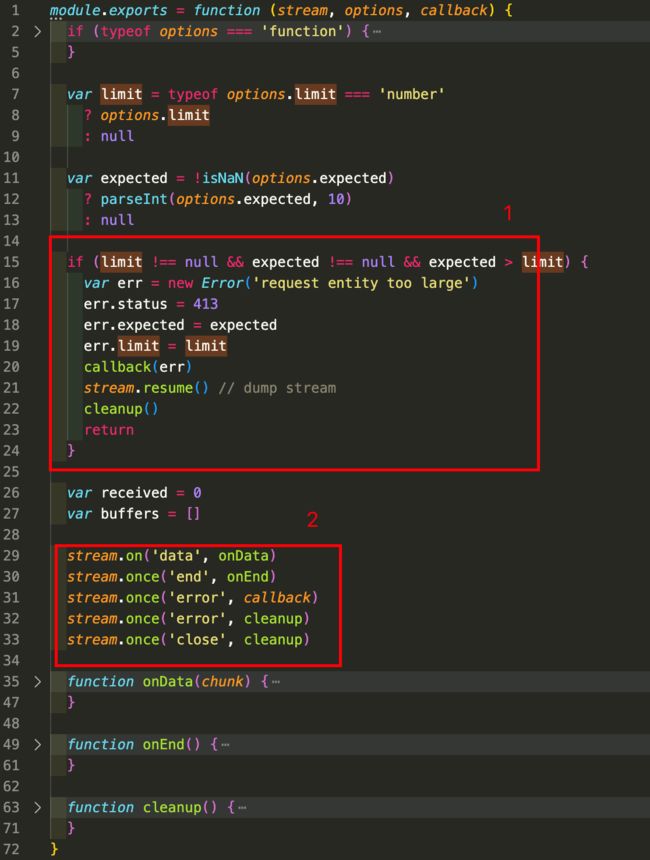
- 主要作用是处理一些异常,当请求体内容超过限制时会调用
stream.resume这个方法销毁这个stream,防止请求数据被缓冲。 - 监听
stream的一些事件,然后使用回调进行处理,stream之所以能调用on、once、removeListener等方法,是因为stream继承了Nodejs中的EventEmitter模块。- data事件:每当可读流接收到新的数据块时,就会触发
data事件。一般用于逐块处理请求体数据。 - end事件:
end事件在可读流读取完数据后触发,表示数据流结束。 - error事件:当可读流发生错误时触发
error事件。 - close事件:
close事件在可读流关闭时触发,表示流已经被关闭,用于在流关闭时进行一些资源清理或收尾工作
- data事件:每当可读流接收到新的数据块时,就会触发
onData
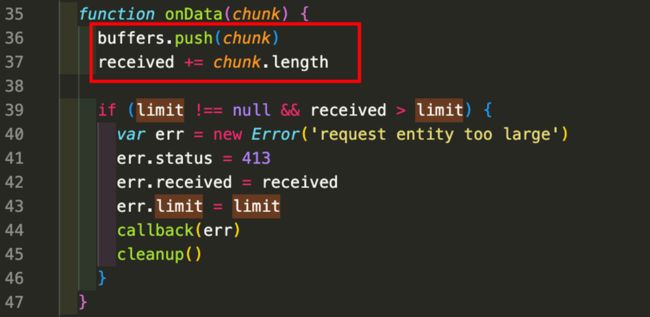
onData的核心代码只有这两行:
吧收到的chunk 放到buffers数组里面,chunk的数据类型默认是Buffer类型
然后使用 chunk.length 返回当前chunk的字节数,并累加起来
onEnd
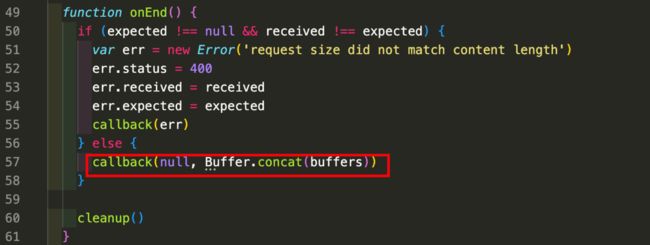
onEnd的核心是57行:调用传入的回调函数,并吧Buffer.concat的结果传入
Buffer.concat方法会吧 buffers 中的所有 Buffer 实例连接在一起,返回一个新的 Buffer
cleanup
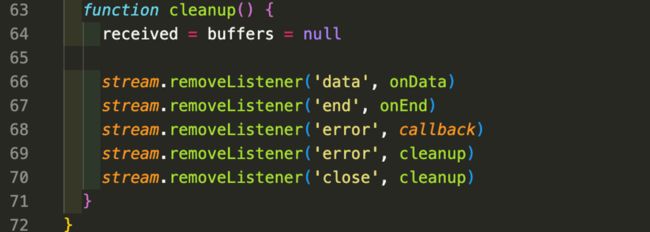
cleanup中的主要逻辑就是调用removeListener对请求数据流的事件监听器进行清理,可以防止内存泄漏以及不必要的资源占用。
v0.0.3版本的代码看完之后我们再看看看v2.5.2的
raw-body v2.5.2源码阅读
2.5.2版本的代码有300多行,是0.0.3版本的四倍,不过核心功能是差不多的,差异点如下:
options配置项新增了encoding参数:用于吧body解码成指定编码的字符串,默认情况下,如果没有指定编码,将返回一个Buffer实例,stream增加了aborted事件的处理:stream.on('aborted', onAborted)
raw-body依赖的模块
2.5.2版本依赖了5个npm模块
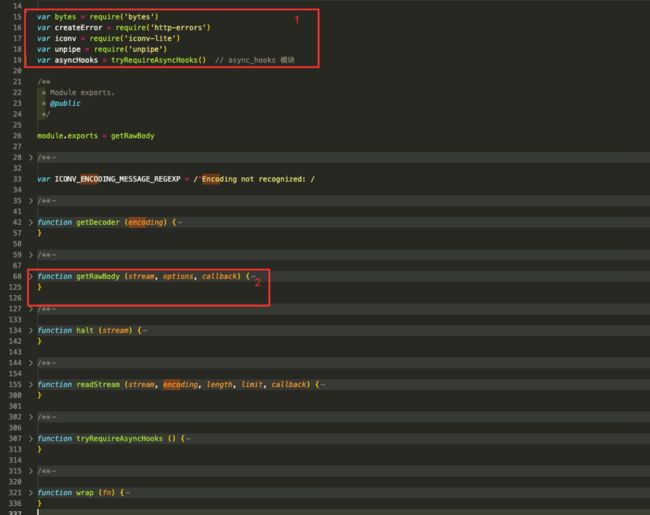
先看一下这些模块的功能:
bytes是一个用于在不同单位之间进行字节转换的Nodejs模块。常用方法如下:
bytes.parse('1KB');// output: 1024
bytes.format(1024);// output: '1KB'
http-errors用于创建HTTP错误对象。它简化了处理HTTP请求时生成错误响应的过程。也可以和Express,Koa,Connect一起使用。用法如下:
var createError = require('http-errors')
var express = require('express')
var app = express()
app.use(function (req, res, next) {
if (!req.user) return next(createError(401, 'Please login to view this page.'))
next()
})
iconv-lite用于处理字符编码的转换。可以在不同的字符编码之间进行转换。
const iconv = require('iconv-lite');
const originalText = '你好,世界!';
// 将文本编码为 Buffer
const encodedBuffer = iconv.encode(originalText, 'utf-8');
// 将编码后的 Buffer 解码为文本
const decodedText = iconv.decode(encodedBuffer, 'utf-8');
unpipe用于取消可读流(Readable Stream)和可写流(Writable Stream)之间的数据传输。例如从文件读取流到HTTP响应流。unpipe库允许你取消这种数据传输。
getRawBody是入口函数,我们一起看一下:
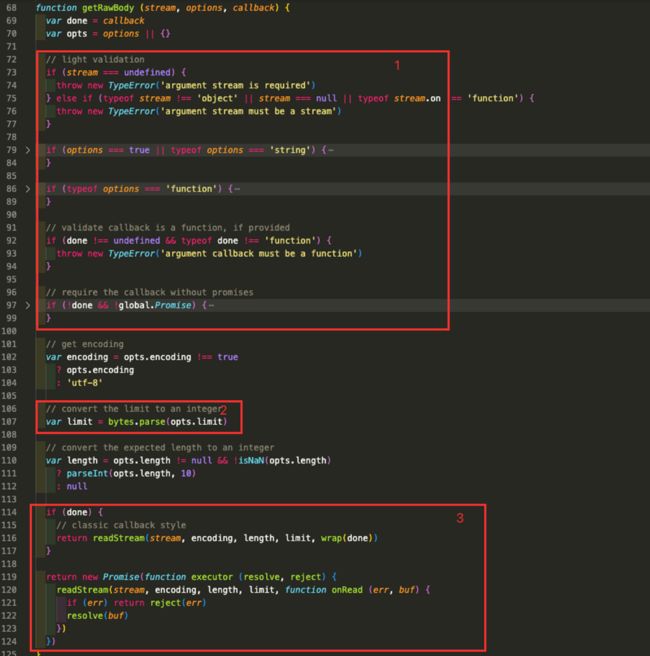
- 针对参数做一些验证以及错误处理
- 调用
bytes模块的parse方法解析传入的limit参数 - 调用
readStream函数处理stream,这里做了判断,如果传入了回调函数,则使用回调的方式传递解析之后stream,否则使用promise风格来处理
readStream函数和v0.0.3版本的代码变化不太大:
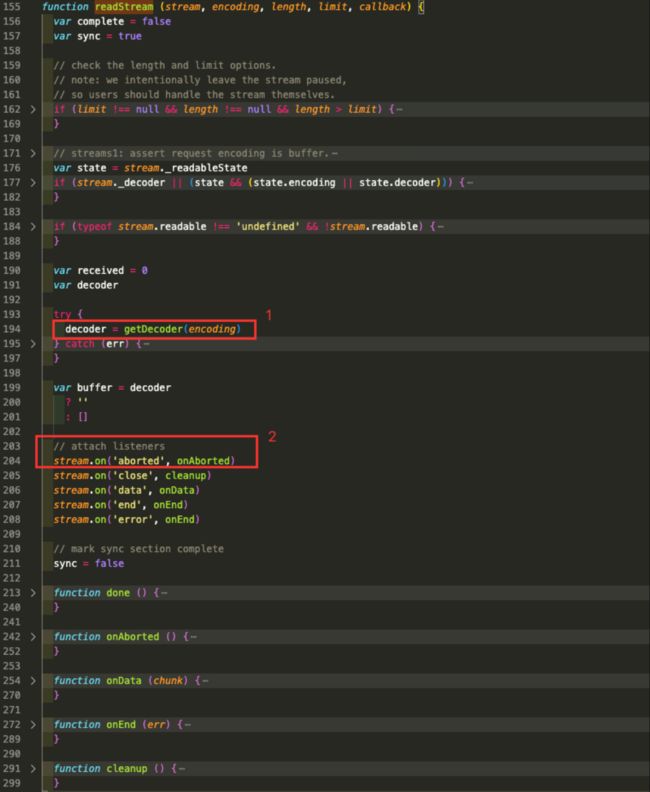
- 调用
getDecoder函数,用于获取指定编码的解码器。而getDecoder函数里面又调用了iconv模块的getDecoder方法 - 监听
stream的aborted事件,当客户端中止 HTTP 请求时,可读流会触发aborted事件。比如在请求尚未完成时客户端提前关闭了连接。
onAborted函数如下:
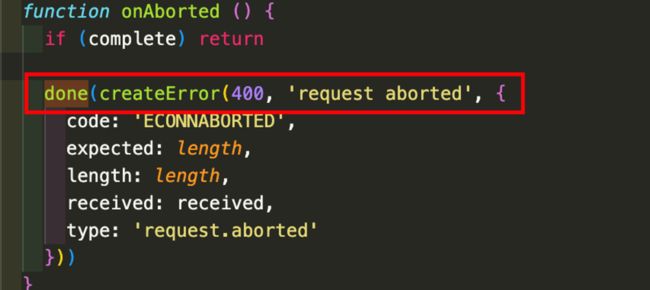
核心逻辑就是调用createError创建一个错误信息,然后调用done函数。
done函数是readStream里面需要重点关注的函数,代码如下:
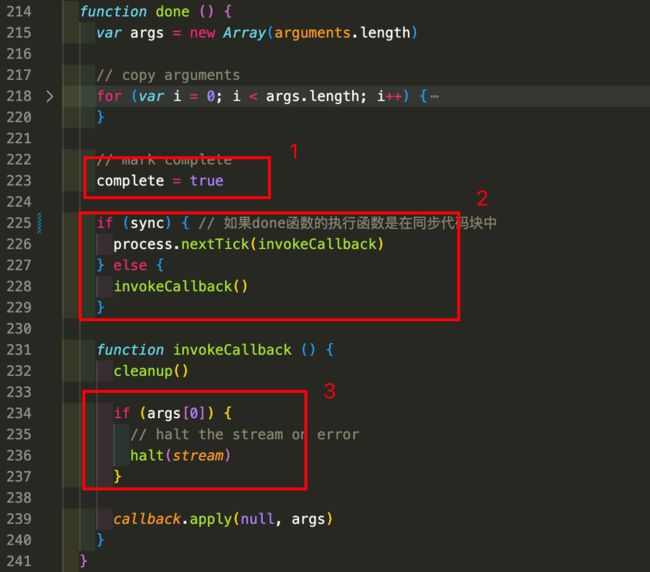
1,将complete标记为true,表示这个流已经处理完了。
2,判断done函数的调用环境,如果是在同步代码块,则使用process.nextTick延迟invokeCallback函数的调用。
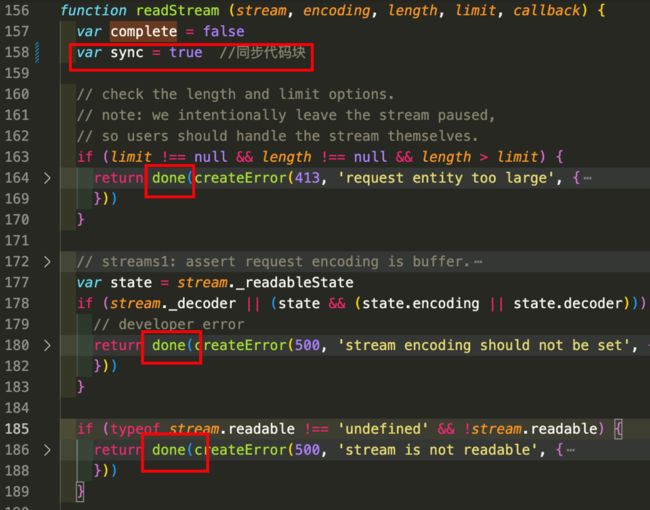
done函数同步调用是在这几个地方:
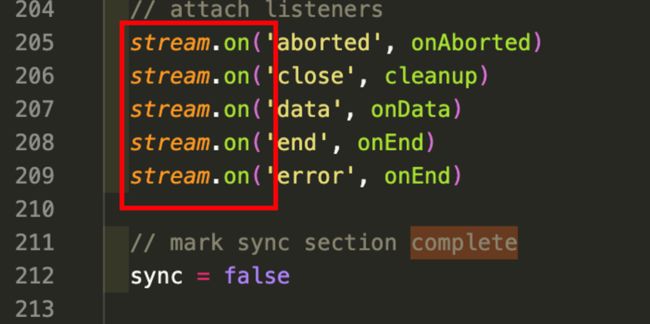
异步调用则是在stream.on事件的几个回调函数中,并在212行标记为异步:
3,根据done函数第一个参数判断是否有错误,如果有错误则调用halt方法处理stream,halt 方法会提前结束stream的读取操作。
halt函数内容如下:
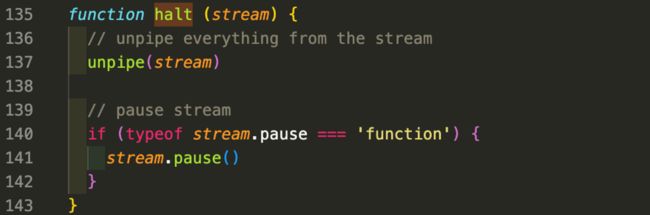
unpipe(stream) 会断开与这个流相关的其他管道,如果有其他流正在处理 stream 输出的数据,这些流不会收到来自 stream 的数据。
pause 方法是 Nodejs 可读流的一个方法,用于将流暂停,停止触发 data 事件,不再传递数据。
总结
本文我们了解了raw-body的简单使用,raw-body模块也是Nodejs生态中使用的很频繁的一个模块,通过对v0.0.3和v2.5.2版本源码的解析,也了解了内部实现。
参考资料
https://github.com/stream-utils/raw-body
https://nodejs.cn/dist/latest-v18.x/docs/api/stream.html
https://nodejs.cn/dist/latest-v18.x/docs/api/buffer.html
